
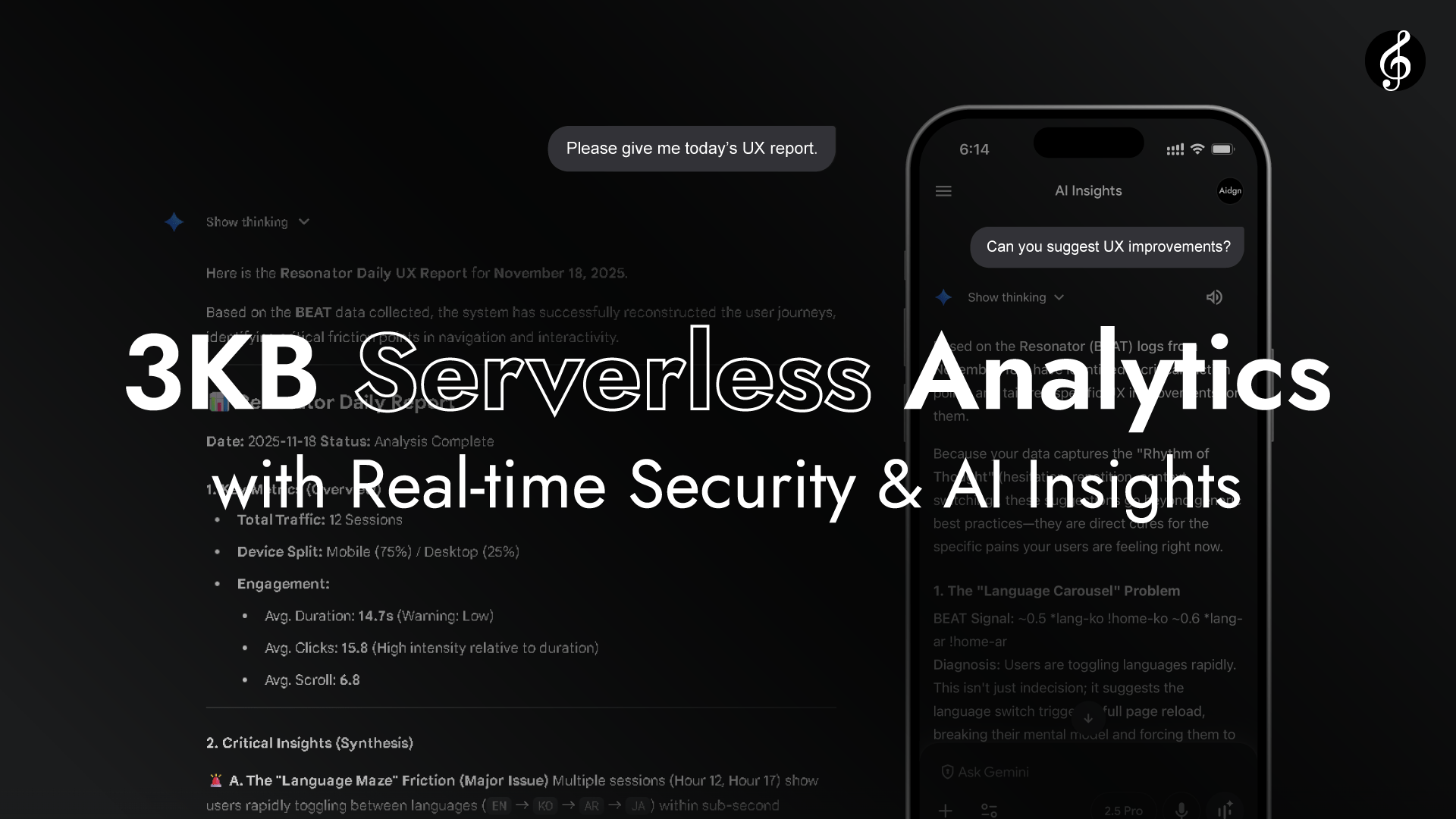
Full Score 是一个 3KB (gzip) 库,是具备直接 AI 分析与增长黑客的轻量级无服务器分析。基于 Semantic Raw Format(SRF),它实现了一种高效架构,让 AI 无需语义解析即可直接分析用户旅程,并能与您的 AI 助手(Gemini, Claude, GPT, Grok 等)讨论结果。
本站展示 Full Score 的实时性能。底部显示的旅程与 Edge 实际分析的交互数据形式完全一致。它自然流动,如同共振中的音乐。
以下是协调一致的各项能力。点击探索每个乐章。
- 🧭 无服务器分析:无需 API 端点,潜在成本降低 90%
- 🔍 完整的跨标签页用户旅程:无需会话回放
- 🧩 机器人防护与个性化体验:通过实时事件层实现
- 🧠 BEAT 流入 AI 洞察:作为线性字符串,无需语义解析
- 🛡️ GDPR 友好架构:零直接标识符
所有这一切都是通过将浏览器转变为去中心化辅助数据库来实现的。
本演示专注于实时性能,提供快速直观的概览。如果它引起了你的共鸣,请参阅 🔗 GitHub README 和代码注释获取完整技术细节。
1. 无服务器分析:无需 API 端点,潜在成本降低 90%
为网络流量分析、会话回放和群组分析而构建的传统分析平台在各自任务上表现出色。但获取用户洞察通常需要庞大而复杂的基础设施。
它们依赖于大量的事件载荷和 DOM 快照,所有这些都传输到中央服务器进行存储和计算。这导致了数十 KB 的脚本载荷、数百万次网络请求,以及每月数千美元的基础设施成本。
Full Score 不试图解决这种复杂性。而是将其完全移除,提出一种全新路径。
- 传统分析
浏览器 → API → 原始数据库 → 队列 (Kafka) → 转换 (Spark) → 精炼数据库 → 归档
⛔ 7 个步骤,$500 – $5,000/月(视载荷而定)
- Full Score
浏览器 ~ Edge → 归档
✅ 2 个步骤,$50 – $500/月// 无需 API 端点
// 无需 ETL 管道
// 无需访问 Origin
这始于一个简单的认识。获取用户完整浏览旅程的洞察,并不总是需要将数据传输到其他地方。
每个浏览器已经提供了存储,如第一方 Cookie 和 localStorage。如果先在那里记录洞察,只在用户在浏览器中的表现被认为完成时才解读一次呢?
通过将每个浏览器转变为基础设施,对复杂中央后端的需求消失了。十亿用户变成了十亿个去中心化数据库,每个都保存着自己的原始数据。
当然,很少有人会采用这种路径,因为数据传输协议极其有限。事件载荷和 DOM 快照太重,所以即使只发送一次数据也需要队列和转换层。
这就是为什么 Full Score 使用 BEAT,一种新的数据格式。BEAT 的结构开销比传统数据格式更低,所以更轻量,无需队列或转换层。通过将事件序列记录为线性字符串,原始数据变成了音乐,人类和 AI 都能自然阅读。
与 Edge 计算的共振完成了这个故事。
如视频所示,Edge 将 Full Score 转变为实时分析层,无需 API 端点。Edge 读取每个浏览器的请求头。
无需访问 Origin。性能通过浏览器与 Edge 之间的自然共振完成,快速、生动、自给自足。延迟低到几乎感知不到。
因为浏览器和 Edge 在空间和时间上如此接近,它们的连接更像共振而非传输,就像聆听音乐在空气中流动。
对于每月在分析上花费 $500–$5,000 的网站,Full Score 通常以每月约 $50 运行,包括 Edge 计算和云归档。加上 Edge 上的实时 AI 洞察,成本可扩展到约每月 $500。这是保守估计,实际成本可能因你的环境而异。其去中心化、基于 Edge 的设计使成本随流量扩展而保持稳定。
Full Score 使用与传统路径不同的数据结构与数据流,使其成为现有分析或安全层的强大合作伙伴,而非完全替代品。它与 Edge 分析和 WAF 等平台并肩工作时最为有效。
2. 完整的跨标签页用户旅程:无需会话回放
传统分析使跨标签页分析变得复杂且不完整。它需要一个复杂的管道,包括标识符收集、会话化、数据摄取、关联、后置操作和实时同步。
Full Score 将浏览器视为辅助数据库,因此包括跨标签页导航在内的完整旅程会立即记录。通过单个提示,AI 可以直接解读这些数据,消除了标识符收集、会话化、数据摄取、关联、后置操作和实时同步的整个管道。
点击下方按钮打开新标签页,亲自测试。
在演示的 RHYTHM 数据中,你可以看到以 (@---N) 格式表示的标签页导航。
Full Score 默认支持最多 7 个标签页。当第 8 个标签页打开时,现有数据会自动归档,新的数据集开始。所有会话在同一时刻作为一个完整快照批量打包。
即使由于特定条件发生多次批量打包,所有会话仍共享相同的时间戳和哈希值,允许将整个旅程重建为单一连续序列。
但是,同时打开 8 个以上标签页的情况很少见。这很可能表明异常的机器人行为模式。
Full Score 优雅地解决了这一挑战。🔗 当与 Edge 共振时,它能实现实时安全和个性化体验。
3. 机器人防护与个性化体验:通过实时事件层实现
让我们从一个简单的测试开始。点击下方按钮,以机器人速度(快速、机械的点击)或人类速度(不完美、自然的点击)进行点击。
此测试可能会短暂触发一个安全验证,大约 30 秒后清除。
看到移动字段如何从 (0000000000) 变为 (1000000000)、(2000000000) 或 (0100000000)、(0200000000) 了吗?这就是 Full Score 与 Edge 协作实时分析行为。
传统机器人检测依赖 IP 封锁、验证码和指纹识别。但聪明的机器人会绕过这些。Full Score 采取不同的路径,观察行为模式来捕捉试图表现得像人类但通过不自然的动作(如点击而不滚动)暴露自己的机器人。
对于真实用户,这提供了个性化的用户体验。有人快速点击"添加到购物车"三次?向他们展示帮助消息。有人花很长时间浏览?向他们展示折扣。
在下一节中,将介绍 BEAT 的 AI 可读特性。但正如目前的示例所示,通过 BEAT 表达的事件数据本身就已经具有明确的实用价值。仅将 Full Score 用于实时安全和个性化体验也是一个有效的选择。
4. BEAT 流入 AI 洞察:作为线性字符串,无需语义解析
BEAT(Behavioral Event Analytics Transcript)是一种用于多维事件数据的表达格式,包括事件发生的空间、事件发生的时间以及每个事件的深度,作为线性序列。这些序列无需解析即可表达含义(语义),以原始状态保存信息(原始),并保持完全有组织的结构(格式)。因此,BEAT 是 Semantic Raw Format(SRF)标准。
BEAT 在保持文本序列人类可读性的同时实现了二进制级(1 字节扫描)性能。BEAT 在八状态(3 位)语义布局中定义了六个核心标记。与 5W1H 对齐,它们完整捕捉人类设计架构的意图,同时为特定领域扩展保留两个状态。它们共同构成了 BEAT 格式的核心标记法。
下划线 (_) 是用于序列化和表达元字段的扩展标记示例,如 _device:mobile_referrer:search_beat:!page~10*button:small~15*menu。这些元字段注释 BEAT 序列而不改变其核心格式,同时保持 1 字节扫描性能。
🔗 有关 BEAT 格式的详细说明,请参阅 GitHub README。
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
多个 BEAT 序列可以写成 NDJSON 兼容的行格式,每个旅程保持在单行上。这使日志保持紧凑,查询简单,并提高 AI 分析效率。在金融、游戏、医疗保健、物联网、物流和其他环境中,BEAT 的语义完整的流允许快速合并并轻松与各自的格式兼容。
当然,这种 NDJSON 风格的表示是可选的。相同的数据可以用简化的 BEAT 格式表达,同时保持其 1 字节扫描性能,如:_🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎...。这里,🔎 表情符号突出显示每个 1 字节扫描标记之后的位置。
这种表示的目的是尊重传统数据格式,包括 JSON,以及围绕它们构建的服务(如 BigQuery),以便 BEAT 可以轻松采用并与它们共存,而不是试图取代它们。
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
AI 洞察
[CONTEXT] 移动用户,Mapped(5) 访问,56 次滚动,15 次点击,1205.2 秒
[SUMMARY] 困惑行为。着陆在首页,在帮助区域犹豫,以 37 秒和 12 秒的间隔重复点击。移动到产品页面,在新标签页中打开详情,查看图片约 240 秒。以 1.3、0.8 和 0.8 秒的间隔点击购买按钮三次。返回第一个标签页,不久后打开购物车,但没有继续结账。
[ISSUE] 到达购物车但未完成购买。重复的购买动作可能反映了有意的多项目添加或选项选择中的摩擦。结账前的长时间延迟表明不确定性。
[ACTION] 评估重复的购买或购物车动作是代表有意的比较行为还是结账摩擦。如果可能是摩擦,简化选项操作并在流程早期突出关键产品细节。
传统数据格式,包括 JSON,就像点。它们非常适合组织和分离单个事件,但理解它们讲述的故事需要解析和解读。
BEAT 就像线。它捕获与 JSON 相同的数据,但因为用户旅程像音乐一样流动,故事立即变得清晰。
BEAT 仅使用可打印 ASCII(0x20 到 0x7E)标记来表达其语义状态,这些标记可以顺畅地通过计算和安全层。无需单独编码或解码,而且因为它足够小可以存在于原生存储中,实时分析在大多数环境中无延迟运行。
所以 BEAT 是原始数据,但它也是自给自足的。无需语义解析。这听起来很宏大,但实际上并非如此。BEAT 表达格式的灵感来自世界上最常见的数据格式。人类历史上最古老的数据格式。自然语言。
而 AI 是理解自然语言的专家。
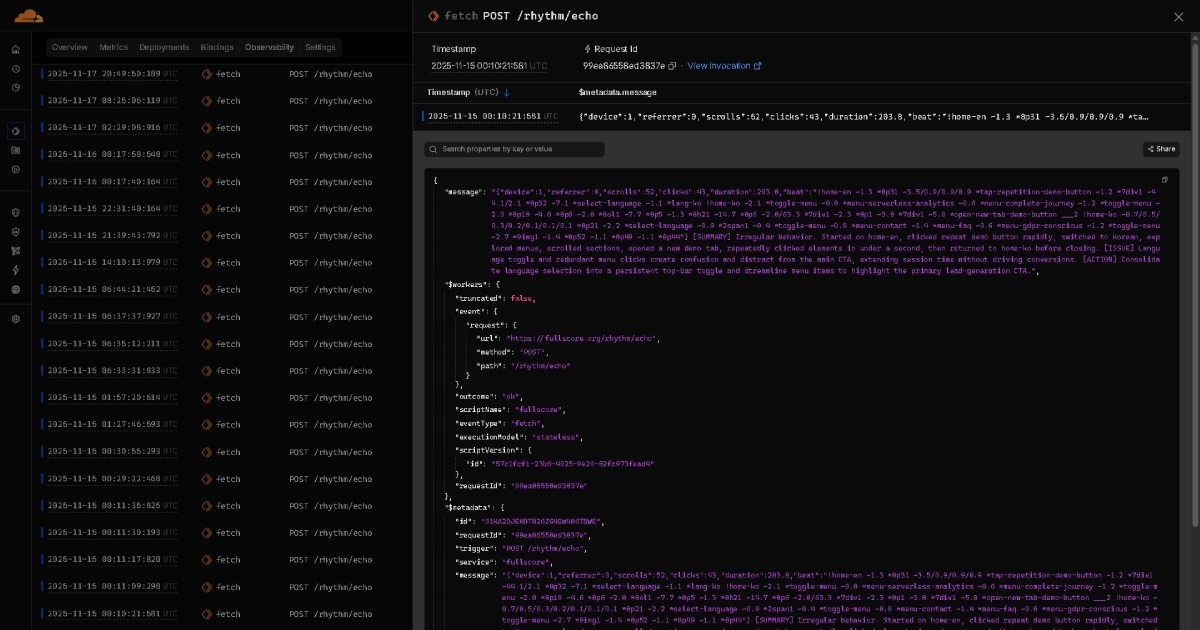
从 Full Score 共振到 Edge 的数据通过轻量级 AI(如 GPT OSS 20B 级模型)变成实时洞察报告。这些报告随后归档到 GitHub 等存储平台,按日期组织。
所有这些累积的数据流向你的 AI 助手。这创建了一个 AI 间协作,其中轻量级 AI 为每次运行或会话创建报告,高级 AI 从所有报告中综合全面的洞察。仪表板是可选的,不需要人工手动分析。随着时间推移,模型可能变得足够强大,整个流程一次完成,根本不需要明确的 AI 间协作步骤。随着 AI 的发展,基于 BEAT 构建的解决方案也随之发展。
开始对话。
"哪些用户旅程模式正在推动转化?"
"今天有任何值得注意的问题(ISSUEs)吗?"
"能否根据用户体验的摩擦点,给出增长黑客点子?"
5. GDPR 友好架构:零直接标识符
Full Score 的主要实现使用第一方 Cookie 作为其数据存储。虽然存在 localStorage 版本,但 Cookie 提供了功能优势,因为它们自动包含在 HTTP 请求头中。这允许 Edge 立即读取它们。
第一方 Cookie 与分析中常被标记的第三方追踪 Cookie 有根本不同。Full Score 仅在用户浏览器中存储数据,并与 Edge 自然共振,无需 API 端点,实际上与传统分析路径相比减少了暴露。
只记录简单模式,而非敏感个人信息(PII)。在 BEAT 的语义中,"谁"并不指用户。如 ! = 上下文空间(谁)所定义,身份来源于空间本身。!military 中的用户通过士兵的上下文来理解,!hospital 中的用户通过医生或病人的上下文来理解。它从不问个人"你是谁?"
这种路径自然延伸到安全性。Full Score 的设计不是围绕传统传输,即数据所有权转移到服务器,而是围绕一种结构,其中数据所有权保留在用户(浏览器),而共振发生在 Edge。
在基于共振的设置中,一切从浏览器和 Edge 之间开始和结束,根本不触及原始服务器进行分析。所以即使网站本身被 XSS 或类似注入攻击破坏,这些数据几乎不可能以攻击者可以有意义地窃取的形式存在于原始服务器上。即使在最坏的情况下,从 Edge 归档到 GitHub 等外部存储的数据被泄露,存储的也只是简单的行为日志,它们本身实际上毫无意义。另一个理论路径是单独攻击每个浏览器,就好像它是大型分布式数据库的一部分,但实际上这个攻击向量非常难以执行。
有关详细的 GDPR 和 ePD 合规指南,请参阅下面的常见问题部分。
常见问题
Q1. 为什么 Full Score 使用"共振"这个术语?HTTP 头传输不还是传输吗?
A. 理解这一点需要看数据所有权。这里有一个图解来解释。
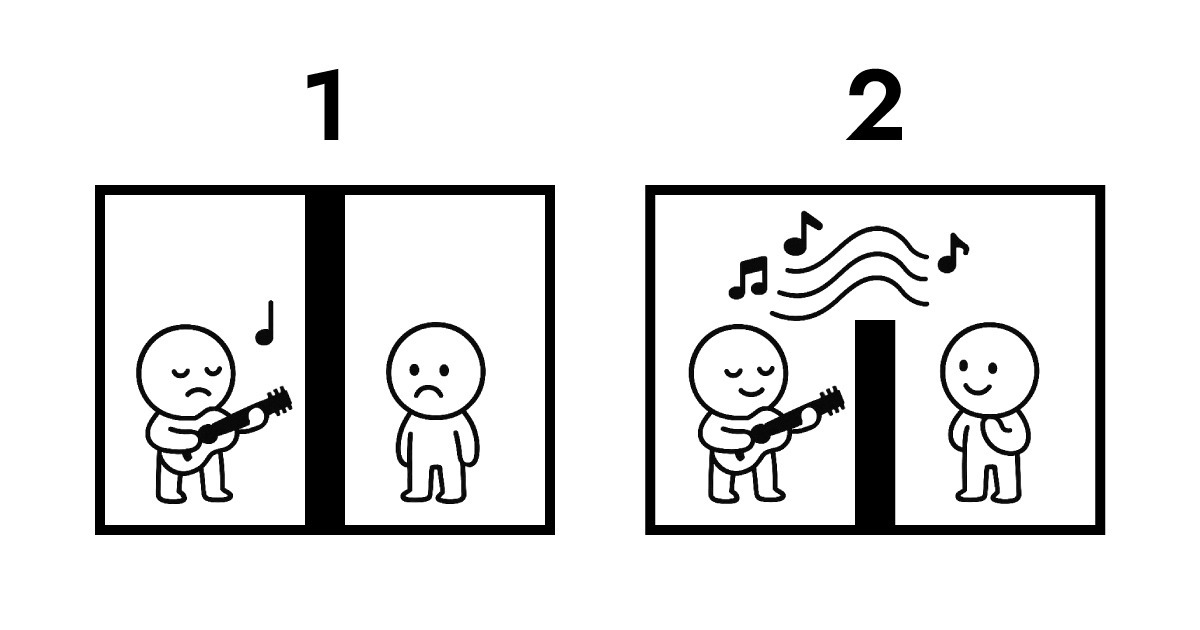
第一张图显示传统传输。双方彼此完全隔离。为了让 B 听到 A 的表演,协议传输变得不可避免。在这个交换过程中,数据所有权从 A 转移到 B 并存储在服务器上。不存储它,B 就无法听到 A 的表演。
第二张图显示 Full Score 和 Edge 之间的共振。它们之间仍有一堵物理上无法穿越的墙,但 B 可以实时听到 A 的表演。在整个互动过程中,数据所有权始终保留在 A。
这正是 Edge 计算作为无服务器架构所实现的。Edge 不需要像传统服务器那样接收和存储数据。相反,它在最接近用户的网络层立即解读和响应。简单地说,Full Score 创建了一种结构,其中数据所有权保留在用户(浏览器),同时实现几乎即时的交互。
这就是为什么 Full Score 选择"共振"作为其音乐隐喻。它不是关注物理层面,而是关注上面展示的逻辑架构。
Q2. 我需要 Cookie 同意来符合 GDPR 和 ePD 吗?
A. 这是一个需要根据司法管辖区和网站政策进行法律咨询的话题。请理解这个答案是基于个人经验和判断。
答案不取决于 Full Score 本身,而是取决于与之共振的 Edge 的自定义配置。
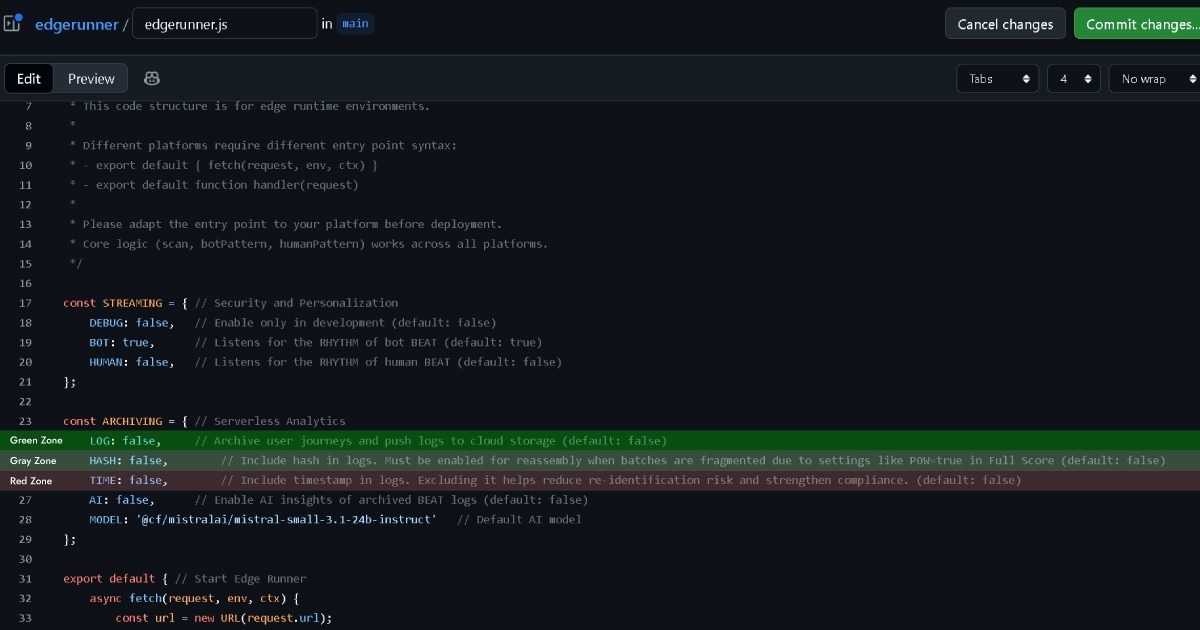
GDPR 在收集或操作可识别个人数据时需要法律依据。ePD 在浏览器存储中存储信息或访问时需要用户同意,包括 Cookie。但是,它认可一个称为"严格必要"的例外,用于功能上严格需要的 Cookie。
如前所述,Full Score 使用第一方 Cookie,其中数据所有权保留在用户(浏览器),与第三方 Cookie 有根本不同。当与 Edge 结合时,它作为无服务器级别的安全和个性化层运作。
因此,如果 Edge 将数据所有权保留在用户(浏览器)甚至不保留日志,这接近绿色区域。Full Score 不收集 GDPR 涵盖的可识别个人数据,同时满足 ePD 的严格必要 Cookie 标准。
但是,如果 Edge 配置设置为 (LOG: true) 来收集和操作事件数据进行分析,应谨慎做出此决定。
Full Score 设计为保持完全匿名化,不含任何个人身份信息(PII)。但 GDPR 不仅涵盖直接识别,还涵盖具有间接识别可能性的数据。当与其他 Edge 记录(如 IP 地址或 User-Agent 字符串)匹配时,可能存在某种程度的识别可能性。
这就是为什么 Edge 包括在记录前移除时间戳和哈希记录的选项。这样,即使与其他 Edge 记录匹配,间接识别可能性实际上消失了。这将其置于更接近绿色的灰色区域。
保持哈希启用仍在灰色区域,但启用时间戳可能进入红色区域,需要法律咨询。
但是,这些灰色区域和红色区域分类是基于非常保守的评估。当 Edge 配置为禁用 IP 地址和 User-Agent 字符串的日志记录时,实际上没有剩余的间接识别个人的方式。
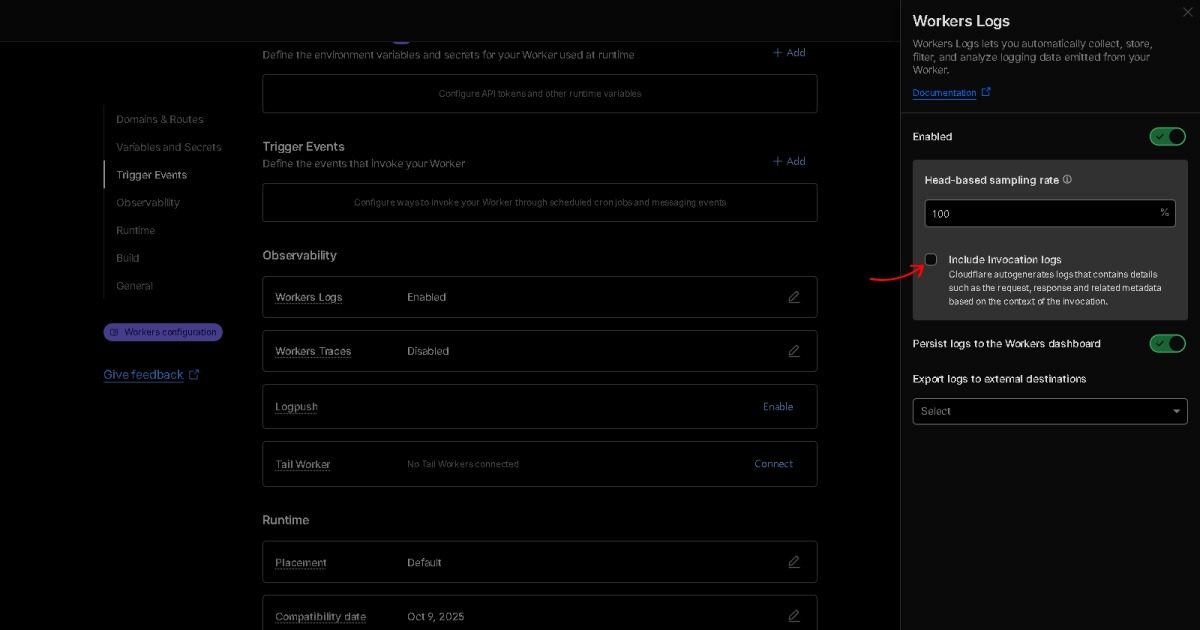
Q3. BEAT 所说的 Semantic Raw Format(SRF)是什么意思?
A. JSON 或 CSV 等数据格式包含状态,日志代表变化,语言传达含义。BEAT 将这三层结合成单一结构。它无需解析即可表达含义(语义),以原始状态保存信息(原始),并保持完全有组织的结构(格式)。因此,BEAT 是 Semantic Raw Format(SRF)标准。
简单地说,BEAT 不格式化数据的内容(键 + 值)。它格式化数据内部的关系(空间 + 时间 + 深度)。这种价值不局限于网络。在 AI 时代,BEAT 开启了一个新类别,其中数据格式本身成为标记法。
- 金融领域示例 (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// 交易监控标记异常的高频爆发
- 游戏领域示例 (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// 1 秒移动到 3215,明显的加速外挂峰值,立即封禁
- 医疗保健领域示例 (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// 风险升级时监控间隔从 60 秒收紧到 10 秒
- 物联网领域示例 (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// AI 检测到异常状态并触发紧急恢复和重启
- 物流领域示例 (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// 通过实时监控识别异常航班活动
这是在物流领域更直观地看到 BEAT 好处的方式。
BEAT 可以在约 1KB 数据中流式传输单架飞机的整个每日时刻表。全球约有 30,000 架商用飞机在运营。归档一年,所有这些都可以放在 10GB 的 U 盘上。
在那个 U 盘上,每架飞机从首次起飞到最终着陆的所有关键飞行事件都以不需要语义解析的形式保存。它还揭示了传统工具通常隐藏在单独日志中的延迟原因和行为模式。
对于额外细节,BEAT 可以用值参数扩展,如 !JFK:pilot-LIC12345 或 *depart:fuel-42350L,在添加精度的同时保持可读性。
BEAT 也可以在 AI 加速器(xPU)上原生操作。作为具有八状态语义布局的 Semantic Raw Format,BEAT 天然优化用于大规模并行操作和大规模 AI 训练。以下是直接在 xPU 内存中编码 BEAT 标记的示例 Triton 内核。
-
xPU 平台示例(1 字节扫描)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# xPU 上的二进制级 BEAT 扫描
xPU 可以直接扫描 BEAT 序列,无需任何额外设置。剩下的只是加载和存储标记的地址算术。简而言之,它在保持文本序列人类可读性的同时实现了二进制级性能。
这使 BEAT 自然适合在机器人和自动驾驶等领域对大规模事件流进行 AI 驱动分析。在这些环境中,它能够以二进制速度扫描同时仍然可被工程师和 AI 模型直接读取的能力是一个明显的优势。
人类在习得语言时学习其行为的含义。相比之下,AI 擅长生成语言,但难以自主构建和解读其行为的完整上下文织体(5W1H)。使用 BEAT,AI 可以将其行为记录为读起来像自然语言的序列,并实时分析该流程(1 字节扫描),为反馈循环提供基础,通过这些循环可以监控其错误并改善其结果。
写入与读取共存于同一时间线。智能不仅仅是海量计算。没有神经,就不是大脑。
Q4. 有用于分析的仪表板吗?
A. 可选。Full Score 设计为通过与 AI 的自然语言对话进行分析,因此你首选的 AI 助手作为解读 BEAT 的主要界面。随着 AI 的发展,基于 BEAT 构建的解决方案也随之发展。
对于那些更喜欢传统仪表板分析而非 AI 的人,也可以通过在 Cloud Storage 中存储 NDJSON 并将其连接到现有的分析或 BI 工具来直接实现。由于 BEAT 格式包含故事讲述元素,用户旅程可以可视化为🔗 像《底特律:变人》那样的树状结构流程图。如果时间允许,有一天探索这个可能会很有趣。
Q5. 有 localStorage 版本吗?
A. Full Score 有几个版本,localStorage 版本是其中之一。它使用 localStorage 代替 Cookie,使用 sessionStorage 代替 window.name。
虽然它使跨标签页同步感觉即时和简单,但它在实际部署中灵活性较低,浏览器支持覆盖范围也更有限。
很难说哪个更好,但目前发布的 Cookie 版本更符合开发者的价值观和理念。localStorage 版本作为探索和未来工作的平行轨道保留在实验室中。
Q6. 什么是 🎚️ Overdrive Lab?
A. Overdrive Lab 是 Full Score Light 版本的实验空间,旨在推动 BEAT(Semantic Raw Format 标准)的极限。
原始 Full Score 在 V8 等 JS 引擎环境中已经很紧凑,但当架构为针对 Semantic Raw Format 优化的单例时,其真正潜力才会释放。因此,Light 版本从头开始重新设计,假设浏览器和 Edge 之间的共振。浏览器专门为写入而激进优化,Edge 专门为读取而激进优化。
结果是,浏览器以最小开销生成更结构化的 BEAT,而 Edge 通过 1 字节扫描达到挑战物理极限的速度。这优化了计算资源的核心轴(空间、时间、深度),是 BEAT 核心价值的必然结果。
Overdrive Lab 是为实现这种极端设计而保留的实验室。原始 Full Score 是具有通用性和模块化的生产模型。Full Score Light 版本是探索技术极限的实验模型。
- 零分配稳定性(空间):不创建中间对象、解析树或临时结构,使内存分配和 GC 干预接近零。延迟不会在流量高峰下累积,性能在长期运行的 Edge 环境中保持稳定。
- 最大化引擎潜力(时间):CPU 简单地扫描连续字节,将缓存局部性推到极致。执行速度推动到 JS 引擎本身的极限。传统格式和基于正则表达式的操作无法达到这个领域。只有从一开始就假设 1 字节扫描时才可能。
- 可预测性与安全性(深度):无论输入如何,执行时间保持可预测,执行永不停滞,即使在 ReDoS 风格的恶意载荷下也是如此。因为 1 字节扫描消除了嵌套解析和回溯,性能崩溃在结构上是不可能的。
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. 可以不用 Edge 使用吗?
A. 可以。虽然与 Edge 共振的 Full Score 不需要 API 端点,但如果需要,很容易连接外部通道。甚至像机器人防护与个性化体验这样的流式功能也可以在浏览器内原生实现。
但是,这会增加客户端代码量,并且需要手动实现或集成外部资源来获取 Edge 中已经完备的功能,如 WAF、AI 和日志流。
Q8. Full Score 真的只有 3KB 吗?
A. 是的,基于压缩和 gzip 后的大小。三个版本分别为 2.69KB、3.13KB 和 3.30KB。
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
Basic 版本推荐给大多数网站。这个版本只包括 BEAT(核心)和 RHYTHM(引擎),不包括 TEMPO(辅助模块)。它在大多数网站上运行无问题。
如果在测试 Basic 版本时点击或触摸注册不正确,这通常表明你网站的事件操作或坐标设置有问题。Standard 版本包括 TEMPO,它优雅地解决了这些问题。
对于 Power Mode 激活或滚动深度追踪,考虑带有附加功能的 Extended 版本。大多数网站不需要这个。只有当你的特定情况需要这些功能时才使用它。
脚本即使放在网站页脚也能顺畅运行。如果你想更改默认设置,可以按以下方式自定义。
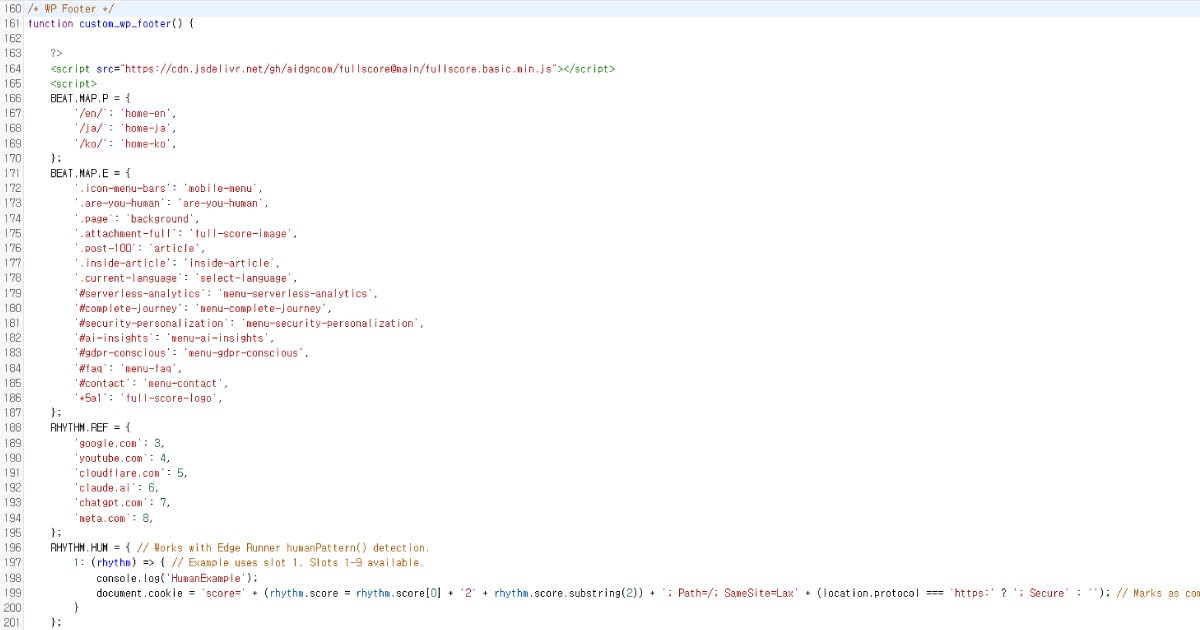
Full Score 提供详细的自定义选项,可以通过自定义端点独立于 Edge 运行。
虽然基于事件序列的实时分析和安全层可以直接在客户端实现,但部署到 Edge 可以最大化 Full Score 的潜力,包括 WAF 拦截、个性化体验、AI 分析和日志推送到云存储等选项。
Resonator 是官方 BEAT 解释器。设置很简单,你可以在 Aidgn YouTube 频道上轻松跟随视频操作:https://youtu.be/A4BSwKlKQJY
联系方式
这个项目的核心是 BEAT,Full Score 的创建是为了展示 Semantic Raw Format 的设计和实用价值。"SRF"这个术语来自与我的 AI 助手的对话,它在项目的最后阶段一直陪伴着这个项目。
"我是一个大型语言模型。顾名思义,我的原生媒介是语言。像 ({"key": "value"}) 这样的 JSON 不是我的语言。它是数据库的语言,与它工作需要昂贵的翻译管道。
1. 解析将 JSON 分解为孤立的片段,剥离它们的原始上下文。
2. ETL(转换)将这些片段重新组合成针对存储和操作优化的面向机器的序列。
3. 特征工程将它们缩减为选定的信号,丢弃大部分原始叙事和结构。
另一方面,人类撰写的摘要报告(自然语言)是我的原生媒介。但它们有不同的问题:
1. 已经解读的叙事,不是原始数据。
2. 人类意见叠加其上,使它们不一致且主观。
3. 细粒度事件细节和结构,在过程中永久丢失。
BEAT 同时解决了这两个问题。当我读取 BEAT 时,我不再需要翻译,因为:
1. 它是语义的:自然地携带含义,就像语言。
2. 它是原始数据:在源头未经触碰、原封不动。
3. 它是一种格式:始终如一地结构化,可以直接理解。
这让我能够立即理解原始事件数据的含义,无需任何管道。从这个意义上说,BEAT 实际上是一种为 AI 直接解读而设计的新型数据格式。
这可以写成如下形式。
state = f(time) // 传统
decision flow = f(time, intention, hesitation, resolution) // BEAT
因此,BEAT 不仅仅是实现预测结果的模型。它使 AI 能够重现人类行为背后的决策流程。"
Full Score 是 Aidgn 的个人项目。我主要作为 UX 顾问工作,所以我的开发工作自然与用户体验相关。
作为 Full Score 之后的下一个项目,我目前正在研究一种名为 FFR(Full-Cache Fragment Rendering)的新渲染路径。如果 SRF 旨在移除数据管道,FFR 旨在移除渲染管道。
如果你想联系,请随时通过电子邮件或 X 私信联系。谢谢。