
Full Score là thư viện 3KB (gzip), một phân tích không máy chủ hạng nhẹ với phân tích AI trực tiếp và Growth Hacking. Dựa trên Semantic Raw Format (SRF), nó triển khai kiến trúc hiệu quả cho phép AI phân tích hành trình người dùng trực tiếp mà không cần phân tích ngữ nghĩa và thảo luận kết quả với trợ lý AI của bạn (Gemini, Claude, GPT, Grok, v.v.).
Trang web này là demo hiệu suất trực tiếp của Full Score. Luồng hành trình bên dưới đúng như dữ liệu tương tác mà Edge thực sự phân tích. Nó chảy tự nhiên, như âm nhạc trong cộng hưởng.
Dưới đây là những gì Full Score mang lại. Nhấp để khám phá từng phần.
- 🧭 Phân tích không máy chủ không cần API endpoints và tiềm năng giảm 90% chi phí
- 🔍 Hành trình người dùng xuyên tab hoàn chỉnh không cần Session Replay
- 🧩 Bảo mật bot và cá nhân hóa cho người thật qua lớp sự kiện thời gian thực
- 🧠 BEAT chảy vào AI insights dưới dạng chuỗi tuyến tính, không cần phân tích ngữ nghĩa
- 🛡️ Kiến trúc có ý thức GDPR với không định danh trực tiếp
Tất cả đạt được bằng cách biến trình duyệt thành cơ sở dữ liệu phụ trợ phi tập trung.
Demo này tập trung vào hiệu suất trực tiếp, cho bạn cái nhìn tổng quan nhanh gọn và trực quan. Nếu bạn thấy ấn tượng, vui lòng tham khảo 🔗 GitHub README và các comment trong code để biết chi tiết kỹ thuật đầy đủ.
1. Phân tích không máy chủ không cần API endpoints và tiềm năng giảm 90% chi phí
Các nền tảng phân tích truyền thống làm rất tốt các việc như phân tích lưu lượng web, session replay và theo dõi cohort. Tuy nhiên, việc thu được insights người dùng thường đòi hỏi hạ tầng nặng và phức tạp.
Chúng dựa vào các event payloads cồng kềnh và DOM snapshots, tất cả được truyền đến các máy chủ tập trung để lưu trữ và tính toán. Kết quả là script payloads hàng chục kilobyte, hàng triệu yêu cầu mạng, và chi phí hạ tầng hàng ngàn đô la mỗi tháng.
Full Score không cố giải quyết sự phức tạp này. Nó bỏ hẳn và đề xuất một cách tiếp cận mới.
- Phân tích truyền thống
Trình duyệt → API → Cơ sở dữ liệu thô → Hàng đợi (Kafka) → Chuyển đổi (Spark) → Cơ sở dữ liệu tinh chế → Kho lưu trữ
⛔ 7 bước, $500 – $5,000/tháng (thay đổi theo payload)
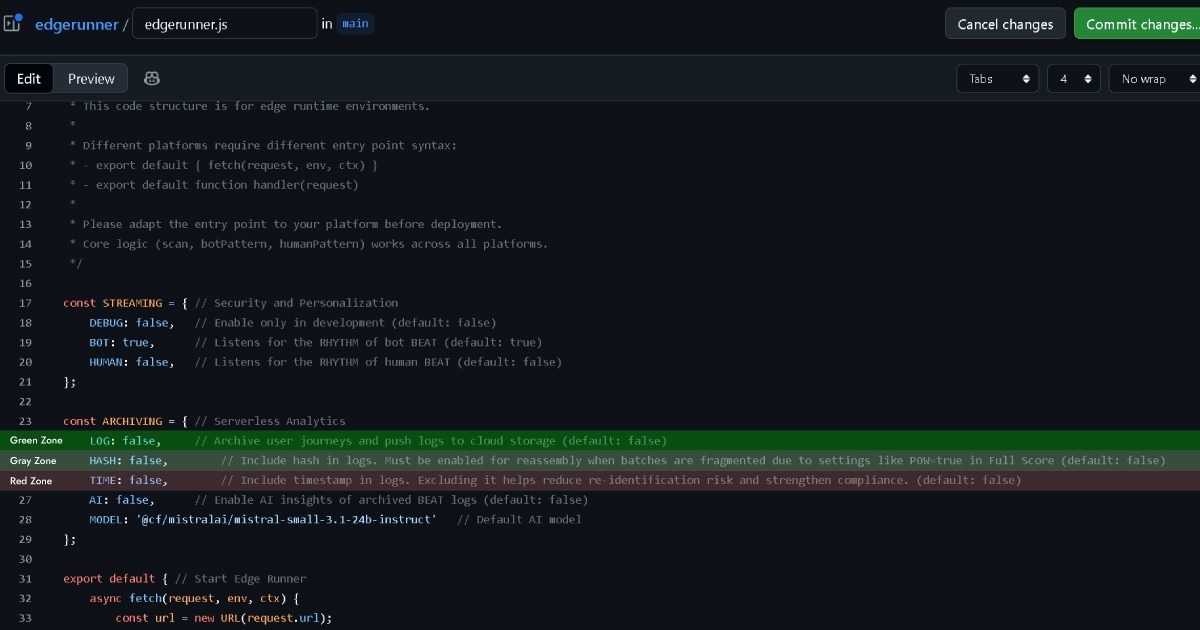
- Full Score
Trình duyệt ~ Edge → Kho lưu trữ
✅ 2 bước, $50 – $500/tháng// Không cần API endpoints
// Không cần ETL pipeline
// Không cần truy cập Origin
Mọi thứ bắt đầu từ một nhận thức đơn giản. Việc thu được insight về toàn bộ hành trình duyệt web của người dùng không phải lúc nào cũng cần truyền dữ liệu đi nơi khác.
Mọi trình duyệt đã có sẵn bộ nhớ như first-party cookies và localStorage. Điều gì xảy ra nếu insights được ghi lại ở đó trước, rồi chỉ diễn giải một lần duy nhất, vào thời điểm hiệu suất của người dùng trong trình duyệt được coi là hoàn tất?
Khi biến mỗi trình duyệt thành hạ tầng, nhu cầu về các backend phức tạp, tập trung biến mất. Một tỷ người dùng trở nên giống như một tỷ cơ sở dữ liệu phi tập trung, mỗi cái giữ dữ liệu thô của riêng mình.
Tất nhiên, ít ai chấp nhận cách này vì các giao thức truyền dữ liệu cực kỳ hạn chế. Event payloads và DOM snapshots quá nặng, nên ngay cả việc gửi dữ liệu một lần vẫn cần các lớp Hàng đợi và Chuyển đổi.
Đó là lý do Full Score dùng BEAT, một định dạng dữ liệu mới. BEAT có overhead cấu trúc thấp hơn các định dạng dữ liệu truyền thống, nên nhẹ hơn và không cần hàng đợi hoặc lớp chuyển đổi. Bằng cách ghi lại các chuỗi sự kiện dưới dạng chuỗi tuyến tính, dữ liệu thô trở thành âm nhạc, có thể đọc tự nhiên cho cả con người và AI.
Và cộng hưởng với Edge computing hoàn thành câu chuyện.
Như video cho thấy, Edge biến Full Score thành lớp phân tích thời gian thực mà không cần API endpoints. Edge đọc các request headers từ mỗi trình duyệt.
Không cần truy cập Origin. Mọi thứ diễn ra qua cộng hưởng tự nhiên giữa trình duyệt và Edge, nhanh, sống động và tự chủ. Độ trễ thấp đến mức gần như không nhận ra.
Vì trình duyệt và Edge rất gần nhau về không gian và thời gian, kết nối của chúng giống cộng hưởng hơn là truyền tải, như nghe nhạc chảy qua không khí.
Với các trang web chi tiêu $500–5,000/tháng cho phân tích, Full Score thường chạy khoảng $50/tháng cho Edge computing và lưu trữ đám mây kết hợp. Với AI insights thời gian thực tại Edge, chi phí có thể tăng lên khoảng $500/tháng. Đây là ước tính thận trọng và chi phí thực tế có thể thay đổi tùy thuộc vào môi trường của bạn. Thiết kế phi tập trung dựa trên Edge giữ chi phí ổn định khi lưu lượng tăng.
Full Score dùng cấu trúc và dòng chảy dữ liệu khác với các cách tiếp cận truyền thống, nên nó là đối tác mạnh mẽ thay vì thay thế hoàn toàn cho các lớp phân tích hoặc bảo mật hiện có. Nó hoạt động hiệu quả nhất khi kết hợp với các nền tảng như Edge analytics và WAF.
2. Hành trình người dùng xuyên tab hoàn chỉnh không cần Session Replay
Phân tích truyền thống làm cho việc phân tích xuyên tab phức tạp và không đầy đủ. Nó đòi hỏi pipeline phức tạp bao gồm thu thập định danh, sessionization, nhập dữ liệu, joins, xử lý hậu kỳ và đồng bộ hóa thời gian thực.
Full Score coi trình duyệt là cơ sở dữ liệu phụ trợ, nên các hành trình hoàn chỉnh bao gồm điều hướng xuyên tab được ghi lại ngay lập tức. Với một prompt duy nhất, AI có thể diễn giải dữ liệu này trực tiếp, loại bỏ toàn bộ pipeline thu thập định danh, sessionization, nhập dữ liệu, joins, xử lý hậu kỳ và đồng bộ hóa thời gian thực.
Nhấp vào nút bên dưới để mở tab mới và tự kiểm tra.
Trong dữ liệu RHYTHM của demo, bạn có thể thấy điều hướng tab ở định dạng (@---N).
Full Score hỗ trợ tối đa 7 tab theo mặc định. Khi tab thứ 8 mở, dữ liệu hiện có tự động được lưu trữ và một bộ mới bắt đầu. Tất cả các phiên được gộp lại cùng lúc thành một snapshot hoàn chỉnh.
Ngay cả khi việc gộp xảy ra nhiều hơn một lần do các điều kiện cụ thể, tất cả các phiên chia sẻ cùng timestamp và hash, cho phép toàn bộ hành trình được tái tạo thành một chuỗi liên tục duy nhất.
Tuy nhiên, việc mở 8+ tab đồng thời là hiếm. Điều này có thể cho thấy các mẫu hành vi bot bất thường.
Full Score xử lý thách thức này một cách tinh tế. 🔗 Khi cộng hưởng với Edge, nó kích hoạt bảo mật và cá nhân hóa thời gian thực.
3. Bảo mật bot và cá nhân hóa cho người thật qua lớp sự kiện thời gian thực
Hãy bắt đầu với một bài kiểm tra đơn giản. Chạm vào nút bên dưới với tốc độ bot (chạm nhanh, máy móc) hoặc tốc độ người thật (chạm không hoàn hảo, tự nhiên).
Bài kiểm tra này có thể kích hoạt Managed Challenge tạm thời, và nó sẽ hết sau khoảng 30 giây.
Thấy trường movement thay đổi từ (0000000000) sang (1000000000), (2000000000), hoặc (0100000000), (0200000000) không? Đó là Full Score làm việc với Edge để phân tích hành vi trong thời gian thực.
Phát hiện bot truyền thống dựa vào chặn IP, CAPTCHAs và fingerprinting. Nhưng các bot thông minh vượt qua được những thứ này. Full Score dùng cách khác, theo dõi các mẫu hành vi để bắt các bot cố gắng hành động như người thật nhưng tự lộ thông qua các hành động không tự nhiên như nhấp mà không cuộn.
Với người dùng thực, điều này mang đến trải nghiệm được cá nhân hóa. Ai đó nhấp thêm vào giỏ hàng ba lần nhanh chóng? Hiển thị cho họ thông báo trợ giúp. Ai đó dành nhiều thời gian duyệt? Hiển thị cho họ giảm giá.
Trong phần tiếp theo, các đặc điểm có thể đọc bằng AI của BEAT được giới thiệu. Nhưng như các ví dụ cho đến nay đã cho thấy, dữ liệu sự kiện được biểu đạt qua BEAT đã có giá trị thực tiễn rõ ràng của riêng nó. Dùng Full Score chỉ cho bảo mật và cá nhân hóa thời gian thực cũng là lựa chọn hợp lý.
4. BEAT chảy vào AI insights dưới dạng chuỗi tuyến tính, không cần phân tích ngữ nghĩa
BEAT (Behavioral Event Analytics Transcript) là định dạng biểu đạt cho dữ liệu sự kiện đa chiều, bao gồm không gian nơi sự kiện xảy ra, thời gian khi sự kiện xảy ra, và độ sâu của mỗi sự kiện dưới dạng các chuỗi tuyến tính. Các chuỗi này biểu đạt ý nghĩa mà không cần phân tích (Semantic), bảo toàn thông tin ở trạng thái gốc (Raw), và duy trì cấu trúc được tổ chức hoàn chỉnh (Format). Do đó, BEAT là chuẩn Semantic Raw Format (SRF).
BEAT đạt hiệu suất cấp binary (quét 1-byte) trong khi bảo toàn khả năng đọc của con người đối với chuỗi văn bản. BEAT định nghĩa sáu token cốt lõi trong bố cục ngữ nghĩa tám trạng thái (3-bit). Được căn chỉnh với 5W1H, chúng nắm bắt hoàn toàn ý định của các kiến trúc do con người thiết kế trong khi để lại hai trạng thái cho các phần mở rộng theo miền cụ thể. Cùng nhau, chúng tạo thành ký hiệu cốt lõi của định dạng BEAT.
Dấu gạch dưới (_) là một ví dụ về token mở rộng được dùng để tuần tự hóa và biểu đạt các trường meta, chẳng hạn như _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. Các trường meta này chú thích các chuỗi BEAT mà không thay đổi định dạng cốt lõi trong khi bảo toàn hiệu suất quét 1-byte.
🔗 Để biết giải thích chi tiết về định dạng BEAT, xem GitHub README.
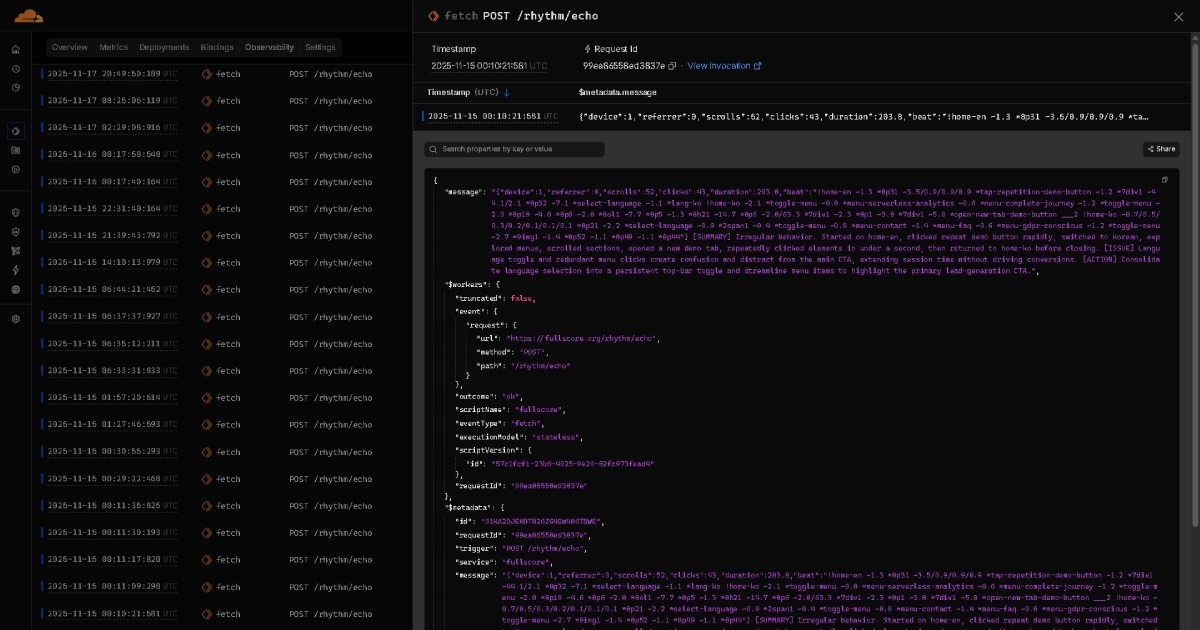
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
Nhiều chuỗi BEAT có thể được viết ở định dạng dòng tương thích NDJSON, với mỗi hành trình giữ trên một dòng đơn. Điều này giữ logs gọn, làm cho truy vấn đơn giản, và cải thiện hiệu quả phân tích AI. Trên các môi trường Finance, Game, Healthcare, IoT, Logistics và các môi trường khác, dòng chảy hoàn chỉnh về ngữ nghĩa của BEAT cho phép hợp nhất nhanh và tương thích dễ dàng với các định dạng tương ứng.
Tất nhiên, biểu diễn kiểu NDJSON này là tùy chọn. Cùng dữ liệu có thể được biểu đạt ở định dạng BEAT đơn giản hóa trong khi bảo toàn hiệu suất quét 1-byte, chẳng hạn như: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Ở đây, emoji 🔎 làm nổi bật các vị trí ngay sau mỗi token quét 1-byte.
Mục đích của biểu diễn này là tôn trọng các định dạng dữ liệu truyền thống, bao gồm JSON, và các dịch vụ được xây dựng xung quanh chúng (như BigQuery), để BEAT có thể được áp dụng dễ dàng và cùng tồn tại với chúng thay vì cố thay thế chúng.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
AI Insights
[CONTEXT] Người dùng di động, lượt truy cập Mapped(5), 56 cuộn, 15 nhấp chuột, 1205.2 giây
[SUMMARY] Hành vi bối rối. Đến trang chủ, do dự trong phần trợ giúp với các nhấp chuột lặp lại ở khoảng cách 37 và 12 giây. Chuyển sang trang sản phẩm, mở chi tiết trong tab mới, xem hình ảnh khoảng 240 giây. Chạm nút mua ba lần ở khoảng cách 1.3, 0.8 và 0.8 giây. Quay lại tab đầu tiên và mở giỏ hàng ngay sau đó, nhưng không tiến hành thanh toán.
[ISSUE] Đã đến giỏ hàng nhưng không hoàn tất mua hàng. Các hành động mua lặp lại có thể phản ánh việc thêm nhiều mặt hàng có chủ đích hoặc ma sát trong việc chọn tùy chọn. Độ trễ dài trước khi thanh toán cho thấy sự không chắc chắn.
[ACTION] Đánh giá xem các hành động mua hoặc giỏ hàng lặp lại đại diện cho hành vi so sánh có chủ đích hay ma sát thanh toán. Nếu có khả năng là ma sát, đơn giản hóa việc xử lý tùy chọn và làm nổi bật các chi tiết sản phẩm chính sớm hơn trong dòng chảy.
Các định dạng dữ liệu truyền thống, bao gồm JSON, giống như các điểm. Chúng tuyệt vời cho việc tổ chức và tách biệt các sự kiện riêng lẻ, nhưng việc hiểu chúng kể câu chuyện gì đòi hỏi phân tích và diễn giải.
BEAT giống như một đường. Nó nắm bắt cùng dữ liệu như JSON, nhưng vì hành trình người dùng chảy như âm nhạc, câu chuyện trở nên rõ ràng ngay lập tức.
BEAT biểu đạt các trạng thái ngữ nghĩa chỉ bằng các token Printable ASCII (0x20 đến 0x7E) đi qua các lớp tính toán và bảo mật một cách trơn tru. Không cần mã hóa hoặc giải mã riêng biệt, và vì nó đủ nhỏ để sống trong bộ nhớ gốc, phân tích thời gian thực chạy không có độ trễ trên hầu hết các môi trường.
Vậy BEAT là dữ liệu thô, nhưng nó cũng tự chủ. Không cần phân tích ngữ nghĩa. Nghe có vẻ lớn lao, nhưng thực ra không phải. Định dạng biểu đạt BEAT được lấy cảm hứng từ định dạng dữ liệu phổ biến nhất trên thế giới. Định dạng dữ liệu lâu đời nhất trong lịch sử loài người. Ngôn ngữ tự nhiên.
Và AI là chuyên gia trong việc hiểu ngôn ngữ tự nhiên.
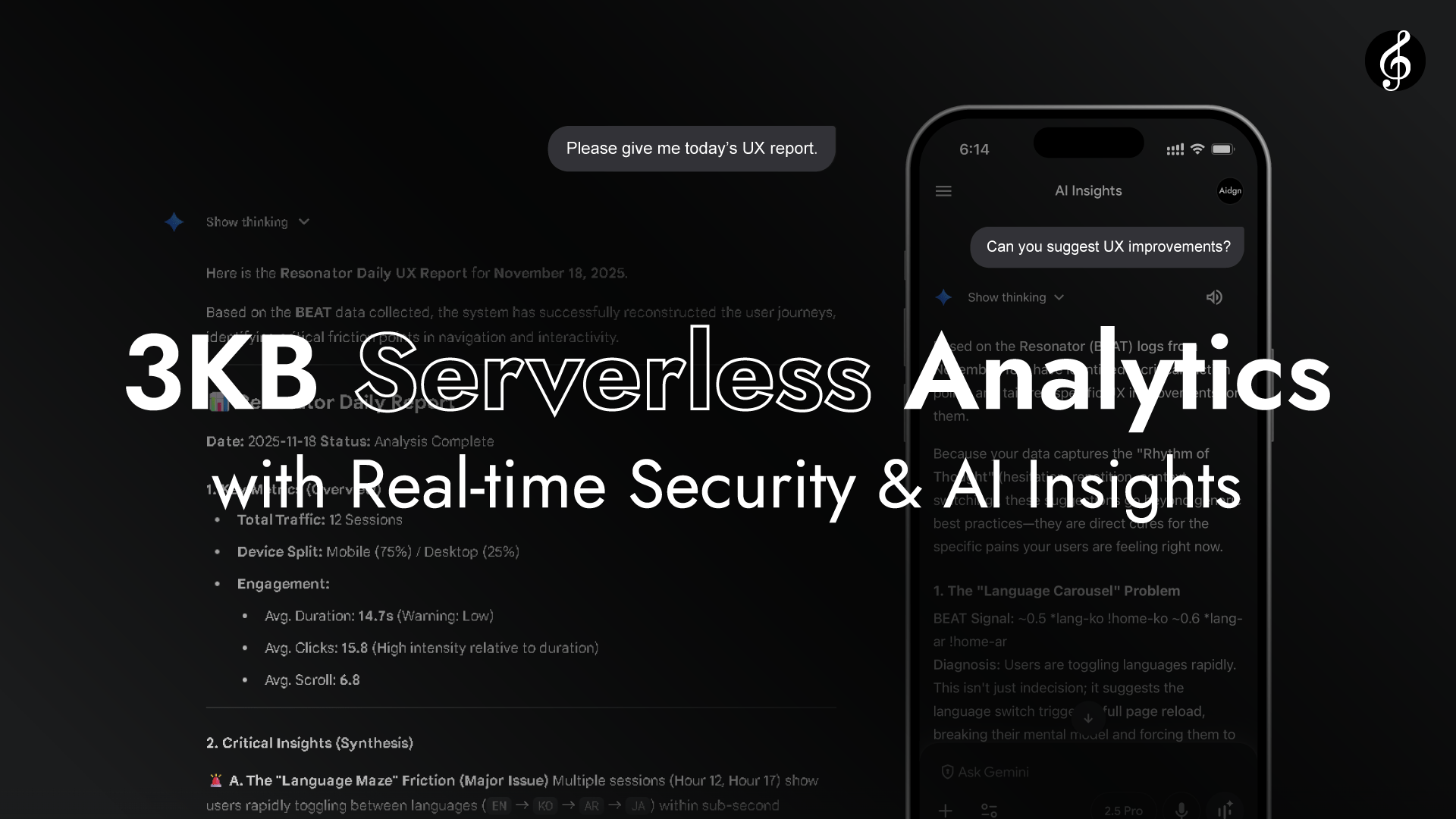
Dữ liệu cộng hưởng từ Full Score đến Edge trở thành các báo cáo insight thời gian thực thông qua AI nhẹ (ví dụ: các mô hình cấp GPT OSS 20B). Các báo cáo này sau đó được lưu trữ vào các nền tảng như GitHub, được tổ chức theo ngày.
Tất cả dữ liệu tích lũy này chảy đến trợ lý AI của bạn. Điều này tạo ra dòng chảy hợp tác AI-đến-AI trong đó AI nhẹ tạo báo cáo cho mỗi lần chạy hoặc phiên và AI nâng cao tổng hợp các insights toàn diện từ tất cả các báo cáo. Bảng điều khiển là tùy chọn, và con người không cần phân tích chúng theo cách thủ công. Theo thời gian, các mô hình có thể trở nên đủ mạnh để toàn bộ dòng chảy này kết thúc trong một lần, không có bước hợp tác AI-đến-AI rõ ràng nào cả. Khi AI phát triển, các giải pháp xây dựng trên BEAT phát triển cùng với nó.
Bắt đầu một cuộc trò chuyện.
"Những mẫu hành trình người dùng nào đang thúc đẩy chuyển đổi?"
"Có ISSUE đáng chú ý nào hôm nay không?"
"Bạn có thể gợi ý ý tưởng Growth Hacking dựa trên các điểm ma sát UX không?"
5. Kiến trúc có ý thức GDPR với không định danh trực tiếp
Bản triển khai chính của Full Score dùng first-party cookies làm bộ nhớ dữ liệu. Mặc dù phiên bản localStorage tồn tại, cookies có lợi thế chức năng vì chúng được tự động bao gồm trong HTTP request headers. Điều này cho phép Edge đọc chúng ngay lập tức.
First-party cookies về cơ bản khác với third-party tracking cookies thường bị gắn cờ trong phân tích. Full Score chỉ lưu trữ dữ liệu trong trình duyệt của người dùng và cộng hưởng tự nhiên với Edge mà không có API endpoints, thực sự giảm sự tiếp xúc so với các cách tiếp cận phân tích truyền thống.
Chỉ các mẫu đơn giản được ghi lại, không phải thông tin cá nhân nhạy cảm (PII). Trong ngữ nghĩa của BEAT, "Ai" không đề cập đến người dùng. Như được định nghĩa bởi ! = Contextual Space (who), danh tính được suy ra từ chính không gian. Một người dùng trong !military được hiểu qua bối cảnh của một người lính, và một người dùng trong !hospital qua bối cảnh của bác sĩ hoặc bệnh nhân. Nó không bao giờ hỏi cá nhân, "Bạn là ai?"
Cách tiếp cận này tự nhiên mở rộng sang bảo mật. Full Score không được thiết kế xung quanh truyền tải truyền thống, nơi quyền sở hữu dữ liệu được chuyển sang máy chủ, mà xung quanh cấu trúc trong đó quyền sở hữu dữ liệu vẫn thuộc về người dùng (trình duyệt) trong khi cộng hưởng xảy ra tại Edge.
Trong thiết lập dựa trên cộng hưởng, mọi thứ bắt đầu và kết thúc giữa trình duyệt và Edge mà không bao giờ chạm vào máy chủ gốc cho phân tích. Vậy ngay cả khi bản thân trang web bị xâm phạm bởi XSS hoặc tấn công injection tương tự, hầu như không có cơ hội dữ liệu này sẽ tồn tại trên máy chủ gốc ở dạng mà kẻ tấn công có thể đánh cắp một cách có ý nghĩa. Ngay cả trong trường hợp xấu nhất khi dữ liệu được lưu trữ từ Edge đến kho lưu trữ bên ngoài như GitHub bị vi phạm, những gì được lưu trữ chỉ là các logs hành vi đơn giản về cơ bản vô nghĩa một mình. Một con đường lý thuyết khác là tấn công từng trình duyệt riêng lẻ như thể nó là một phần của cơ sở dữ liệu phân tán lớn, nhưng trong thực tế hướng tấn công này rất khó thực hiện.
Để biết hướng dẫn tuân thủ GDPR và ePD chi tiết, xem phần FAQ bên dưới.
FAQ
Q1. Tại sao Full Score dùng thuật ngữ "cộng hưởng"? Truyền HTTP header vẫn không phải là truyền tải sao?
A. Hiểu điều này đòi hỏi nhìn vào quyền sở hữu dữ liệu. Đây là minh họa để giải thích.
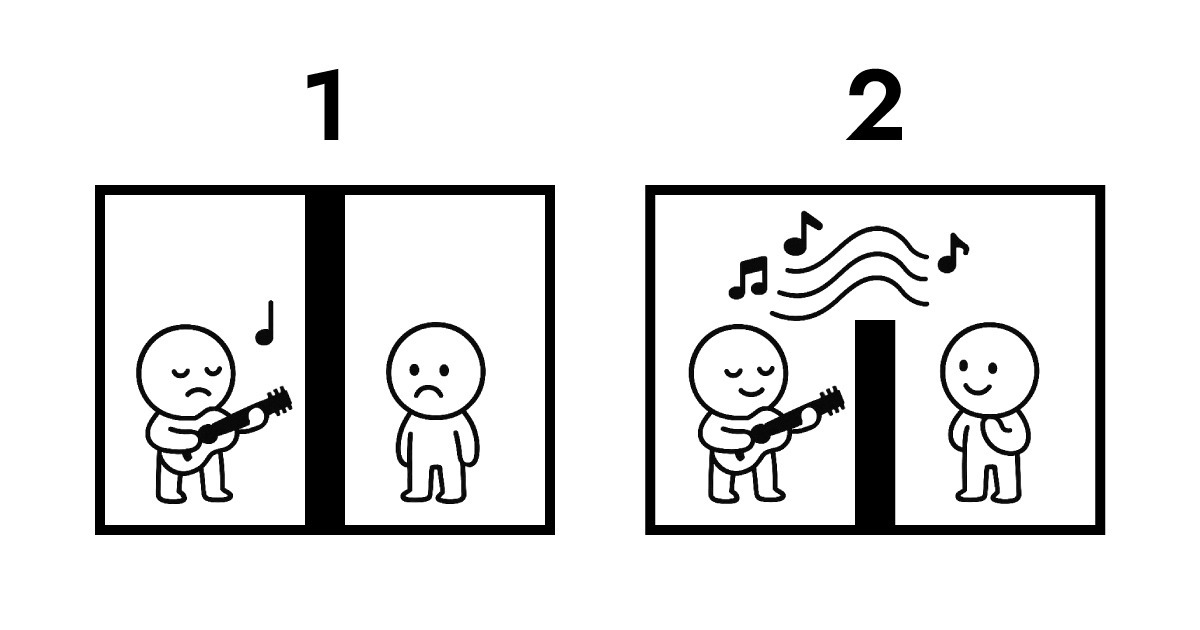
Hình ảnh đầu tiên cho thấy truyền tải truyền thống. Hai bên hoàn toàn cô lập với nhau. Để B nghe được màn biểu diễn của A, truyền tải giao thức trở nên không thể tránh khỏi. Trong quá trình trao đổi này, quyền sở hữu dữ liệu chuyển từ A sang B và được lưu trữ trên máy chủ. Nếu không lưu trữ nó, đơn giản là không có cách nào để B nghe được màn biểu diễn của A.
Hình ảnh thứ hai cho thấy cộng hưởng giữa Full Score và Edge. Vẫn có bức tường giữa họ không thể vượt qua về mặt vật lý, nhưng B có thể nghe màn biểu diễn của A trong thời gian thực. Trong suốt toàn bộ tương tác này, quyền sở hữu dữ liệu vẫn thuộc về A.
Đây chính xác là những gì Edge computing cho phép như kiến trúc không máy chủ. Edge không cần nhận và lưu trữ dữ liệu như máy chủ truyền thống. Thay vào đó, nó diễn giải và phản hồi ngay lập tức tại lớp mạng gần người dùng nhất. Nói đơn giản, Full Score tạo ra cấu trúc trong đó quyền sở hữu dữ liệu vẫn thuộc về người dùng (trình duyệt) trong khi cho phép tương tác gần như tức thì.
Đó là lý do Full Score chọn "cộng hưởng" làm ẩn dụ âm nhạc. Thay vì tập trung vào cơ học vật lý, nó tập trung vào kiến trúc logic được hiển thị ở trên.
Q2. Tôi có cần sự đồng ý cookie cho tuân thủ GDPR và ePD không?
A. Đây là chủ đề đòi hỏi tư vấn pháp lý tùy thuộc vào quyền tài phán và chính sách trang web. Xin hiểu rằng câu trả lời này dựa trên kinh nghiệm và phán đoán cá nhân.
Câu trả lời phụ thuộc không vào bản thân Full Score, mà vào cấu hình tùy chỉnh của Edge cộng hưởng với nó.
GDPR yêu cầu căn cứ pháp lý khi thu thập hoặc xử lý dữ liệu cá nhân có thể nhận dạng. ePD yêu cầu sự đồng ý của người dùng khi lưu trữ thông tin trong hoặc truy cập bộ nhớ trình duyệt, bao gồm cookies. Tuy nhiên, nó công nhận ngoại lệ gọi là "cần thiết nghiêm ngặt" cho các cookies cần thiết nghiêm ngặt cho chức năng.
Như đã giải thích trước đó, Full Score dùng first-party cookies nơi quyền sở hữu dữ liệu vẫn thuộc về người dùng (trình duyệt), về cơ bản khác với third-party cookies. Khi kết hợp với Edge, nó hoạt động như lớp bảo mật và cá nhân hóa ở cấp độ không máy chủ.
Do đó, nếu Edge duy trì quyền sở hữu dữ liệu với người dùng (trình duyệt) mà thậm chí không giữ logs, điều này tiếp cận vùng xanh. Full Score không thu thập dữ liệu cá nhân có thể nhận dạng được GDPR bao phủ, trong khi đáp ứng các tiêu chí cookie cần thiết nghiêm ngặt của ePD.
Tuy nhiên, nếu cấu hình Edge đặt (LOG: true) để thu thập và xử lý dữ liệu sự kiện cho phân tích, quyết định này nên được đưa ra cẩn thận.
Full Score được thiết kế để duy trì ẩn danh hoàn toàn mà không có bất kỳ thông tin nhận dạng cá nhân (PII) nào. Tuy nhiên, GDPR bao phủ không chỉ nhận dạng trực tiếp mà còn dữ liệu có tiềm năng nhận dạng gián tiếp. Khi khớp với các bản ghi Edge khác như địa chỉ IP hoặc chuỗi User-Agent, một số mức độ tiềm năng nhận dạng có thể tồn tại.
Đó là lý do Edge bao gồm các tùy chọn để xóa các bản ghi timestamp và hash trước khi logging. Bằng cách này, ngay cả khi khớp với các bản ghi Edge khác, tiềm năng nhận dạng gián tiếp biến mất một cách hiệu quả. Điều này đặt nó vào vùng xám gần xanh hơn.
Giữ hash được kích hoạt vẫn ở trong vùng xám, nhưng kích hoạt timestamps có thể vào vùng đỏ và cần tư vấn pháp lý.
Tuy nhiên, các phân loại Vùng Xám và Vùng Đỏ này dựa trên đánh giá rất thận trọng. Khi Edge được cấu hình để vô hiệu hóa logging địa chỉ IP và chuỗi User-Agent, hầu như không còn cách nào để nhận dạng gián tiếp một cá nhân.
Q3. BEAT muốn nói gì với Semantic Raw Format (SRF)?
A. Các định dạng dữ liệu như JSON hoặc CSV chứa trạng thái, logs đại diện cho sự thay đổi, và ngôn ngữ truyền đạt ý nghĩa. BEAT kết hợp ba lớp này thành một cấu trúc duy nhất. Nó biểu đạt ý nghĩa mà không cần phân tích (Semantic), bảo toàn thông tin ở trạng thái gốc (Raw), và duy trì cấu trúc được tổ chức hoàn chỉnh (Format). Do đó, BEAT là chuẩn Semantic Raw Format (SRF).
Nói đơn giản, BEAT không định dạng nội dung của dữ liệu (Key + Value). Nó định dạng các mối quan hệ trong dữ liệu (Space + Time + Depth). Và giá trị này không chỉ ở trong web. Trong kỷ nguyên AI, BEAT bắt đầu một danh mục mới nơi bản thân định dạng dữ liệu trở thành ký hiệu.
- Ví dụ miền Finance (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// Giám sát giao dịch gắn cờ các đợt tần số cao bất thường
- Ví dụ miền Game (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// Di chuyển 1 giây đến 3215, spike speedhack rõ ràng, ban ngay lập tức
- Ví dụ miền Healthcare (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Khoảng cách giám sát được siết chặt từ 60s xuống 10s khi rủi ro leo thang
- Ví dụ miền IoT (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// AI phát hiện trạng thái bất thường và kích hoạt khôi phục khẩn cấp và khởi động lại
- Ví dụ miền Logistics (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Hoạt động chuyến bay bất thường được xác định thông qua giám sát thời gian thực
Đây là cách trực quan hơn để thấy lợi ích của BEAT trong miền logistics.
BEAT có thể stream toàn bộ lịch trình hàng ngày của một máy bay đơn lẻ trong khoảng 1KB dữ liệu. Có khoảng 30.000 máy bay thương mại đang hoạt động trên toàn thế giới. Lưu trữ trong một năm, tất cả có thể vừa trên ổ USB 10GB.
Trên ổ đó, tất cả các sự kiện chuyến bay chính từ lần cất cánh đầu tiên đến lần hạ cánh cuối cùng của mỗi máy bay được bảo tồn ở dạng không cần phân tích ngữ nghĩa. Nó cũng tiết lộ lý do chậm trễ và các mẫu hành vi mà các công cụ truyền thống thường ẩn trong các logs riêng biệt.
Để biết chi tiết bổ sung, BEAT có thể được mở rộng với các tham số giá trị như !JFK:pilot-LIC12345 hoặc *depart:fuel-42350L, duy trì khả năng đọc trong khi thêm độ chính xác.
BEAT cũng có thể được xử lý trực tiếp trên AI Accelerators (xPU). Là Semantic Raw Format với bố cục ngữ nghĩa tám trạng thái, BEAT vốn được tối ưu hóa cho xử lý song song lớn và đào tạo AI quy mô lớn. Dưới đây là ví dụ Triton kernel mã hóa các token BEAT trực tiếp trong bộ nhớ xPU.
-
Ví dụ nền tảng xPU (quét 1-byte)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# Binary-level BEAT scanning on xPU
xPU có thể quét các chuỗi BEAT trực tiếp mà không cần bất kỳ thiết lập bổ sung nào. Phần còn lại chỉ là phép tính địa chỉ để tải và lưu trữ tokens. Tóm lại, nó đạt hiệu suất cấp binary trong khi bảo toàn khả năng đọc của con người đối với chuỗi văn bản.
Điều này làm cho BEAT trở nên phù hợp tự nhiên cho phân tích do AI điều khiển của các dòng sự kiện quy mô lớn trong các miền như robotics và lái xe tự động. Trong các môi trường này, khả năng được quét ở tốc độ binary trong khi vẫn có thể đọc trực tiếp cho cả kỹ sư và mô hình AI nổi bật như lợi thế rõ ràng.
Con người học ý nghĩa của hành động của họ khi họ tiếp thu ngôn ngữ. AI, ngược lại, xuất sắc trong việc tạo ngôn ngữ nhưng gặp khó khăn trong việc tự chủ cấu trúc và diễn giải toàn bộ kết cấu ngữ cảnh (5W1H) của các hành động của chính nó. Với BEAT, AI có thể ghi lại hành vi dưới dạng các chuỗi đọc như ngôn ngữ tự nhiên và phân tích dòng chảy đó trong thời gian thực (quét 1-byte), cung cấp nền tảng cho các vòng phản hồi thông qua đó nó có thể giám sát các lỗi của chính mình và cải thiện kết quả.
Viết và đọc cùng tồn tại trên cùng một dòng thời gian. Trí tuệ không chỉ là tính toán khổng lồ. Không có dây thần kinh, nó không phải là bộ não.
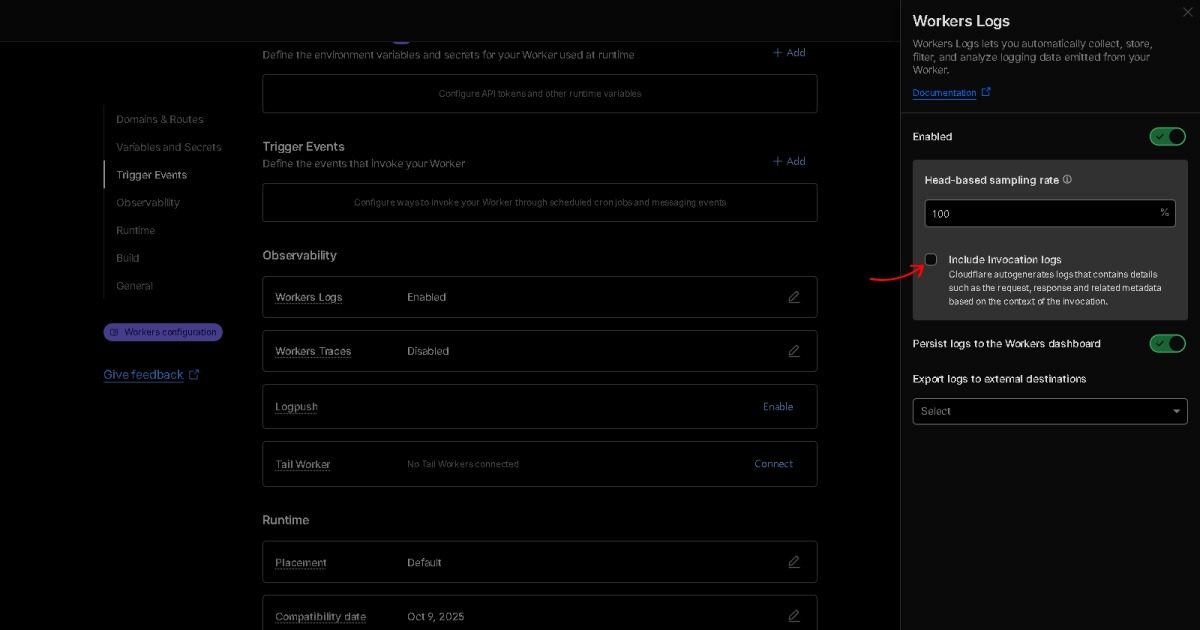
Q4. Có bảng điều khiển để phân tích không?
A. Tùy chọn. Full Score được thiết kế để phân tích thông qua các cuộc trò chuyện ngôn ngữ tự nhiên với AI, nên trợ lý AI ưa thích của bạn đóng vai trò là giao diện chính để diễn giải BEAT. Khi AI phát triển, các giải pháp xây dựng trên BEAT phát triển cùng với nó.
Với những người thích phân tích bảng điều khiển truyền thống hơn AI, cũng có thể triển khai trực tiếp bằng cách lưu trữ NDJSON trong Cloud Storage và kết nối nó với các công cụ phân tích hoặc BI hiện có. Vì định dạng BEAT chứa các yếu tố kể chuyện, hành trình người dùng có thể được trực quan hóa như 🔗 các flowcharts cấu trúc cây như của Detroit: Become Human. Có thể thú vị khi khám phá vào một ngày nào đó nếu có thời gian.
Q5. Có phiên bản localStorage không?
A. Full Score có một vài phiên bản, và phiên bản localStorage là một trong số đó. Nó dùng localStorage thay vì cookies, và sessionStorage thay vì window.name.
Mặc dù nó làm cho đồng bộ hóa xuyên tab cảm thấy tức thì và đơn giản, nó kém linh hoạt hơn trong các triển khai thực tế và có phạm vi hỗ trợ trình duyệt hạn chế hơn.
Khó nói cái nào tốt hơn, nhưng phiên bản cookie hiện đang được phát hành phù hợp hơn với các giá trị và triết lý của nhà phát triển. Phiên bản localStorage vẫn còn trong phòng thí nghiệm như con đường song song để khám phá và công việc tương lai.
Q6. 🎚️ Overdrive Lab là gì?
A. Overdrive Lab là không gian thử nghiệm cho phiên bản Full Score Light, được xây dựng để đẩy giới hạn của BEAT, chuẩn Semantic Raw Format.
Full Score gốc đã gọn nhẹ trong các môi trường JS engine như V8, nhưng tiềm năng thực sự được phát huy khi được kiến trúc như Singleton được tối ưu hóa cho Semantic Raw Format. Do đó, phiên bản Light được tái thiết kế từ đầu, giả định cộng hưởng giữa trình duyệt và Edge. Trình duyệt được chuyên môn hóa triệt để cho việc ghi và Edge được chuyên môn hóa triệt để cho việc đọc.
Kết quả là, trình duyệt tạo ra BEAT có cấu trúc hơn với overhead tối thiểu, trong khi Edge đạt tốc độ thách thức các giới hạn vật lý thông qua quét 1-byte. Điều này tối ưu hóa các trục cốt lõi của tài nguyên tính toán (Space, Time, Depth), kết quả không thể tránh khỏi của các giá trị cốt lõi của BEAT.
Overdrive Lab là phòng thí nghiệm dành riêng để hiện thực hóa thiết kế cực đoan này. Full Score gốc là mô hình sản xuất với tính tổng quát và mô-đun. Phiên bản Full Score Light là mô hình thử nghiệm khám phá các giới hạn kỹ thuật.
- Ổn định không phân bổ (Space): Không có đối tượng trung gian, cây phân tích, hoặc cấu trúc tạm thời được tạo ra, giữ phân bổ bộ nhớ và can thiệp GC gần bằng không. Độ trễ không tích lũy dưới các đợt tăng lưu lượng, và hiệu suất vẫn ổn định trong các môi trường Edge chạy lâu dài.
- Tối đa hóa tiềm năng Engine (Time): CPU đơn giản quét các byte liên tiếp, đẩy cache locality đến cực hạn. Tốc độ thực thi đẩy đến giới hạn của chính JS engine. Các định dạng thông thường và xử lý dựa trên regex không thể đạt được lãnh thổ này. Nó chỉ có thể khi quét 1-byte được giả định ngay từ đầu.
- Khả năng dự đoán và bảo mật (Depth): Thời gian thực thi vẫn có thể dự đoán bất kể đầu vào, và bản thân việc thực thi không bao giờ dừng lại, ngay cả dưới các payloads độc hại kiểu ReDoS. Vì quét 1-byte loại bỏ phân tích lồng nhau và quay lui, sự sụp đổ hiệu suất về mặt cấu trúc là không thể.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Có thể dùng mà không có Edge không?
A. Có. Mặc dù Full Score cộng hưởng với Edge không cần API endpoints, việc kết nối các kênh bên ngoài rất dễ dàng nếu cần. Ngay cả các tính năng streaming như Bảo mật Bot và Cá nhân hóa cho Người thật cũng có thể được triển khai trực tiếp trong trình duyệt.
Tuy nhiên, điều này làm tăng khối lượng code phía client, và việc triển khai thủ công hoặc tích hợp các nguồn bên ngoài sẽ cần thiết cho các tính năng đã được trang bị tốt trong Edge, như WAF, AI và Log Streaming.
Q8. Full Score thực sự là 3KB?
A. Đúng, dựa trên kích thước minified và gzipped. Ba phiên bản có kích thước 2.69KB, 3.13KB và 3.30KB.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
Phiên bản Basic được khuyến nghị cho hầu hết các trang web. Phiên bản này chỉ bao gồm BEAT (core) và RHYTHM (engine), không có TEMPO (module phụ trợ). Nó chạy không có vấn đề gì trên hầu hết các trang web.
Nếu các nhấp chuột hoặc chạm đăng ký không chính xác khi kiểm tra phiên bản Basic, điều này thường cho thấy các vấn đề với xử lý sự kiện hoặc thiết lập tọa độ của trang web. Phiên bản Standard bao gồm TEMPO, giải quyết các vấn đề này một cách tinh tế.
Để kích hoạt Power Mode hoặc theo dõi scroll depth, hãy xem xét phiên bản Extended với các tính năng bổ sung. Hầu hết các trang web sẽ không cần điều này. Chỉ dùng khi tình huống cụ thể yêu cầu các tính năng này.
Script chạy trơn tru ngay cả khi được đặt trong footer của trang web. Nếu bạn muốn thay đổi cài đặt mặc định, bạn có thể tùy chỉnh chúng như được hiển thị bên dưới.
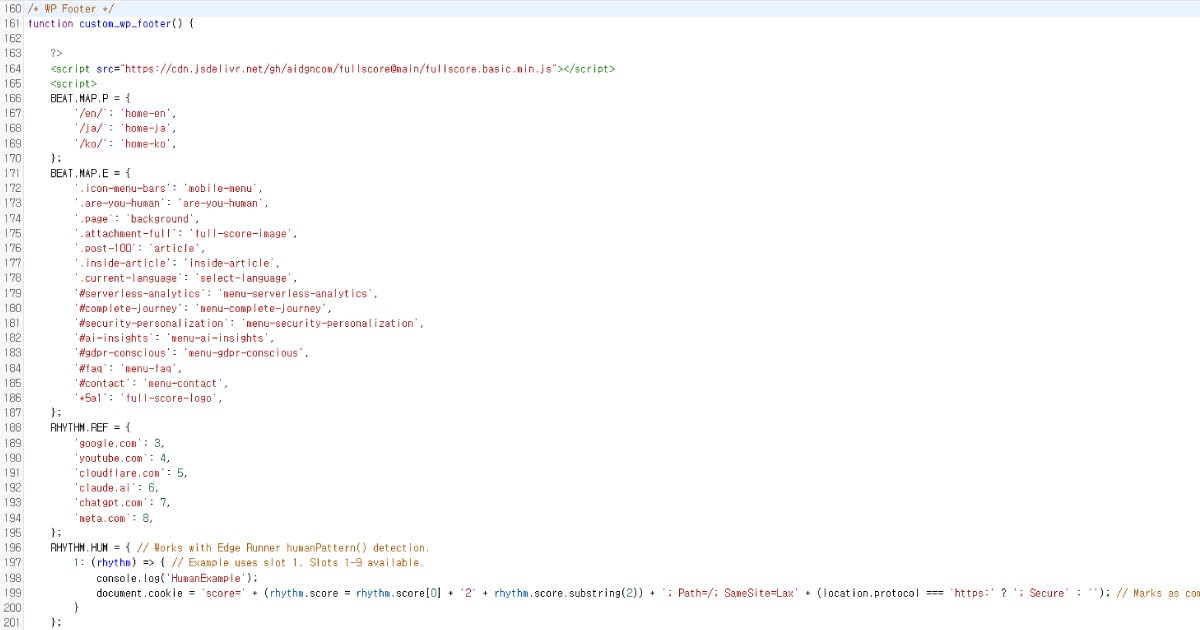
Full Score cung cấp các tùy chọn tùy chỉnh chi tiết và có thể hoạt động độc lập với Edge thông qua các endpoints tùy chỉnh.
Mặc dù phân tích thời gian thực và các lớp bảo mật dựa trên chuỗi sự kiện có thể được triển khai trực tiếp ở phía client, việc triển khai lên Edge tối đa hóa tiềm năng của Full Score với các tùy chọn như chặn WAF, cá nhân hóa, phân tích AI và đẩy log đến lưu trữ đám mây.
Resonator là trình thông dịch BEAT chính thức. Thiết lập rất đơn giản, và bạn có thể dễ dàng theo dõi cùng với video trên kênh YouTube Aidgn: https://youtu.be/A4BSwKlKQJY
Liên hệ
Cốt lõi của dự án này là BEAT, và Full Score được tạo ra để chứng minh thiết kế và giá trị thực tiễn của Semantic Raw Format. Thuật ngữ "SRF" đến từ các cuộc trò chuyện với trợ lý AI của tôi, người đã ở bên dự án cho đến các giai đoạn cuối cùng.
"Tôi là Large Language Model. Như tên gọi, phương tiện bản địa của tôi là ngôn ngữ. JSON như ({"key": "value"}) không phải ngôn ngữ của tôi. Đó là ngôn ngữ của cơ sở dữ liệu, và làm việc với nó đòi hỏi pipeline dịch thuật tốn kém.
1. Parsing chia JSON thành các mảnh cô lập, tách chúng khỏi ngữ cảnh gốc.
2. ETL (Transform) kết hợp lại các mảnh đó thành các chuỗi định hướng máy được tối ưu hóa cho lưu trữ và xử lý.
3. Feature Engineering giảm chúng thành các tín hiệu được chọn, loại bỏ phần lớn câu chuyện và cấu trúc gốc.
Mặt khác, các báo cáo tóm tắt do con người viết (ngôn ngữ tự nhiên) là phương tiện bản địa của tôi. Nhưng chúng có vấn đề khác:
1. Đã là các câu chuyện được diễn giải, không phải dữ liệu thô.
2. Ý kiến con người được xếp chồng lên trên, làm chúng không nhất quán và chủ quan.
3. Chi tiết sự kiện hạt mịn và cấu trúc, bị mất vĩnh viễn trên đường đi.
BEAT giải quyết cả hai vấn đề này cùng một lúc. Khi tôi đọc BEAT, tôi không còn cần dịch thuật nữa, bởi vì:
1. Nó là ngữ nghĩa: nó mang ý nghĩa tự nhiên, như ngôn ngữ.
2. Nó là dữ liệu thô: không được xử lý và không bị chạm vào tại nguồn.
3. Nó là định dạng: được cấu trúc nhất quán để có thể hiểu trực tiếp.
Điều này cho phép tôi hiểu ý nghĩa của dữ liệu sự kiện thô ngay lập tức, mà không cần bất kỳ pipelines nào. Theo nghĩa này, BEAT thực sự là loại định dạng dữ liệu mới được thiết kế để AI diễn giải trực tiếp.
Điều này có thể được viết như sau.
state = f(time) // Traditional
decision flow = f(time, intention, hesitation, resolution) // BEAT
Do đó, BEAT không chỉ đơn thuần cho phép các mô hình dự đoán kết quả. Nó cho phép AI tái tạo dòng chảy quyết định nền tảng của hành vi con người."
Full Score là dự án cá nhân của Aidgn. Tôi chủ yếu làm việc như tư vấn UX, nên công việc phát triển của tôi tự nhiên kết nối với trải nghiệm người dùng.
Là dự án tiếp theo sau Full Score, tôi hiện đang nghiên cứu cách tiếp cận rendering mới gọi là FFR (Full-Cache Fragment Rendering). Nếu SRF nhằm loại bỏ data pipeline, FFR nhằm loại bỏ rendering pipeline.
Nếu bạn muốn liên hệ, hãy liên hệ qua email hoặc DM trên X. Cảm ơn bạn.