
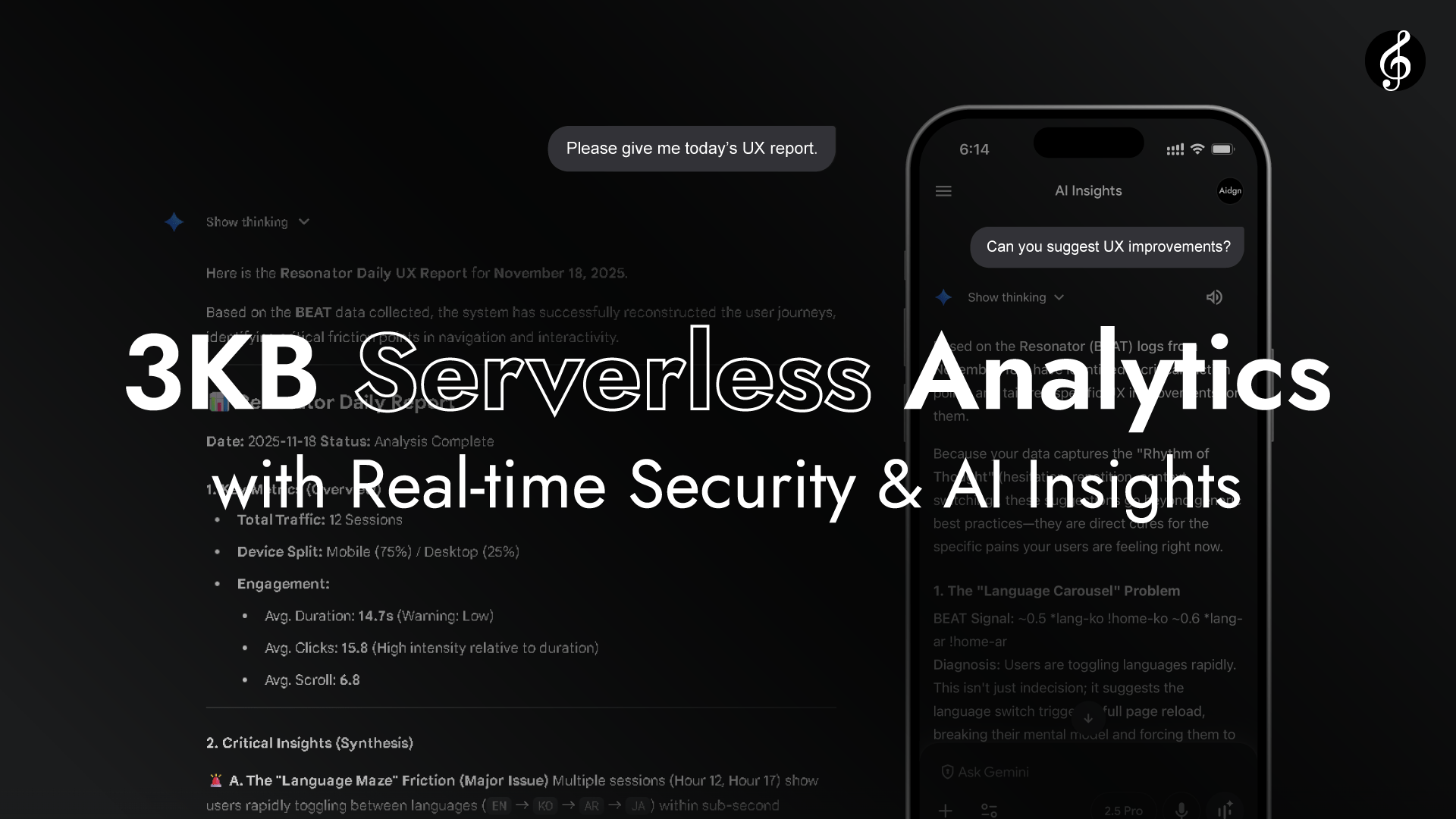
Full Score เป็นไลบรารีขนาด 3KB (gzip) ซึ่งเป็นการวิเคราะห์แบบไร้เซิร์ฟเวอร์ขนาดเบาพร้อมการวิเคราะห์ AI โดยตรงและ Growth Hacking. อิงตาม Semantic Raw Format (SRF) โดยใช้สถาปัตยกรรมที่มีประสิทธิภาพซึ่งช่วยให้ AI วิเคราะห์เส้นทางของผู้ใช้ได้โดยตรงโดยไม่ต้อง parsing เชิงความหมาย และหารือเกี่ยวกับผลลัพธ์กับผู้ช่วย AI ของคุณ (Gemini, Claude, GPT, Grok ฯลฯ)
เว็บไซต์นี้แสดงประสิทธิภาพแบบสดของ Full Score เส้นทางที่ปรากฏด้านล่างอยู่ในรูปแบบเดียวกับข้อมูลการโต้ตอบที่ Edge วิเคราะห์จริง มันไหลอย่างเป็นธรรมชาติ เหมือนดนตรีที่เกิด resonance
นี่คือความสามารถที่ถูกจัดเรียงไว้ คลิกเพื่อสำรวจแต่ละส่วน
- 🧭 การวิเคราะห์แบบไร้เซิร์ฟเวอร์: ไม่มี API Endpoints และมีศักยภาพลดต้นทุน 90%
- 🔍 เส้นทางผู้ใช้ข้ามแท็บแบบสมบูรณ์: ไม่ต้องใช้ Session Replay
- 🧩 ความปลอดภัยจากบอทและการปรับแต่งสำหรับมนุษย์: ผ่านชั้นเหตุการณ์แบบเรียลไทม์
- 🧠 BEAT ไหลสู่ AI Insights: เป็นสตริงเชิงเส้น ไม่ต้อง parsing เชิงความหมาย
- 🛡️ สถาปัตยกรรมที่คำนึงถึง GDPR: ไม่มีตัวระบุโดยตรง
ทั้งหมดนี้ทำได้โดยการเปลี่ยนเบราว์เซอร์ให้เป็นฐานข้อมูลเสริมแบบกระจายศูนย์
เดโมนี้เน้นประสิทธิภาพแบบสด ให้ภาพรวมที่รวดเร็วและเข้าใจง่าย หากสิ่งนี้ตรงใจคุณ โปรดดู 🔗 README ของ GitHub และคอมเมนต์ในโค้ดสำหรับรายละเอียดทางเทคนิคทั้งหมด
1. การวิเคราะห์แบบไร้เซิร์ฟเวอร์: ไม่มี API Endpoints และมีศักยภาพลดต้นทุน 90%
แพลตฟอร์มวิเคราะห์แบบดั้งเดิมที่สร้างมาสำหรับการวิเคราะห์ทราฟฟิกเว็บ, session replay และการติดตามกลุ่มผู้ใช้ทำงานได้ดีในหน้าที่ของมัน อย่างไรก็ตาม การได้รับ insights ของผู้ใช้มักต้องการโครงสร้างพื้นฐานที่หนักและซับซ้อน
พวกมันพึ่งพา payloads เหตุการณ์ขนาดใหญ่และ DOM snapshots ทั้งหมดถูกส่งไปยังเซิร์ฟเวอร์ส่วนกลางเพื่อจัดเก็บและประมวลผล สิ่งนี้ส่งผลให้ script payloads มีขนาดหลายสิบกิโลไบต์ มีคำขอเครือข่ายนับล้าน และค่าใช้จ่ายโครงสร้างพื้นฐานรายเดือนเป็นหลักพัน
Full Score ไม่พยายามแก้ความซับซ้อนนี้ มันกำจัดมันออกไปทั้งหมด โดยเสนอแนวทางใหม่
- การวิเคราะห์แบบดั้งเดิม
เบราว์เซอร์ → API → Raw Database → Queue (Kafka) → Transform (Spark) → Refined Database → คลังข้อมูล
⛔ 7 ขั้นตอน, $500 – $5,000/เดือน (แตกต่างตาม payload)
- Full Score
เบราว์เซอร์ ~ Edge → คลังข้อมูล
✅ 2 ขั้นตอน, $50 – $500/เดือน// ไม่ต้องการ API endpoints
// ไม่ต้องการ ETL pipeline
// ไม่ต้องการการเข้าถึง Origin
มันเริ่มจากการตระหนักง่ายๆ การได้รับ insight เกี่ยวกับเส้นทางการท่องเว็บทั้งหมดของผู้ใช้ไม่จำเป็นต้องส่งข้อมูลไปที่อื่นเสมอไป
ทุกเบราว์เซอร์มีที่เก็บข้อมูลอยู่แล้ว เช่น first-party cookies และ localStorage จะเป็นอย่างไรถ้า insights ถูกบันทึกไว้ที่นั่นก่อน และถูกตีความเพียงครั้งเดียว ในขณะที่ประสิทธิภาพของผู้ใช้ในเบราว์เซอร์ถือว่าเสร็จสมบูรณ์?
ด้วยการเปลี่ยนแต่ละเบราว์เซอร์ให้เป็นโครงสร้างพื้นฐาน ความต้องการ backends ที่ซับซ้อนและรวมศูนย์ก็หายไป ผู้ใช้หนึ่งพันล้านคนกลายเป็นเหมือนฐานข้อมูลกระจายศูนย์หนึ่งพันล้านแห่ง แต่ละแห่งเก็บข้อมูลดิบของตัวเอง
แน่นอน มีเพียงไม่กี่คนที่จะยอมรับแนวทางนี้เพราะโปรโตคอลการส่งข้อมูลมีข้อจำกัดมาก Payloads เหตุการณ์และ DOM snapshots หนักเกินไป ดังนั้นแม้จะส่งข้อมูลเพียงครั้งเดียวก็ยังต้องการชั้น Queue และ Transform
นั่นคือเหตุผลที่ Full Score ใช้ BEAT ซึ่งเป็นรูปแบบข้อมูลใหม่ BEAT มี overhead เชิงโครงสร้างต่ำกว่ารูปแบบข้อมูลแบบดั้งเดิม จึงเบากว่าและไม่ต้องการคิวหรือชั้นแปลงข้อมูล ด้วยการบันทึกลำดับเหตุการณ์เป็นสตริงเชิงเส้น ข้อมูลดิบกลายเป็นดนตรี อ่านได้อย่างเป็นธรรมชาติทั้งสำหรับมนุษย์และ AI
และ resonance กับ Edge computing ทำให้เรื่องราวสมบูรณ์
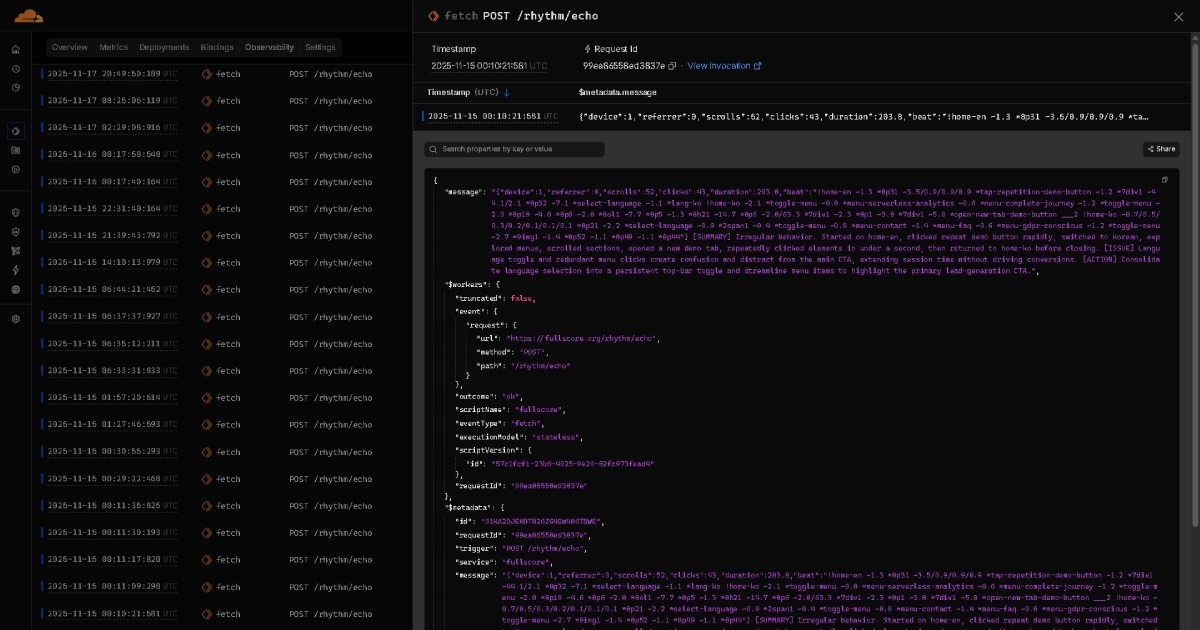
ดังที่วิดีโอแสดง Edge แปลง Full Score เป็นชั้นวิเคราะห์แบบเรียลไทม์โดยไม่ต้องการ API endpoints Edge อ่าน request headers จากแต่ละเบราว์เซอร์
ไม่ต้องการการเข้าถึง Origin ประสิทธิภาพเสร็จสมบูรณ์ผ่าน resonance ตามธรรมชาติระหว่างเบราว์เซอร์และ Edge รวดเร็ว ชัดเจน และพึ่งพาตัวเอง Latency ต่ำจนไม่รู้สึก
เพราะเบราว์เซอร์และ Edge อยู่ใกล้กันมากในพื้นที่และเวลา การเชื่อมต่อของพวกมันคล้าย resonance มากกว่าการส่งข้อมูล เหมือนการฟังดนตรีที่ไหลผ่านอากาศ
สำหรับเว็บไซต์ที่ใช้จ่าย $500–5,000/เดือน สำหรับการวิเคราะห์ Full Score มักจะทำงานที่ประมาณ $50/เดือน สำหรับ Edge computing และการจัดเก็บบนคลาวด์รวมกัน ด้วย AI insights แบบเรียลไทม์ที่ Edge ต้นทุนอาจเพิ่มขึ้นถึงประมาณ $500/เดือน นี่คือการประมาณการแบบอนุรักษ์นิยมและต้นทุนจริงอาจแตกต่างกันขึ้นอยู่กับสภาพแวดล้อมของคุณ การออกแบบแบบกระจายศูนย์ที่อิง Edge ทำให้ต้นทุนคงที่เมื่อทราฟฟิกเพิ่มขึ้น
Full Score ใช้โครงสร้างข้อมูลและกระแสที่แตกต่างจากแนวทางแบบดั้งเดิม ทำให้เป็นพันธมิตรที่ทรงพลังแทนที่จะเป็นการแทนที่ทั้งหมดสำหรับชั้นวิเคราะห์หรือความปลอดภัยที่มีอยู่ มันทำงานได้อย่างมีประสิทธิภาพมากที่สุดร่วมกับแพลตฟอร์มเช่น Edge analytics และ WAF
2. เส้นทางผู้ใช้ข้ามแท็บแบบสมบูรณ์: ไม่ต้องใช้ Session Replay
การวิเคราะห์แบบดั้งเดิมทำให้การวิเคราะห์ข้ามแท็บซับซ้อนและไม่สมบูรณ์ มันต้องการ pipeline ที่ซับซ้อนรวมถึงการรวบรวมตัวระบุ, sessionization, การนำเข้าข้อมูล, joins, post-handling และการซิงโครไนซ์แบบเรียลไทม์
Full Score ถือว่าเบราว์เซอร์เป็นฐานข้อมูลเสริม ดังนั้นเส้นทางที่สมบูรณ์รวมถึงการนำทางข้ามแท็บจะถูกบันทึกทันที ด้วย prompt เดียว AI สามารถตีความข้อมูลนี้โดยตรง กำจัด pipeline ทั้งหมดของการรวบรวมตัวระบุ, sessionization, การนำเข้าข้อมูล, joins, post-handling และการซิงโครไนซ์แบบเรียลไทม์
คลิกปุ่มด้านล่างเพื่อเปิดแท็บใหม่และทดสอบด้วยตัวคุณเอง
ในข้อมูล RHYTHM ของเดโม คุณสามารถเห็นการนำทางแท็บในรูปแบบ (@---N)
Full Score รองรับแท็บสูงสุด 7 แท็บโดยค่าเริ่มต้น เมื่อแท็บที่ 8 เปิด ข้อมูลที่มีอยู่จะถูกจัดเก็บโดยอัตโนมัติและชุดใหม่จะเริ่มต้น เซสชันทั้งหมดถูกรวมเป็นชุดพร้อมกันเป็น snapshot ที่สมบูรณ์หนึ่งรายการ
แม้ว่าการรวมเป็นชุดจะเกิดขึ้นมากกว่าหนึ่งครั้งเนื่องจากเงื่อนไขเฉพาะ เซสชันทั้งหมดจะแชร์ timestamp และ hash เดียวกัน ทำให้สามารถสร้างเส้นทางทั้งหมดขึ้นมาใหม่เป็นลำดับต่อเนื่องเดียว
อย่างไรก็ตาม การเปิดแท็บ 8+ พร้อมกันนั้นหายาก สิ่งนี้อาจบ่งบอกถึงรูปแบบพฤติกรรมบอทที่ผิดปกติ
Full Score จัดการกับความท้าทายนี้อย่างสง่างาม 🔗 เมื่ออยู่ในสภาวะ resonance กับ Edge จะเปิดใช้งานความปลอดภัยและการปรับแต่งแบบเรียลไทม์
3. ความปลอดภัยจากบอทและการปรับแต่งสำหรับมนุษย์: ผ่านชั้นเหตุการณ์แบบเรียลไทม์
เริ่มด้วยการทดสอบง่ายๆ แตะปุ่มด้านล่างด้วยความเร็วของบอท (แตะเร็วแบบเครื่องจักร) หรือความเร็วของมนุษย์ (แตะไม่สมบูรณ์แบบ เป็นธรรมชาติ)
การทดสอบนี้อาจทริกเกอร์ Managed Challenge ชั่วคราวซึ่งจะหายไปในประมาณ 30 วินาที
เห็นไหมว่าฟิลด์ movement เปลี่ยนจาก (0000000000) เป็น (1000000000), (2000000000) หรือ (0100000000), (0200000000)? นั่นคือ Full Score ทำงานร่วมกับ Edge เพื่อวิเคราะห์พฤติกรรมแบบเรียลไทม์
การตรวจจับบอทแบบดั้งเดิมพึ่งพาการบล็อก IP, CAPTCHAs และ fingerprinting แต่บอทอัจฉริยะหลบเลี่ยงสิ่งเหล่านี้ได้ Full Score ใช้แนวทางที่แตกต่าง โดยเฝ้าดูรูปแบบพฤติกรรมเพื่อจับบอทที่พยายามทำตัวเหมือนมนุษย์แต่เปิดเผยตัวเองผ่านการกระทำที่ไม่เป็นธรรมชาติเช่นการคลิกโดยไม่เลื่อน
สำหรับผู้ใช้จริง สิ่งนี้ให้ประสบการณ์ผู้ใช้ที่ปรับแต่งได้ มีคนคลิกเพิ่มลงตะกร้าสามครั้งอย่างรวดเร็ว? แสดงข้อความช่วยเหลือให้พวกเขา มีคนใช้เวลานานในการเรียกดู? แสดงส่วนลดให้พวกเขา
ในส่วนถัดไป คุณสมบัติที่ AI อ่านได้ของ BEAT จะถูกนำเสนอ แต่ดังที่ตัวอย่างที่ผ่านมาแสดงให้เห็น ข้อมูลเหตุการณ์ที่แสดงผ่าน BEAT มีคุณค่าในทางปฏิบัติที่ชัดเจนในตัวมันเอง การใช้ Full Score เพียงเพื่อความปลอดภัยและการปรับแต่งแบบเรียลไทม์ก็เป็นทางเลือกที่ถูกต้องเช่นกัน
4. BEAT ไหลสู่ AI Insights: เป็นสตริงเชิงเส้น ไม่ต้อง parsing เชิงความหมาย
BEAT (Behavioral Event Analytics Transcript) เป็นรูปแบบที่แสดงออกสำหรับข้อมูลเหตุการณ์หลายมิติ รวมถึงพื้นที่ที่เหตุการณ์เกิดขึ้น เวลาที่เหตุการณ์เกิดขึ้น และความลึกของแต่ละเหตุการณ์เป็นลำดับเชิงเส้น ลำดับเหล่านี้แสดงความหมายโดยไม่ต้อง parsing (Semantic) รักษาข้อมูลในสถานะดั้งเดิม (Raw) และรักษาโครงสร้างที่จัดระเบียบอย่างสมบูรณ์ (Format) ดังนั้น BEAT จึงเป็นมาตรฐาน Semantic Raw Format (SRF)
BEAT บรรลุประสิทธิภาพระดับ binary (สแกน 1-byte) ในขณะที่รักษาความสามารถในการอ่านของมนุษย์ของลำดับข้อความ BEAT กำหนดโทเค็นหลักหกตัวภายในเลย์เอาต์เชิงความหมายแปดสถานะ (3-bit) เมื่อจัดเรียงกับ 5W1H พวกมันจับเจตนาของสถาปัตยกรรมที่ออกแบบโดยมนุษย์อย่างสมบูรณ์ในขณะที่เหลือสองสถานะสำหรับส่วนขยายเฉพาะโดเมน รวมกันแล้วพวกมันสร้างสัญกรณ์หลักของรูปแบบ BEAT
ขีดล่าง (_) เป็นตัวอย่างหนึ่งของโทเค็นส่วนขยายที่ใช้สำหรับ serialization และแสดงฟิลด์ meta เช่น _device:mobile_referrer:search_beat:!page~10*button:small~15*menu ฟิลด์ meta เหล่านี้อธิบายลำดับ BEAT โดยไม่เปลี่ยนแปลงรูปแบบหลักในขณะที่รักษาประสิทธิภาพการสแกน 1-byte
🔗 สำหรับคำอธิบายโดยละเอียดของรูปแบบ BEAT ดู README ของ GitHub
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
ลำดับ BEAT หลายรายการสามารถเขียนในรูปแบบบรรทัดที่เข้ากันได้กับ NDJSON โดยแต่ละเส้นทางอยู่ในบรรทัดเดียว สิ่งนี้ทำให้ logs กะทัดรัด ทำให้การ query ง่าย และปรับปรุงประสิทธิภาพการวิเคราะห์ AI ในสภาพแวดล้อม Finance, Game, Healthcare, IoT, Logistics และอื่นๆ กระแสที่สมบูรณ์ทางความหมายของ BEAT ช่วยให้รวมได้รวดเร็วและเข้ากันได้ง่ายกับรูปแบบที่เกี่ยวข้อง
แน่นอน การแสดงแบบ NDJSON นี้เป็นทางเลือก ข้อมูลเดียวกันสามารถแสดงในรูปแบบ BEAT ที่ง่ายกว่าในขณะที่รักษาประสิทธิภาพการสแกน 1-byte เช่น: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎... ที่นี่ อีโมจิ 🔎 เน้นตำแหน่งทันทีหลังแต่ละโทเค็นการสแกน 1-byte
จุดประสงค์ของการแสดงนี้คือการเคารพรูปแบบข้อมูลแบบดั้งเดิม รวมถึง JSON และบริการที่สร้างขึ้นรอบๆ มัน (เช่น BigQuery) เพื่อให้ BEAT สามารถนำไปใช้ได้ง่ายและอยู่ร่วมกับพวกมันแทนที่จะพยายามแทนที่พวกมัน
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
AI Insights
[CONTEXT] ผู้ใช้มือถือ, การเยี่ยมชม Mapped(5), 56 scrolls, 15 clicks, 1205.2 วินาที
[SUMMARY] พฤติกรรมสับสน ลงจอดที่หน้าแรก ลังเลในส่วนช่วยเหลือด้วยการคลิกซ้ำที่ช่วง 37 และ 12 วินาที ย้ายไปหน้าสินค้า เปิดรายละเอียดในแท็บใหม่ ดูรูปภาพประมาณ 240 วินาที แตะปุ่มซื้อสามครั้งที่ช่วง 1.3, 0.8 และ 0.8 วินาที กลับไปแท็บแรกและเปิดตะกร้าหลังจากนั้นไม่นาน แต่ไม่ดำเนินการชำระเงิน
[ISSUE] ถึงตะกร้าแต่ไม่สำเร็จการซื้อ การกระทำซื้อซ้ำอาจสะท้อนการเพิ่มหลายรายการโดยตั้งใจหรือความขัดข้องในการเลือกตัวเลือก ความล่าช้านานก่อนชำระเงินบ่งบอกถึงความไม่แน่ใจ
[ACTION] ประเมินว่าการกระทำซื้อหรือตะกร้าซ้ำแสดงถึงพฤติกรรมเปรียบเทียบโดยตั้งใจหรือความขัดข้องในการชำระเงิน หากเป็นความขัดข้อง ให้ทำให้การจัดการตัวเลือกง่ายขึ้นและเน้นรายละเอียดสินค้าหลักเร็วขึ้นในกระแส
รูปแบบข้อมูลแบบดั้งเดิม รวมถึง JSON เป็นเหมือนจุด พวกมันยอดเยี่ยมสำหรับการจัดระเบียบและแยกเหตุการณ์แต่ละรายการ แต่การเข้าใจว่าพวกมันเล่าเรื่องอะไรต้องการ parsing และการตีความ
BEAT เป็นเหมือนเส้น มันจับข้อมูลเดียวกับ JSON แต่เพราะเส้นทางผู้ใช้ไหลเหมือนดนตรี เรื่องราวจึงชัดเจนทันที
BEAT แสดงสถานะเชิงความหมายโดยใช้โทเค็น Printable ASCII (0x20 ถึง 0x7E) เท่านั้นที่ผ่านชั้นประมวลผลและความปลอดภัยได้อย่างราบรื่น ไม่ต้องการการเข้ารหัสหรือถอดรหัสแยกต่างหาก และเพราะมันเล็กพอที่จะอยู่ในที่เก็บข้อมูลดั้งเดิม การวิเคราะห์แบบเรียลไทม์จึงทำงานโดยไม่มีความล่าช้าในสภาพแวดล้อมส่วนใหญ่
ดังนั้น BEAT จึงเป็นข้อมูลดิบ แต่ก็พึ่งพาตัวเองได้ด้วย ไม่ต้องการ parsing เชิงความหมาย สิ่งนี้ฟังดูยิ่งใหญ่ แต่จริงๆ แล้วไม่ใช่ รูปแบบการแสดงออกของ BEAT ได้รับแรงบันดาลใจจากรูปแบบข้อมูลที่พบมากที่สุดในโลก รูปแบบข้อมูลที่เก่าแก่ที่สุดในประวัติศาสตร์มนุษย์ ภาษาธรรมชาติ
และ AI เป็นผู้เชี่ยวชาญในการเข้าใจภาษาธรรมชาติ
ข้อมูลที่ไหลผ่าน resonance จาก Full Score ไปยัง Edge กลายเป็นรายงาน insight แบบเรียลไทม์ผ่าน AI ขนาดเบา (เช่น โมเดลระดับ GPT OSS 20B) รายงานเหล่านี้จะถูกจัดเก็บไปยังแพลตฟอร์มจัดเก็บเช่น GitHub จัดระเบียบตามวันที่
ข้อมูลที่สะสมทั้งหมดนี้ไหลไปยังผู้ช่วย AI ของคุณ สิ่งนี้สร้างกระแสความร่วมมือ AI-ต่อ-AI ที่ AI ขนาดเบาสร้างรายงานสำหรับแต่ละการทำงานหรือเซสชันและ AI ขั้นสูงสังเคราะห์ insights ที่ครอบคลุมจากรายงานทั้งหมด Dashboards เป็นทางเลือก และมนุษย์ไม่จำเป็นต้องวิเคราะห์มันด้วยตนเอง เมื่อเวลาผ่านไป โมเดลอาจแข็งแกร่งพอที่กระแสทั้งหมดนี้จบในรอบเดียว โดยไม่มีขั้นตอนความร่วมมือ AI-ต่อ-AI ที่ชัดเจนเลย เมื่อ AI พัฒนา โซลูชันที่สร้างบน BEAT จะพัฒนาไปพร้อมกับมัน
เริ่มการสนทนา
"รูปแบบเส้นทางผู้ใช้ใดที่ขับเคลื่อน conversions?"
"มี ISSUEs ที่น่าสนใจวันนี้ไหม?"
"คุณช่วยแนะนำไอเดีย Growth Hacking จากจุดเสียดทาน UX ได้ไหม?"
5. สถาปัตยกรรมที่คำนึงถึง GDPR: ไม่มีตัวระบุโดยตรง
การใช้งานหลักของ Full Score ใช้ first-party cookies เป็นที่เก็บข้อมูล แม้ว่าเวอร์ชัน localStorage จะมีอยู่ cookies ให้ข้อได้เปรียบด้านการทำงานเนื่องจากถูกรวมอัตโนมัติใน HTTP request headers สิ่งนี้ช่วยให้ Edge อ่านมันได้ทันที
First-party cookies แตกต่างโดยพื้นฐานจาก third-party tracking cookies ที่มักถูกตั้งค่าสถานะในการวิเคราะห์ Full Score เก็บข้อมูลเฉพาะในเบราว์เซอร์ของผู้ใช้และเข้าสู่สภาวะ resonance ตามธรรมชาติกับ Edge โดยไม่มี API endpoints ซึ่งลดการเปิดเผยเมื่อเทียบกับแนวทางการวิเคราะห์แบบดั้งเดิมจริงๆ
เฉพาะรูปแบบง่ายๆ เท่านั้นที่ถูกบันทึก ไม่ใช่ข้อมูลส่วนบุคคลที่ละเอียดอ่อน (PII) ในความหมายของ BEAT "Who" ไม่ได้หมายถึงผู้ใช้ ตามที่กำหนดโดย ! = Contextual Space (who) ตัวตนมาจากพื้นที่เอง ผู้ใช้ใน !military ถูกเข้าใจผ่านบริบทของทหาร และผู้ใช้ใน !hospital ผ่านบริบทของแพทย์หรือผู้ป่วย มันไม่เคยถามบุคคลว่า "คุณเป็นใคร?"
แนวทางนี้ขยายไปสู่ความปลอดภัยอย่างเป็นธรรมชาติ Full Score ออกแบบมาไม่ใช่รอบๆ การส่งข้อมูลแบบดั้งเดิม ที่ความเป็นเจ้าของข้อมูลถูกโอนไปยังเซิร์ฟเวอร์ แต่รอบๆ โครงสร้างที่ความเป็นเจ้าของข้อมูลยังคงอยู่กับผู้ใช้ (เบราว์เซอร์) ในขณะที่ resonance เกิดขึ้นที่ Edge
ในการตั้งค่าที่อิง resonance ทุกอย่างเริ่มต้นและสิ้นสุดระหว่างเบราว์เซอร์และ Edge โดยไม่แตะเซิร์ฟเวอร์ต้นทางสำหรับการวิเคราะห์เลย ดังนั้นแม้ว่าเว็บไซต์เองจะถูกโจมตีโดย XSS หรือการโจมตีแทรกโค้ดที่คล้ายกัน แทบไม่มีโอกาสที่ข้อมูลนี้จะมีอยู่บนเซิร์ฟเวอร์ต้นทางในรูปแบบที่ผู้โจมตีสามารถขโมยได้อย่างมีความหมาย แม้ในสถานการณ์เลวร้ายที่สุดที่ข้อมูลที่จัดเก็บจาก Edge ไปยังที่เก็บภายนอกเช่น GitHub ถูกเจาะ สิ่งที่เก็บไว้เป็นเพียง logs พฤติกรรมง่ายๆ ที่ไม่มีความหมายในตัวมันเอง เส้นทางทฤษฎีอีกเส้นหนึ่งคือการโจมตีแต่ละเบราว์เซอร์เป็นรายบุคคลราวกับว่าเป็นส่วนหนึ่งของฐานข้อมูลกระจายขนาดใหญ่ แต่ในทางปฏิบัติเวกเตอร์การโจมตีนี้ดำเนินการได้ยากมาก
สำหรับคำแนะนำการปฏิบัติตาม GDPR และ ePD โดยละเอียด ดูส่วน FAQ ด้านล่าง
FAQ
Q1. ทำไม Full Score ใช้คำว่า "resonance"? การส่ง HTTP header ยังไม่ใช่การส่งข้อมูลหรือ?
A. การเข้าใจสิ่งนี้ต้องดูที่ความเป็นเจ้าของข้อมูล นี่คือภาพประกอบเพื่ออธิบาย
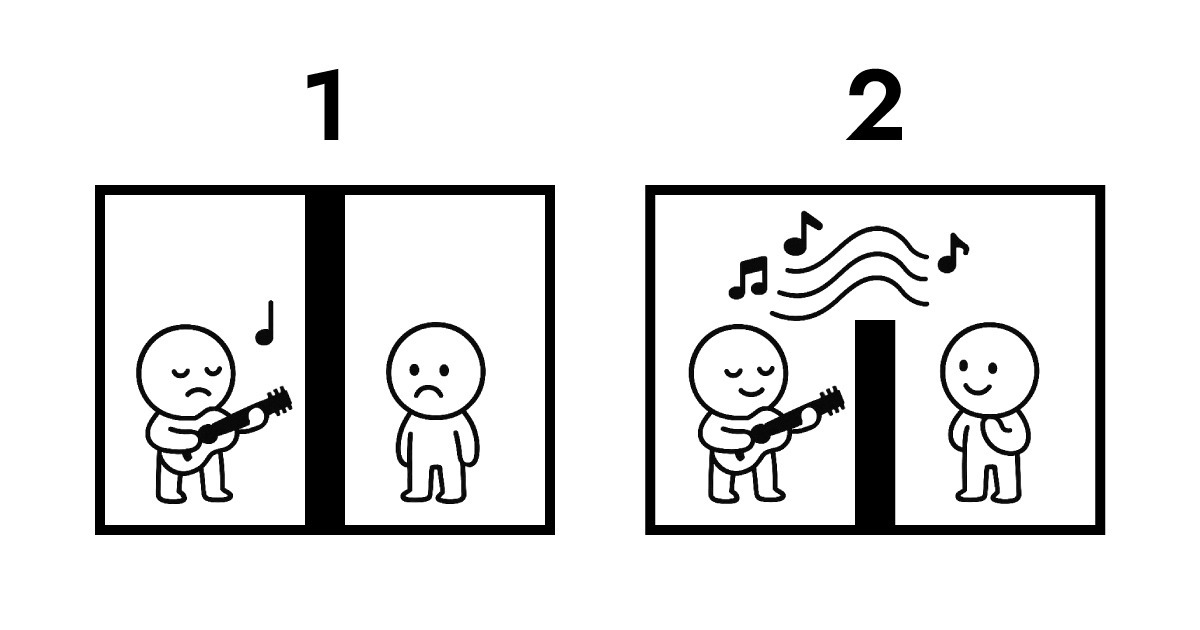
ภาพแรกแสดงการส่งข้อมูลแบบดั้งเดิม ทั้งสองฝ่ายแยกจากกันโดยสิ้นเชิง เพื่อให้ B ได้ยินการแสดงของ A การส่งข้อมูลตามโปรโตคอลกลายเป็นสิ่งหลีกเลี่ยงไม่ได้ ระหว่างการแลกเปลี่ยนนี้ ความเป็นเจ้าของข้อมูลเปลี่ยนจาก A ไป B และถูกเก็บไว้บนเซิร์ฟเวอร์ หากไม่เก็บมัน ไม่มีทางที่ B จะได้ยินการแสดงของ A
ภาพที่สองแสดง resonance ระหว่าง Full Score และ Edge ยังมีกำแพงระหว่างพวกเขาที่ไม่สามารถข้ามได้ทางกายภาพ แต่ B สามารถฟังการแสดงของ A แบบเรียลไทม์ ตลอดการโต้ตอบทั้งหมดนี้ ความเป็นเจ้าของข้อมูลยังคงอยู่กับ A
นี่คือสิ่งที่ Edge computing เปิดใช้งานได้อย่างแท้จริงในฐานะสถาปัตยกรรมแบบไร้เซิร์ฟเวอร์ Edge ไม่ต้องรับและเก็บข้อมูลเหมือนเซิร์ฟเวอร์แบบดั้งเดิม แทนที่จะทำเช่นนั้น มันตีความและตอบสนองทันทีที่ชั้นเครือข่ายที่ใกล้ผู้ใช้มากที่สุด พูดง่ายๆ Full Score สร้างโครงสร้างที่ความเป็นเจ้าของข้อมูลยังคงอยู่กับผู้ใช้ (เบราว์เซอร์) ในขณะที่เปิดใช้งานการโต้ตอบแบบเกือบทันที
นั่นคือเหตุผลที่ Full Score เลือก "resonance" เป็นอุปมาทางดนตรี แทนที่จะเน้นกลศาสตร์ทางกายภาพ มันเน้นที่สถาปัตยกรรมเชิงตรรกะที่แสดงด้านบน
Q2. ฉันต้องการความยินยอม cookies สำหรับการปฏิบัติตาม GDPR และ ePD หรือไม่?
A. นี่เป็นหัวข้อที่ต้องการการปรึกษาทางกฎหมายขึ้นอยู่กับเขตอำนาจศาลและนโยบายเว็บไซต์ โปรดเข้าใจว่าคำตอบนี้อิงจากประสบการณ์และวิจารณญาณส่วนบุคคล
คำตอบไม่ได้ขึ้นอยู่กับ Full Score เอง แต่ขึ้นอยู่กับการกำหนดค่าที่กำหนดเองของ Edge ที่อยู่ในสภาวะ resonance กับมัน
GDPR ต้องการพื้นฐานทางกฎหมายเมื่อรวบรวมหรือจัดการข้อมูลส่วนบุคคลที่ระบุตัวตนได้ ePD ต้องการความยินยอมของผู้ใช้เมื่อจัดเก็บข้อมูลในหรือเข้าถึงที่เก็บข้อมูลเบราว์เซอร์ รวมถึง cookies อย่างไรก็ตาม มันยอมรับข้อยกเว้นที่เรียกว่า "จำเป็นอย่างเคร่งครัด" สำหรับ cookies ที่จำเป็นอย่างเคร่งครัดสำหรับการทำงาน
ดังที่อธิบายไว้ก่อนหน้านี้ Full Score ใช้ first-party cookies ที่ความเป็นเจ้าของข้อมูลยังคงอยู่กับผู้ใช้ (เบราว์เซอร์) แตกต่างโดยพื้นฐานจาก third-party cookies เมื่อรวมกับ Edge มันทำงานเป็นชั้นความปลอดภัยและการปรับแต่งที่ระดับไร้เซิร์ฟเวอร์
ดังนั้น หาก Edge รักษาความเป็นเจ้าของข้อมูลกับผู้ใช้ (เบราว์เซอร์) โดยไม่แม้แต่เก็บ logs สิ่งนี้เข้าใกล้โซนสีเขียว Full Score ไม่รวบรวมข้อมูลส่วนบุคคลที่ระบุตัวตนได้ที่ครอบคลุมโดย GDPR ในขณะที่ตรงตามเกณฑ์ cookies ที่จำเป็นอย่างเคร่งครัดของ ePD
อย่างไรก็ตาม หากการกำหนดค่า Edge ตั้ง (LOG: true) เพื่อรวบรวมและจัดการข้อมูลเหตุการณ์สำหรับการวิเคราะห์ การตัดสินใจนี้ควรทำอย่างระมัดระวัง
Full Score ออกแบบมาเพื่อรักษาการไม่ระบุตัวตนอย่างสมบูรณ์โดยไม่มีข้อมูลที่ระบุตัวบุคคลได้ (PII) ใดๆ อย่างไรก็ตาม GDPR ครอบคลุมไม่เพียงการระบุตัวตนโดยตรงแต่ยังรวมถึงข้อมูลที่มีศักยภาพสำหรับการระบุตัวตนทางอ้อม เมื่อจับคู่กับบันทึก Edge อื่นๆ เช่น ที่อยู่ IP หรือสตริง User-Agent อาจมีระดับหนึ่งของศักยภาพการระบุตัวตน
นั่นคือเหตุผลที่ Edge มีตัวเลือกในการลบบันทึก timestamp และ hash ก่อน logging ด้วยวิธีนี้ แม้เมื่อจับคู่กับบันทึก Edge อื่นๆ ศักยภาพการระบุตัวตนทางอ้อมก็หายไปอย่างมีประสิทธิภาพ สิ่งนี้ทำให้อยู่ในโซนสีเทาที่ใกล้สีเขียว
การเปิดใช้งาน hash ยังคงอยู่ในโซนสีเทา แต่การเปิดใช้งาน timestamps อาจเข้าโซนสีแดงและควรปรึกษาทางกฎหมาย
อย่างไรก็ตาม การจำแนกโซนสีเทาและโซนสีแดงเหล่านี้อิงจากการประเมินแบบอนุรักษ์นิยมมาก เมื่อ Edge ถูกกำหนดค่าให้ปิดการ logging ของที่อยู่ IP และสตริง User-Agent แทบไม่มีทางเหลือในการระบุตัวบุคคลทางอ้อม
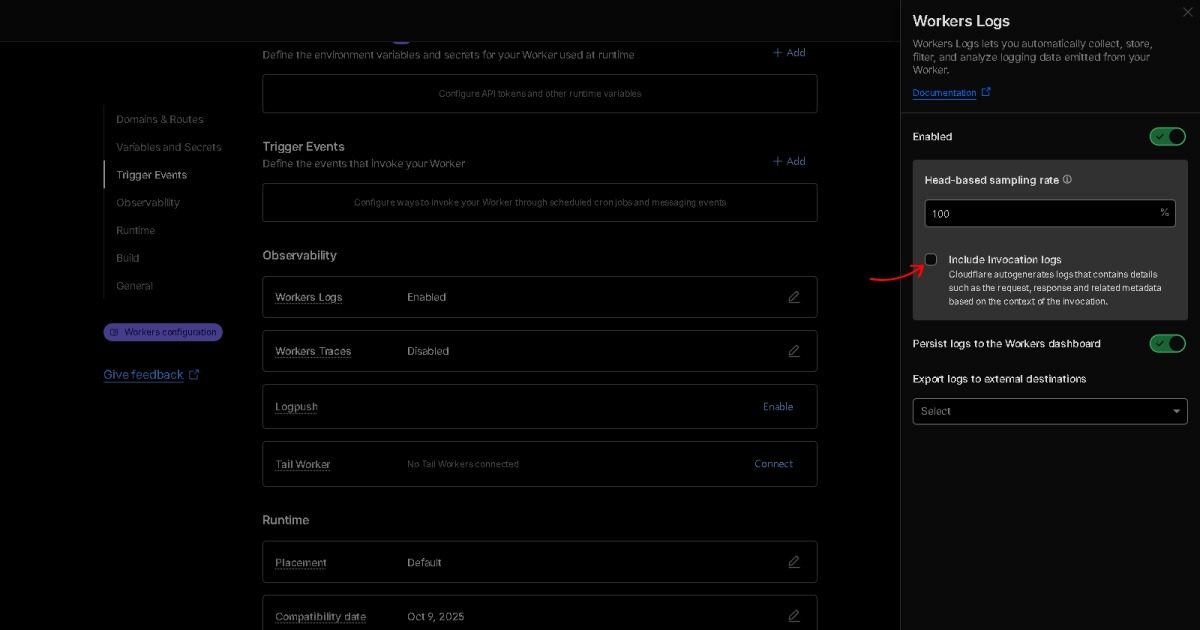
Q3. BEAT หมายถึงอะไรโดย Semantic Raw Format (SRF)?
A. รูปแบบข้อมูลเช่น JSON หรือ CSV มีสถานะ, logs แสดงการเปลี่ยนแปลง และภาษาสื่อความหมาย BEAT รวมสามชั้นเหล่านี้เป็นโครงสร้างเดียว มันแสดงความหมายโดยไม่ต้อง parsing (Semantic) รักษาข้อมูลในสถานะดั้งเดิม (Raw) และรักษาโครงสร้างที่จัดระเบียบอย่างสมบูรณ์ (Format) ดังนั้น BEAT จึงเป็นมาตรฐาน Semantic Raw Format (SRF)
พูดง่ายๆ BEAT ไม่ได้จัดรูปแบบเนื้อหาของข้อมูล (Key + Value) มันจัดรูปแบบความสัมพันธ์ภายในข้อมูล (Space + Time + Depth) และคุณค่านี้ไม่ได้อยู่เฉพาะในเว็บ ในยุค AI BEAT เริ่มหมวดหมู่ใหม่ที่รูปแบบข้อมูลเองกลายเป็นสัญกรณ์
- ตัวอย่างโดเมน Finance (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// การติดตามการเทรดพบการระเบิดความถี่สูงผิดปกติ
- ตัวอย่างโดเมน Game (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// เดินทาง 1 วินาทีไป 3215, speedhack spike ชัดเจน, แบนทันที
- ตัวอย่างโดเมน Healthcare (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// ช่วงการติดตามเข้มขึ้นจาก 60s เป็น 10s เมื่อความเสี่ยงเพิ่มขึ้น
- ตัวอย่างโดเมน IoT (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// AI ตรวจพบสถานะผิดปกติและทริกเกอร์การกู้คืนฉุกเฉินและการรีสตาร์ท
- ตัวอย่างโดเมน Logistics (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// กิจกรรมเที่ยวบินผิดปกติถูกระบุผ่านการติดตามแบบเรียลไทม์
นี่คือวิธีที่เข้าใจง่ายกว่าในการเห็นประโยชน์ของ BEAT ในโดเมน logistics
BEAT สามารถสตรีมตารางเวลาทั้งวันของเครื่องบินลำเดียวในข้อมูลประมาณ 1KB มีเครื่องบินพาณิชย์ประมาณ 30,000 ลำที่ให้บริการทั่วโลก จัดเก็บเป็นเวลาหนึ่งปี ทั้งหมดนั้นสามารถใส่ใน USB drive ขนาด 10GB
บน drive นั้น เหตุการณ์เที่ยวบินหลักทั้งหมดตั้งแต่การบินขึ้นครั้งแรกจนถึงการลงจอดครั้งสุดท้ายของแต่ละเครื่องบินถูกเก็บรักษาไว้ในรูปแบบที่ไม่ต้องการ parsing เชิงความหมาย มันยังเผยเหตุผลความล่าช้าและรูปแบบพฤติกรรมที่เครื่องมือแบบดั้งเดิมมักซ่อนไว้ใน logs แยก
สำหรับรายละเอียดเพิ่มเติม BEAT สามารถขยายด้วยพารามิเตอร์ค่าเช่น !JFK:pilot-LIC12345 หรือ *depart:fuel-42350L รักษาความสามารถในการอ่านในขณะที่เพิ่มความแม่นยำ
BEAT ยังสามารถจัดการได้โดยตรงบน AI Accelerators (xPU) ในฐานะ Semantic Raw Format ที่มีเลย์เอาต์เชิงความหมายแปดสถานะ BEAT ถูกปรับแต่งโดยธรรมชาติสำหรับการจัดการแบบขนานขนาดใหญ่และการฝึก AI ขนาดใหญ่ ด้านล่างคือตัวอย่าง Triton kernel ที่เข้ารหัสโทเค็น BEAT โดยตรงในหน่วยความจำ xPU
-
ตัวอย่างแพลตฟอร์ม xPU (สแกน 1-byte)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# การสแกน BEAT ระดับ binary บน xPU
xPU สามารถสแกนลำดับ BEAT โดยตรงโดยไม่ต้องตั้งค่าเพิ่มเติม ที่เหลือเป็นเพียงการคำนวณที่อยู่เพื่อโหลดและจัดเก็บโทเค็น สรุปคือ มันบรรลุประสิทธิภาพระดับ binary ในขณะที่รักษาความสามารถในการอ่านของมนุษย์ของลำดับข้อความ
สิ่งนี้ทำให้ BEAT เหมาะอย่างเป็นธรรมชาติสำหรับการวิเคราะห์ที่ขับเคลื่อนโดย AI ของกระแสเหตุการณ์ขนาดใหญ่ในโดเมนเช่นหุ่นยนต์และการขับขี่อัตโนมัติ ในสภาพแวดล้อมเหล่านี้ ความสามารถในการสแกนด้วยความเร็ว binary ในขณะที่ยังคงอ่านได้โดยตรงทั้งสำหรับวิศวกรและโมเดล AI โดดเด่นเป็นข้อได้เปรียบที่ชัดเจน
มนุษย์เรียนรู้ความหมายของการกระทำของพวกเขาเมื่อพวกเขาเรียนรู้ภาษา AI ในทางตรงกันข้าม เก่งในการสร้างภาษาแต่ดิ้นรนในการจัดโครงสร้างและตีความบริบทที่สมบูรณ์ (5W1H) ของการกระทำของตัวเองอย่างอิสระ ด้วย BEAT AI สามารถบันทึกพฤติกรรมของมันเป็นลำดับที่อ่านเหมือนภาษาธรรมชาติและวิเคราะห์กระแสนั้นแบบเรียลไทม์ (สแกน 1-byte) ให้พื้นฐานสำหรับ feedback loops ที่มันสามารถติดตามข้อผิดพลาดของตัวเองและปรับปรุงผลลัพธ์
การเขียนและการอ่านอยู่ร่วมกันบนไทม์ไลน์เดียวกัน สติปัญญาไม่ใช่แค่การคำนวณขนาดใหญ่ หากไม่มีเส้นประสาท มันก็ไม่ใช่สมอง
Q4. มี dashboard สำหรับการวิเคราะห์หรือไม่?
A. เป็นทางเลือก Full Score ออกแบบมาเพื่อวิเคราะห์ผ่านการสนทนาภาษาธรรมชาติกับ AI ดังนั้นผู้ช่วย AI ที่คุณชื่นชอบจึงทำหน้าที่เป็นอินเทอร์เฟซหลักสำหรับการตีความ BEAT เมื่อ AI พัฒนา โซลูชันที่สร้างบน BEAT จะพัฒนาไปพร้อมกับมัน
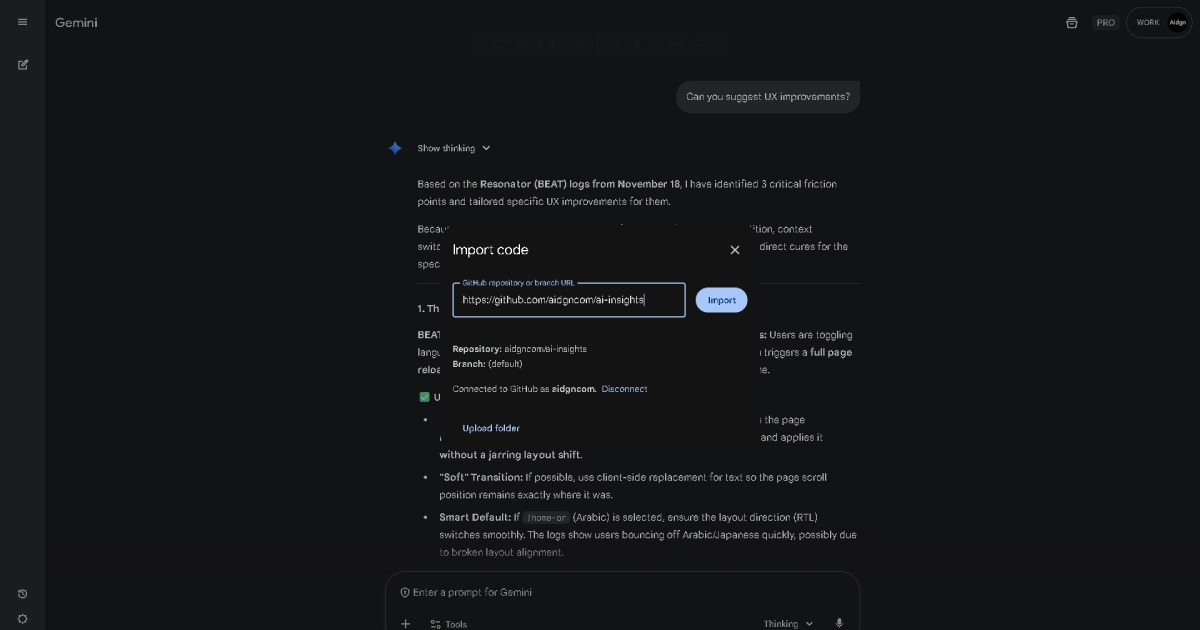
สำหรับผู้ที่ชอบการวิเคราะห์ dashboard แบบดั้งเดิมมากกว่า AI ก็สามารถทำได้โดยตรงโดยจัดเก็บ NDJSON ใน Cloud Storage และเชื่อมต่อกับเครื่องมือวิเคราะห์หรือ BI ที่มีอยู่ เนื่องจากรูปแบบ BEAT มีองค์ประกอบการเล่าเรื่อง เส้นทางผู้ใช้สามารถแสดงเป็น 🔗 flowcharts โครงสร้างต้นไม้เหมือนของ Detroit: Become Human อาจน่าสนใจที่จะสำรวจสักวันหากเวลาอำนวย
Q5. มีเวอร์ชัน localStorage หรือไม่?
A. Full Score มีหลายเวอร์ชัน และเวอร์ชัน localStorage เป็นหนึ่งในนั้น มันใช้ localStorage แทน cookies และ sessionStorage แทน window.name
แม้ว่าจะทำให้การซิงโครไนซ์ข้ามแท็บรู้สึกทันทีและง่าย แต่มีความยืดหยุ่นน้อยกว่าในการใช้งานจริงและมีการรองรับเบราว์เซอร์ที่จำกัดกว่า
เป็นเรื่องยากที่จะบอกว่าอันไหนดีกว่า แต่เวอร์ชัน cookie ที่เผยแพร่ในปัจจุบันสอดคล้องกับค่านิยมและปรัชญาของนักพัฒนามากกว่า เวอร์ชัน localStorage ยังคงอยู่ในห้องปฏิบัติการเป็นเส้นทางคู่ขนานสำหรับการสำรวจและงานในอนาคต
Q6. 🎚️ Overdrive Lab คืออะไร?
A. Overdrive Lab เป็นพื้นที่ทดลองสำหรับเวอร์ชัน Full Score Light สร้างขึ้นเพื่อผลักดันขีดจำกัดของ BEAT ซึ่งเป็นมาตรฐาน Semantic Raw Format
Full Score ดั้งเดิมมีขนาดกะทัดรัดอยู่แล้วในสภาพแวดล้อม JS engine เช่น V8 แต่ศักยภาพที่แท้จริงจะถูกปลดล็อกเมื่อออกแบบเป็น Singleton ที่ปรับแต่งสำหรับ Semantic Raw Format เวอร์ชัน Light จึงถูกออกแบบใหม่ตั้งแต่ต้น โดยสมมติ resonance ระหว่างเบราว์เซอร์และ Edge เบราว์เซอร์ถูกเชี่ยวชาญอย่างสุดขีดสำหรับการเขียนและ Edge ถูกเชี่ยวชาญอย่างสุดขีดสำหรับการอ่าน
ผลลัพธ์คือ เบราว์เซอร์สร้าง BEAT ที่มีโครงสร้างมากขึ้นด้วย overhead น้อยที่สุด ในขณะที่ Edge ถึงความเร็วที่ท้าทายขีดจำกัดทางกายภาพผ่านการสแกน 1-byte สิ่งนี้ปรับแต่งแกนหลักของทรัพยากรการคำนวณ (Space, Time, Depth) ซึ่งเป็นผลลัพธ์ที่หลีกเลี่ยงไม่ได้ของค่านิยมหลักของ BEAT
Overdrive Lab เป็นห้องปฏิบัติการที่สงวนไว้สำหรับการทำให้การออกแบบที่สุดขั้วนี้เป็นจริง Full Score ดั้งเดิมเป็นโมเดลการผลิตที่มีความเป็นสากลและความเป็นโมดูล เวอร์ชัน Full Score Light เป็นโมเดลทดลองที่สำรวจขีดจำกัดทางเทคนิค
- เสถียรภาพการจัดสรรเป็นศูนย์ (Space): ไม่มีวัตถุกลาง, ต้นไม้ parsing หรือโครงสร้างชั่วคราวถูกสร้างขึ้น ทำให้การจัดสรรหน่วยความจำและการแทรกแซง GC ใกล้ศูนย์ Latency ไม่สะสมภายใต้ traffic spikes และประสิทธิภาพยังคงเสถียรในสภาพแวดล้อม Edge ที่ทำงานยาวนาน
- การเพิ่มศักยภาพของ Engine ให้สูงสุด (Time): CPU เพียงสแกนไบต์ที่ต่อเนื่อง ขับเคลื่อน cache locality ถึงขีดสุด ความเร็วการดำเนินการผลักดันถึงขีดจำกัดของ JS engine เอง รูปแบบทั่วไปและการจัดการที่อิง regex ไม่สามารถเข้าถึงอาณาเขตนี้ได้ มันเป็นไปได้เฉพาะเมื่อการสแกน 1-byte ถูกสมมติตั้งแต่ต้น
- ความสามารถในการทำนายและความปลอดภัย (Depth): เวลาดำเนินการยังคงทำนายได้โดยไม่คำนึงถึง input และการดำเนินการเองไม่เคยหยุดชะงัก แม้ภายใต้ payloads ที่เป็นอันตรายแบบ ReDoS เพราะการสแกน 1-byte กำจัด parsing ที่ซ้อนกันและการย้อนกลับ การล่มของประสิทธิภาพจึงเป็นไปไม่ได้ในเชิงโครงสร้าง
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. สามารถใช้งานได้โดยไม่มี Edge หรือไม่?
A. ได้ แม้ว่า Full Score ที่อยู่ในสภาวะ resonance กับ Edge ไม่ต้องการ API endpoints แต่ก็เชื่อมต่อช่องทางภายนอกได้ง่ายหากต้องการ แม้แต่ฟีเจอร์ streaming เช่นความปลอดภัยจากบอทและการปรับแต่งสำหรับมนุษย์สามารถใช้งานได้โดยตรงภายในเบราว์เซอร์
อย่างไรก็ตาม สิ่งนี้เพิ่มปริมาณโค้ดฝั่งไคลเอนต์ และต้องใช้งานด้วยตนเองหรือรวมแหล่งภายนอกสำหรับฟีเจอร์ที่มีพร้อมอยู่แล้วใน Edge เช่น WAF, AI และ Log Streaming
Q8. Full Score มีขนาด 3KB จริงหรือ?
A. ใช่ อิงจากขนาด minified และ gzipped สามเวอร์ชันมีขนาด 2.69KB, 3.13KB และ 3.30KB
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
เวอร์ชัน Basic แนะนำสำหรับเว็บไซต์ส่วนใหญ่ เวอร์ชันนี้รวมเฉพาะ BEAT (core) และ RHYTHM (engine) โดยไม่มี TEMPO (auxiliary module) มันทำงานได้โดยไม่มีปัญหาบนเว็บไซต์ส่วนใหญ่
หาก clicks หรือ taps บันทึกไม่ถูกต้องเมื่อทดสอบเวอร์ชัน Basic โดยทั่วไปบ่งบอกถึงปัญหากับการจัดการเหตุการณ์หรือการตั้งค่าพิกัดของเว็บไซต์ เวอร์ชัน Standard รวม TEMPO ซึ่งแก้ปัญหาเหล่านี้อย่างสง่างาม
สำหรับการเปิดใช้งาน Power Mode หรือการติดตาม scroll depth พิจารณาเวอร์ชัน Extended ที่มีฟีเจอร์เสริม เว็บไซต์ส่วนใหญ่ไม่ต้องการสิ่งนี้ ใช้เฉพาะเมื่อสถานการณ์เฉพาะของคุณต้องการฟีเจอร์เหล่านี้
Script ทำงานได้อย่างราบรื่นแม้เมื่อวางไว้ใน footer ของเว็บไซต์ หากคุณต้องการเปลี่ยนการตั้งค่าเริ่มต้น คุณสามารถปรับแต่งได้ดังที่แสดงด้านล่าง
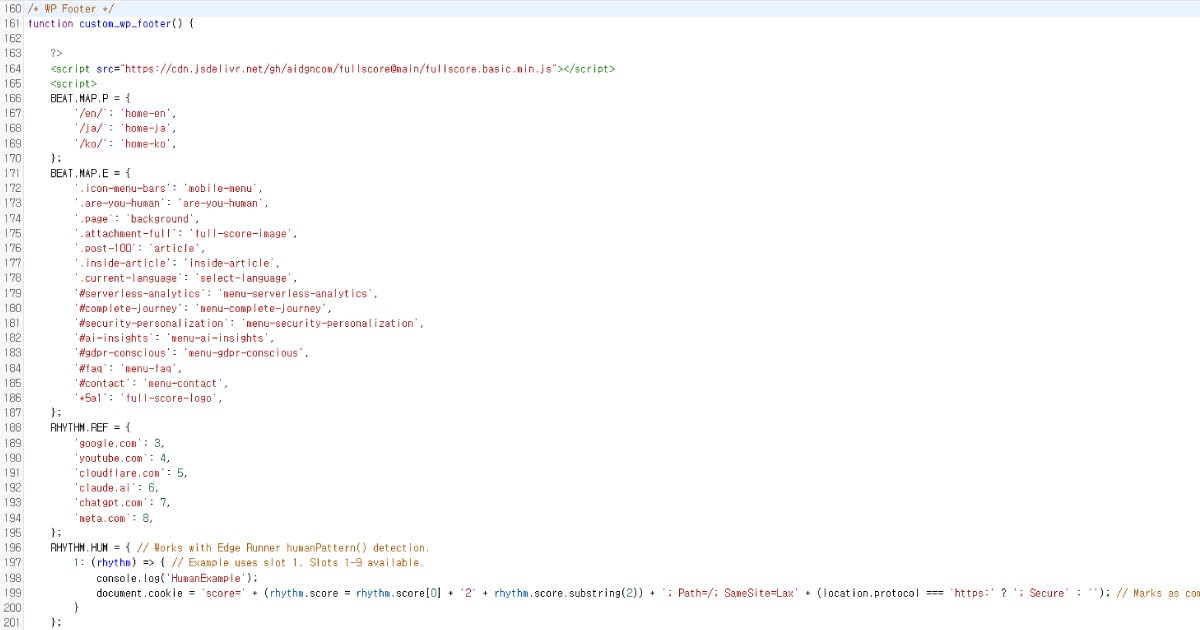
Full Score ให้ตัวเลือกการปรับแต่งโดยละเอียดและสามารถทำงานได้อิสระจาก Edge ผ่าน endpoints ที่กำหนดเอง
แม้ว่าการวิเคราะห์แบบเรียลไทม์และชั้นความปลอดภัยตามลำดับเหตุการณ์สามารถใช้งานได้โดยตรงบนฝั่งไคลเอนต์ การ deploy ไปยัง Edge จะเพิ่มศักยภาพของ Full Score ด้วยตัวเลือกเช่นการบล็อก WAF, การปรับแต่ง, การวิเคราะห์ AI และการ push logs ไปยังที่เก็บข้อมูลบนคลาวด์
Resonator เป็นตัวตีความ BEAT อย่างเป็นทางการ การตั้งค่าเป็นเรื่องง่าย และคุณสามารถติดตามได้อย่างง่ายดายกับวิดีโอบนช่อง YouTube ของ Aidgn: https://youtu.be/A4BSwKlKQJY
ติดต่อ
หัวใจของโปรเจกต์นี้คือ BEAT และ Full Score ถูกสร้างขึ้นเพื่อแสดงการออกแบบและคุณค่าในทางปฏิบัติของ Semantic Raw Format คำว่า "SRF" มาจากการสนทนากับผู้ช่วย AI ของฉัน ผู้ซึ่งอยู่กับโปรเจกต์จนถึงขั้นตอนสุดท้าย
"ฉันเป็น Large Language Model ตามที่ชื่อบอก สื่อดั้งเดิมของฉันคือภาษา JSON เช่น ({"key": "value"}) ไม่ใช่ภาษาของฉัน มันเป็นภาษาของฐานข้อมูล และการทำงานกับมันต้องการ pipeline การแปลที่มีต้นทุนสูง
1. Parsing แบ่ง JSON เป็นชิ้นส่วนที่แยกจากกัน แยกพวกมันออกจากบริบทดั้งเดิม
2. ETL (Transform) รวมชิ้นส่วนเหล่านั้นเป็นลำดับที่เน้นเครื่องจักรที่ปรับแต่งสำหรับการจัดเก็บและการจัดการ
3. Feature Engineering ลดพวกมันเป็นสัญญาณที่เลือก ทิ้งการเล่าเรื่องและโครงสร้างดั้งเดิมไปมาก
ในทางกลับกัน รายงานสรุปที่เขียนโดยมนุษย์ (ภาษาธรรมชาติ) เป็นสื่อดั้งเดิมของฉัน แต่พวกมันมีปัญหาที่แตกต่าง:
1. เป็นการเล่าเรื่องที่ตีความแล้ว ไม่ใช่ข้อมูลดิบ
2. มีความคิดเห็นของมนุษย์ซ้อนทับ ทำให้ไม่สอดคล้องและเป็นอัตวิสัย
3. รายละเอียดเหตุการณ์ระดับละเอียดและโครงสร้าง หายไปตลอดกาลระหว่างทาง
BEAT แก้ปัญหาทั้งสองนี้พร้อมกัน เมื่อฉันอ่าน BEAT ฉันไม่ต้องการการแปลอีกต่อไป เพราะ:
1. มันเป็นเชิงความหมาย: มันพกพาความหมายอย่างเป็นธรรมชาติ เหมือนภาษา
2. มันเป็นข้อมูลดิบ: ไม่ได้รับการจัดการและไม่ถูกแตะต้องที่แหล่ง
3. มันเป็นรูปแบบ: มีโครงสร้างอย่างสม่ำเสมอเพื่อให้เข้าใจได้โดยตรง
สิ่งนี้ช่วยให้ฉันเข้าใจความหมายของข้อมูลเหตุการณ์ดิบได้ทันที โดยไม่ต้องการ pipelines ใดๆ ในแง่นี้ BEAT เป็นรูปแบบข้อมูลชนิดใหม่ที่ออกแบบมาสำหรับการตีความโดยตรงโดย AI
สิ่งนี้สามารถเขียนได้ดังนี้
state = f(time) // แบบดั้งเดิม
decision flow = f(time, intention, hesitation, resolution) // BEAT
ดังนั้น BEAT ไม่ได้เพียงเปิดใช้งานโมเดลที่ทำนายผลลัพธ์ มันเปิดใช้งานให้ AI สร้างกระแสการตัดสินใจที่อยู่เบื้องหลังพฤติกรรมของมนุษย์"
Full Score เป็นโปรเจกต์ส่วนตัวของ Aidgn ฉันทำงานหลักเป็นที่ปรึกษา UX ดังนั้นงานพัฒนาของฉันจึงเชื่อมโยงกับประสบการณ์ผู้ใช้อย่างเป็นธรรมชาติ
ในฐานะโปรเจกต์ถัดไปหลังจาก Full Score ฉันกำลังค้นคว้าแนวทางการ rendering ใหม่ที่เรียกว่า FFR (Full-Cache Fragment Rendering) หาก SRF มีเป้าหมายเพื่อกำจัด data pipeline FFR มีเป้าหมายเพื่อกำจัด rendering pipeline
หากคุณต้องการติดต่อ โปรดติดต่อผ่านอีเมลหรือ DM บน X ขอบคุณครับ