
Full Score — это библиотека размером 3KB (gzip), легковесная бессерверная аналитика с прямым ИИ-анализом и гроус-хакингом. Основанная на Semantic Raw Format (SRF), она реализует эффективную архитектуру, позволяющую ИИ анализировать пути пользователей напрямую без семантического парсинга и обсуждать результаты с вашим ИИ-ассистентом (Gemini, Claude, GPT, Grok и др.).
Этот сайт демонстрирует живую работу Full Score. Путь, отображаемый внизу, имеет тот же формат, что и данные взаимодействия, которые Edge реально анализирует. Он течёт естественно, как музыка в резонансе.
Вот оркестрованные возможности. Нажмите, чтобы исследовать каждую часть.
- 🧭 Бессерверная аналитика: Без API Endpoints и потенциал снижения затрат на 90%
- 🔍 Полный путь пользователя через вкладки: Без Session Replay
- 🧩 Защита от ботов и персонализация для людей: Через слой событий в реальном времени
- 🧠 BEAT перетекает в инсайты ИИ: Как линейные строки, без семантического парсинга
- 🛡️ Архитектура с учётом GDPR: С нулевыми прямыми идентификаторами
Всё это достигается превращением браузеров в децентрализованные вспомогательные базы данных.
Это демо фокусируется на живой работе, предлагая быстрый и интуитивный обзор. Если это резонирует с вами, обратитесь к 🔗 README на GitHub и комментариям в коде для полных технических деталей.
1. Бессерверная аналитика: Без API Endpoints и потенциал снижения затрат на 90%
Традиционные платформы аналитики, созданные для анализа веб-трафика, session replay и отслеживания когорт, отлично справляются со своими задачами. Однако получение инсайтов о пользователях обычно требует тяжёлой и сложной инфраструктуры.
Они полагаются на объёмные event payloads и снимки DOM, все передаваемые на централизованные серверы для хранения и вычислений. Это приводит к script payloads в десятки килобайт, миллионам сетевых запросов и ежемесячным затратам на инфраструктуру в тысячи долларов.
Full Score не пытается решить эту сложность. Он устраняет её полностью, предлагая новый подход.
- Традиционная аналитика
Браузер → API → Raw Database → Queue (Kafka) → Transform (Spark) → Refined Database → Архив
⛔ 7 шагов, $500 – $5,000/месяц (зависит от payload)
- Full Score
Браузер ~ Edge → Архив
✅ 2 шага, $50 – $500/месяц// Не нужны API endpoints
// Не нужен ETL pipeline
// Не нужен доступ к Origin
Всё начинается с простого осознания. Получение инсайтов о полном пути навигации пользователя не всегда требует передачи данных куда-то ещё.
Каждый браузер уже предоставляет хранилище вроде first-party cookies и localStorage. Что если инсайты записывались бы сначала туда, а интерпретировались только один раз, в момент, когда работа пользователя в браузере считается завершённой?
Превращая каждый браузер в инфраструктуру, необходимость в сложных централизованных бэкендах исчезает. Миллиард пользователей становится как миллиард децентрализованных баз данных, каждая хранящая свои собственные сырые данные.
Конечно, мало кто принял бы этот подход, потому что протоколы передачи данных крайне ограничены. Event payloads и снимки DOM слишком тяжёлые, поэтому даже однократная отправка данных всё ещё требует слоёв Queue и Transform.
Вот почему Full Score использует BEAT, новый формат данных. BEAT имеет меньший структурный оверхед, чем традиционные форматы данных, поэтому он легче и не требует очередей или слоёв трансформации. Записывая последовательности событий как линейные строки, сырые данные становятся музыкой, естественно читаемой как людьми, так и ИИ.
А резонанс с Edge computing завершает историю.
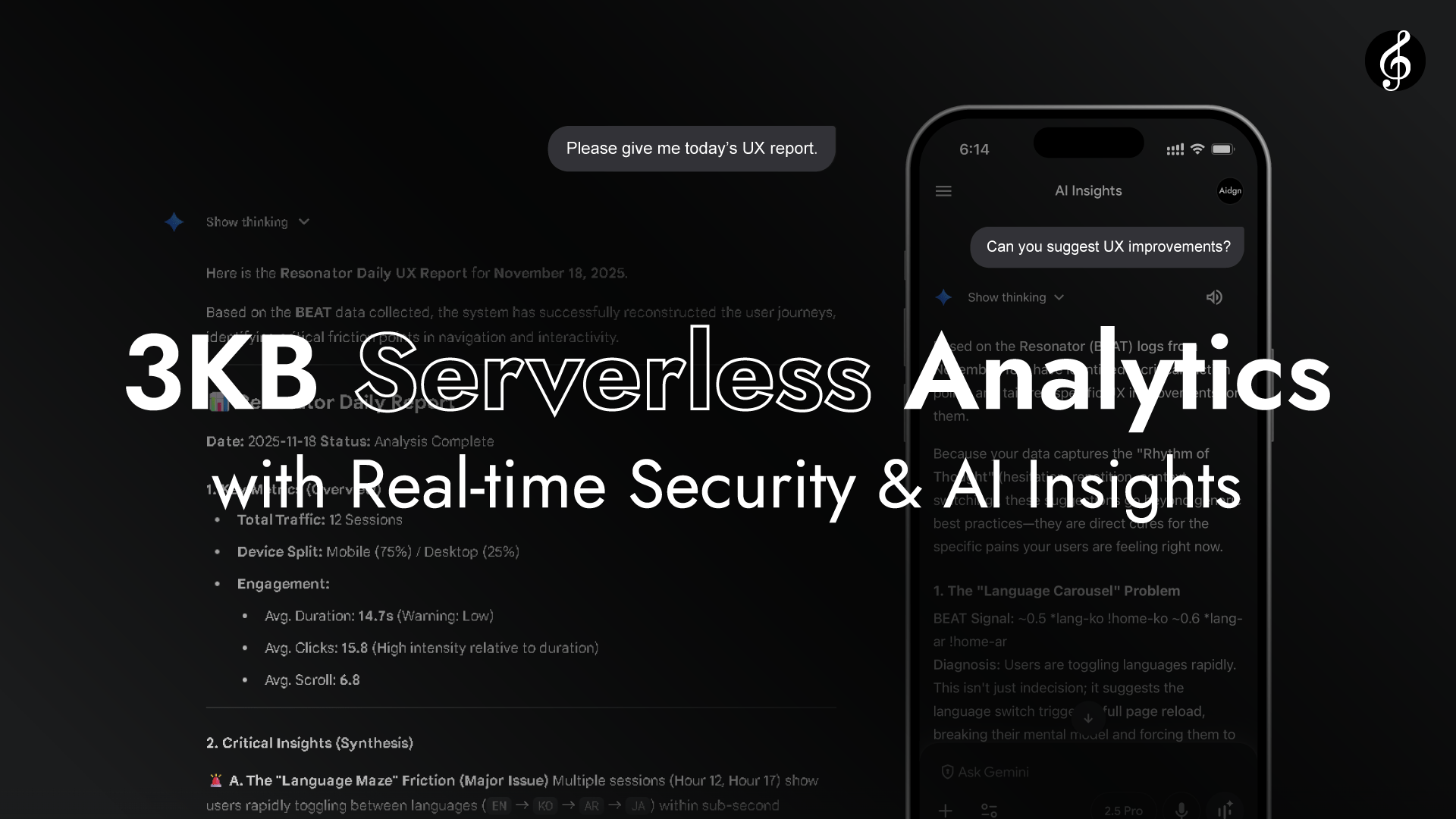
Как показывает видео, Edge превращает Full Score в слой аналитики в реальном времени без необходимости API endpoints. Edge читает заголовки запросов от каждого браузера.
Не требуется доступ к Origin. Работа завершается через естественный резонанс между браузером и Edge, быстро, живо и самодостаточно. Задержка незаметно мала.
Поскольку браузер и Edge так близки в пространстве и времени, их связь больше напоминает резонанс, чем передачу, как слушать музыку, текущую по воздуху.
Для сайтов, тратящих $500–5,000/месяц на аналитику, Full Score обычно работает примерно за $50/месяц за Edge computing и облачное архивирование вместе. С инсайтами ИИ в реальном времени на Edge затраты могут масштабироваться до примерно $500/месяц. Это консервативная оценка, и реальные затраты могут варьироваться в зависимости от вашей среды. Его децентрализованный дизайн на основе Edge поддерживает стабильные затраты по мере масштабирования трафика.
Full Score использует другую структуру данных и поток, чем традиционные подходы, делая его мощным партнёром, а не полной заменой существующих слоёв аналитики или безопасности. Он работает наиболее эффективно вместе с платформами вроде Edge-аналитики и WAF.
2. Полный путь пользователя через вкладки: Без Session Replay
Традиционная аналитика делает анализ через вкладки сложным и неполным. Он требует сложного pipeline, включающего сбор идентификаторов, сессионизацию, загрузку данных, joins, пост-обработку и синхронизацию в реальном времени.
Full Score рассматривает браузеры как вспомогательные базы данных, поэтому полные пути, включая навигацию через вкладки, записываются немедленно. С одним промптом ИИ может интерпретировать эти данные напрямую, устраняя весь pipeline сбора идентификаторов, сессионизации, загрузки данных, joins, пост-обработки и синхронизации в реальном времени.
Нажмите кнопку ниже, чтобы открыть новую вкладку и протестировать самостоятельно.
В данных RHYTHM демо вы можете видеть навигацию по вкладкам в формате (@---N).
Full Score поддерживает до 7 вкладок по умолчанию. Когда открывается 8-я вкладка, существующие данные автоматически архивируются и начинается новый набор. Все сессии группируются вместе в один момент как один полный снимок.
Даже если группировка происходит более одного раза из-за определённых условий, все сессии разделяют одинаковую временную метку и хеш, позволяя восстановить весь путь как единую непрерывную последовательность.
Однако открытие 8+ вкладок одновременно редкость. Это вероятно указывает на аномальные паттерны поведения ботов.
Full Score элегантно решает эту задачу. 🔗 При резонансе с Edge он обеспечивает безопасность и персонализацию в реальном времени.
3. Защита от ботов и персонализация для людей: Через слой событий в реальном времени
Начнём с простого теста. Нажмите кнопку ниже либо в темпе бота (быстрые, механические нажатия), либо в человеческом темпе (несовершенные, естественные нажатия).
Этот тест может кратковременно вызвать Managed Challenge, который очищается примерно за 30 секунд.
Видите, как поле movement меняется с (0000000000) на (1000000000), (2000000000), или (0100000000), (0200000000)? Это Full Score работает с Edge для анализа поведения в реальном времени.
Традиционное обнаружение ботов полагается на блокировку IP, CAPTCHA и fingerprinting. Но умные боты обходят их. Full Score использует другой подход, наблюдая за паттернами поведения, чтобы ловить ботов, которые пытаются действовать как люди, но выдают себя через неестественные действия вроде кликов без скроллинга.
Для реальных пользователей это обеспечивает персонализированный пользовательский опыт. Кто-то кликнул добавить в корзину три раза быстро? Покажите им сообщение помощи. Кто-то долго просматривает? Покажите им скидку.
В следующем разделе представлены характеристики читаемости BEAT для ИИ. Но как показали примеры до сих пор, данные событий, выраженные через BEAT, уже имеют ясную практическую ценность сами по себе. Использование Full Score только для безопасности и персонализации в реальном времени тоже обоснованный выбор.
4. BEAT перетекает в инсайты ИИ: Как линейные строки, без семантического парсинга
BEAT (Behavioral Event Analytics Transcript) это выразительный формат для многомерных данных событий, включая пространство, где происходят события, время, когда происходят события, и глубину каждого события как линейные последовательности. Эти последовательности выражают значение без парсинга (Semantic), сохраняют информацию в её исходном состоянии (Raw) и поддерживают полностью организованную структуру (Format). Поэтому BEAT это стандарт Semantic Raw Format (SRF).
BEAT достигает производительности на бинарном уровне (сканирование 1 байт) при сохранении человеческой читаемости текстовой последовательности. BEAT определяет шесть основных токенов внутри семантической раскладки из восьми состояний (3 бита). Выровненные с 5W1H, они полностью захватывают намерение архитектур, спроектированных людьми, оставляя два состояния для доменных расширений. Вместе они формируют основную нотацию формата BEAT.
Нижнее подчёркивание (_) один пример токена расширения, используемого для сериализации и выражения мета-полей, таких как _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. Эти мета-поля аннотируют последовательности BEAT без изменения их основного формата при сохранении производительности сканирования 1 байт.
🔗 Для детальных объяснений формата BEAT смотрите README на GitHub.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
Множественные последовательности BEAT могут быть записаны в формате строк, совместимом с NDJSON, с каждым путём на одной строке. Это сохраняет логи компактными, делает запросы простыми и улучшает эффективность анализа ИИ. В средах Finance, Game, Healthcare, IoT, Logistics и других семантически полный поток BEAT позволяет быстрое слияние и лёгкую совместимость с их соответствующими форматами.
Конечно, это представление в стиле NDJSON опционально. Те же данные могут быть выражены в упрощённом формате BEAT при сохранении его производительности сканирования 1 байт, например: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Здесь эмодзи 🔎 выделяет позиции сразу после каждого токена сканирования 1 байт.
Цель этого представления уважать традиционные форматы данных, включая JSON, и сервисы, построенные вокруг них (такие как BigQuery), чтобы BEAT мог быть принят легко и сосуществовать с ними, а не пытаться заменить их.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
Инсайты ИИ
[CONTEXT] Мобильный пользователь, визит Mapped(5), 56 скроллов, 15 кликов, 1205.2 секунд
[SUMMARY] Запутанное поведение. Попал на главную страницу, колебался в разделе помощи с повторными кликами с интервалами 37 и 12 секунд. Перешёл на страницу продукта, открыл детали в новой вкладке, просматривал изображения около 240 секунд. Нажал кнопку покупки три раза с интервалами 1.3, 0.8 и 0.8 секунд. Вернулся к первой вкладке и открыл корзину вскоре после, но не перешёл к оформлению заказа.
[ISSUE] Корзина достигнута, но покупка не завершена. Повторные действия покупки могут отражать либо намеренное добавление нескольких товаров, либо трение в выборе опций. Длительная задержка перед оформлением заказа предполагает неопределённость.
[ACTION] Оценить, представляют ли повторные действия покупки или корзины намеренное сравнительное поведение или трение при оформлении заказа. Если трение вероятно, упростить обработку опций и выделить ключевые детали продукта раньше в потоке.
Традиционные форматы данных, включая JSON, подобны точкам. Они отлично подходят для организации и разделения отдельных событий, но понимание того, какую историю они рассказывают, требует парсинга и интерпретации.
BEAT подобен линии. Он захватывает те же данные, что и JSON, но поскольку путь пользователя течёт как музыка, история становится ясной сразу.
BEAT выражает свои семантические состояния, используя только токены Printable ASCII (0x20 до 0x7E), которые плавно проходят через слои вычислений и безопасности. Отдельная кодировка или декодировка не требуется, и поскольку он достаточно мал, чтобы жить в нативном хранилище, анализ в реальном времени работает без задержки в большинстве сред.
Итак, BEAT это сырые данные, но также самодостаточные. Семантический парсинг не нужен. Это звучит грандиозно, но на самом деле нет. Выразительный формат BEAT вдохновлён самым распространённым форматом данных в мире. Самым древним форматом данных в истории человечества. Естественным языком.
А ИИ эксперт в понимании естественного языка.
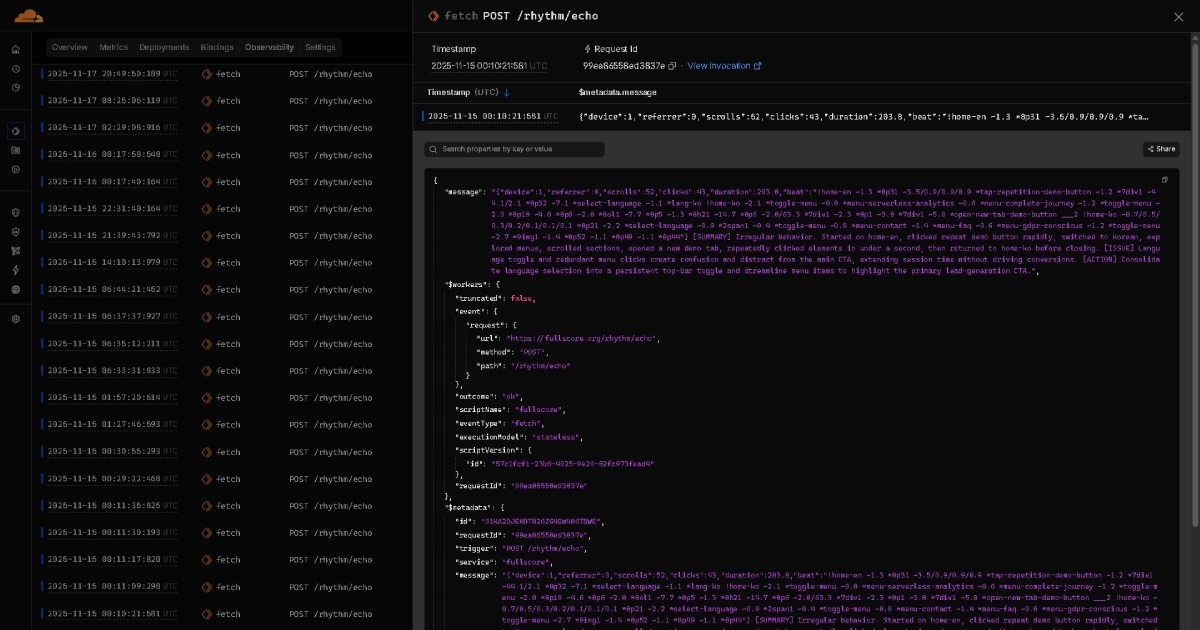
Данные, резонирующие от Full Score к Edge, становятся отчётами с инсайтами в реальном времени через лёгкий ИИ (например, модели класса GPT OSS 20B). Эти отчёты затем архивируются на платформы хранения вроде GitHub, организованные по дате.
Все эти накопленные данные поступают к вашему ИИ-ассистенту. Это создаёт поток совместной работы ИИ-к-ИИ, где лёгкий ИИ создаёт отчёты для каждого запуска или сессии, а продвинутый ИИ синтезирует комплексные инсайты из всех отчётов. Дашборды опциональны, и людям не требуется анализировать их вручную. Со временем модели могут стать достаточно сильными, чтобы весь этот поток завершался за один проход, без явного шага совместной работы ИИ-к-ИИ вообще. По мере развития ИИ решения, построенные на BEAT, развиваются вместе с ним.
Начните разговор.
"Какие паттерны путей пользователей движут конверсии?"
"Какие-нибудь заметные ISSUE сегодня?"
"Можете предложить идеи гроус-хакинга на основе точек трения UX?"
5. Архитектура с учётом GDPR: С нулевыми прямыми идентификаторами
Основная реализация Full Score использует first-party cookies как хранилище данных. Хотя версия localStorage существует, cookies предлагают функциональное преимущество, поскольку они автоматически включаются в заголовки HTTP-запросов. Это позволяет Edge читать их немедленно.
First-party cookies фундаментально отличаются от third-party tracking cookies, часто отмечаемых в аналитике. Full Score хранит данные только в браузерах пользователей и резонирует естественно с Edge без API endpoints, фактически уменьшая экспозицию по сравнению с традиционными подходами аналитики.
Записываются только простые паттерны, не чувствительная персональная информация (PII). В семантике BEAT "Who" не относится к пользователю. Как определено через ! = Contextual Space (who), идентичность выводится из самого пространства. Пользователь в !military понимается через контекст солдата, а пользователь в !hospital через контекст врача или пациента. Он никогда не спрашивает индивида: "Кто ты?"
Этот подход естественно распространяется на безопасность. Full Score спроектирован не вокруг традиционной передачи, где владение данными переходит к серверу, а вокруг структуры, в которой владение данными остаётся с пользователем (браузером), пока резонанс происходит на Edge.
В конфигурации на основе резонанса всё начинается и заканчивается между браузером и Edge, никогда не касаясь сервера происхождения для аналитики. Поэтому даже если сам сайт скомпрометирован через XSS или подобную атаку инъекции, почти нет шансов, что эти данные будут существовать на сервере происхождения в форме, которую атакующий мог бы значимо украсть. Даже в худшем сценарии, когда данные, архивированные с Edge во внешнее хранилище вроде GitHub, скомпрометированы, то, что хранится это только простые поведенческие логи, которые эффективно бессмысленны сами по себе. Другой теоретический путь это атаковать каждый браузер индивидуально, как если бы он был частью большой распределённой базы данных, но на практике этот вектор атаки очень трудно выполнить.
Для детального руководства по соответствию GDPR и ePD смотрите раздел FAQ ниже.
FAQ
Q1. Почему Full Score использует термин "резонанс"? Разве передача HTTP-заголовков это не всё ещё передача?
A. Понимание этого требует рассмотрения владения данными. Вот иллюстрация для объяснения.
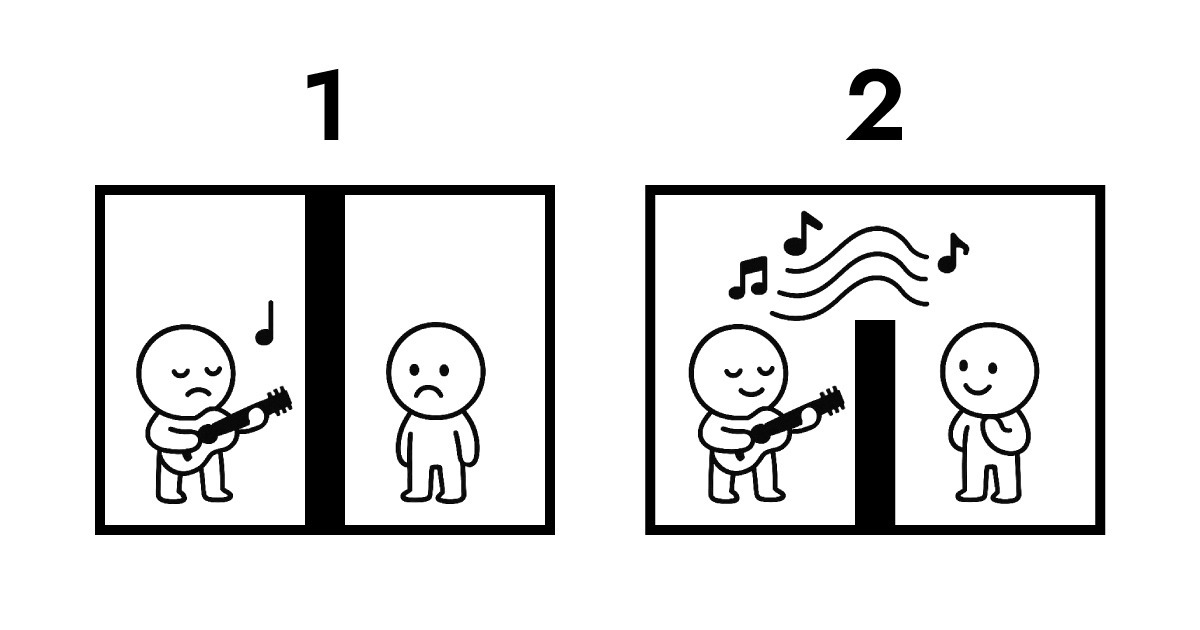
Первое изображение показывает традиционную передачу. Две стороны полностью изолированы друг от друга. Чтобы B услышал выступление A, передача по протоколу становится неизбежной. Во время этого обмена владение данными переходит от A к B и сохраняется на сервере. Без сохранения просто нет способа для B услышать выступление A.
Второе изображение показывает резонанс между Full Score и Edge. Между ними всё ещё есть стена, которую нельзя физически пересечь, но B может слушать выступление A в реальном времени. На протяжении всего этого взаимодействия владение данными остаётся у A.
Это именно то, что Edge computing позволяет как бессерверная архитектура. Edge не нужно получать и хранить данные, как традиционному серверу. Вместо этого он интерпретирует и отвечает немедленно на сетевом слое, ближайшем к пользователям. Проще говоря, Full Score создаёт структуру, где владение данными остаётся у пользователя (браузера), обеспечивая при этом почти мгновенное взаимодействие.
Вот почему Full Score выбрал "резонанс" как свою музыкальную метафору. Вместо фокуса на физической механике, он центрируется на логической архитектуре, показанной выше.
Q2. Нужно ли мне согласие на cookies для соответствия GDPR и ePD?
A. Это тема, требующая юридической консультации в зависимости от юрисдикции и политик сайта. Пожалуйста, поймите, что этот ответ основан на личном опыте и суждении.
Ответ зависит не от самого Full Score, а от пользовательской конфигурации Edge, который резонирует с ним.
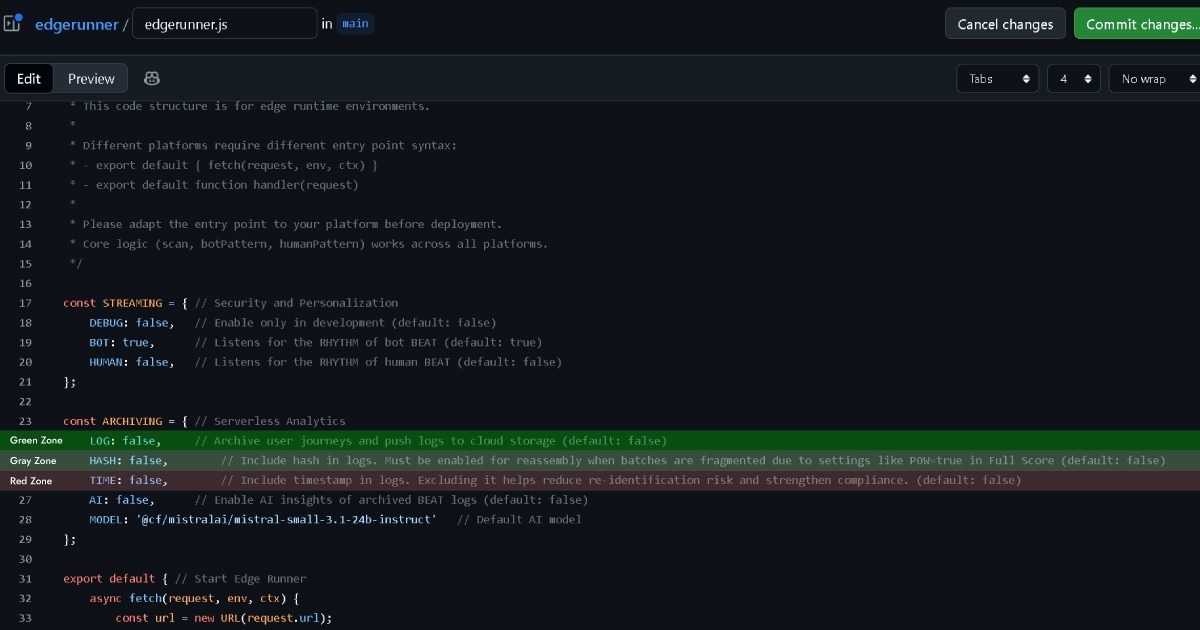
GDPR требует правовых оснований при сборе или обработке идентифицируемых персональных данных. ePD требует согласия пользователя при сохранении информации в или доступе к хранилищу браузера, включая cookies. Однако она признаёт исключение под названием "строго необходимые" для cookies, которые строго необходимы для функциональности.
Как объяснено ранее, Full Score использует first-party cookies, где владение данными остаётся у пользователя (браузера), фундаментально отличаясь от third-party cookies. При объединении с Edge он работает как слой безопасности и персонализации на бессерверном уровне.
Поэтому, если Edge поддерживает владение данными у пользователя (браузера), даже не сохраняя логи, это приближается к зелёной зоне. Full Score не собирает идентифицируемые персональные данные, покрытые GDPR, при соответствии критериям строго необходимых cookies ePD.
Однако, если конфигурация Edge устанавливает (LOG: true) для сбора и обработки данных событий для анализа, это решение должно быть принято тщательно.
Full Score спроектирован для поддержания полной анонимизации без какой-либо персонально идентифицируемой информации (PII). Однако GDPR покрывает не только прямую идентификацию, но и данные с потенциалом непрямой идентификации. При сопоставлении с другими записями Edge вроде IP-адресов или строк User-Agent, некоторый уровень потенциала идентификации может существовать.
Вот почему Edge включает опции для удаления записей временных меток и хеша перед логированием. Таким образом, даже при сопоставлении с другими записями Edge, потенциал непрямой идентификации эффективно исчезает. Это помещает его в серую зону, ближе к зелёной.
Сохранение хеша включённым остаётся в серой зоне, но включение временных меток может войти в красную зону и оправдывает юридическую консультацию.
Однако эти классификации Серой Зоны и Красной Зоны основаны на очень консервативной оценке. Когда Edge настроен на отключение логирования IP-адресов и строк User-Agent, практически не остаётся способа непрямой идентификации индивида.
Q3. Что означает BEAT как Semantic Raw Format (SRF)?
A. Форматы данных вроде JSON или CSV содержат состояние, логи представляют изменение, а язык передаёт значение. BEAT объединяет эти три слоя в единую структуру. Он выражает значение без парсинга (Semantic), сохраняет информацию в её исходном состоянии (Raw) и поддерживает полностью организованную структуру (Format). Поэтому BEAT это стандарт Semantic Raw Format (SRF).
Проще говоря, BEAT не форматирует содержимое данных (Key + Value). Он форматирует отношения внутри данных (Space + Time + Depth). И эта ценность не остаётся в рамках веба. В эпоху ИИ BEAT начинает новую категорию, где сам формат данных становится нотацией.
- Пример домена Finance (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// Мониторинг трейдинга сигнализирует аномальные высокочастотные всплески
- Пример домена Game (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// Перемещение за 1 секунду на 3215, явный пик speedhack, немедленный бан
- Пример домена Healthcare (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Интервал мониторинга сужен с 60с до 10с при эскалации риска
- Пример домена IoT (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// ИИ обнаружил аномальное состояние и запустил аварийное восстановление и перезапуск
- Пример домена Logistics (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Аномальная активность рейса выявлена через мониторинг в реальном времени
Вот более интуитивный способ увидеть преимущества BEAT в домене логистики.
BEAT может передавать полное дневное расписание одного самолёта примерно в 1KB данных. В мире примерно 30,000 коммерческих самолётов в эксплуатации. Заархивированное за год, всё это помещается на USB-накопитель 10GB.
На этом накопителе все ключевые события полётов от первого взлёта до финальной посадки каждого самолёта сохранены в форме, которая не требует семантического парсинга. Он также раскрывает причины задержек и поведенческие паттерны, которые традиционные инструменты часто скрывают в отдельных логах.
Для дополнительных деталей BEAT может быть расширен параметрами значений вроде !JFK:pilot-LIC12345 или *depart:fuel-42350L, сохраняя читаемость при добавлении точности.
BEAT также может обрабатываться нативно на ИИ-ускорителях (xPU). Как Semantic Raw Format с семантической раскладкой из восьми состояний, BEAT изначально оптимизирован для массивной параллельной обработки и крупномасштабного обучения ИИ. Ниже пример ядра Triton, которое кодирует токены BEAT напрямую в памяти xPU.
-
Пример платформы xPU (сканирование 1 байт)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# Сканирование BEAT на бинарном уровне на xPU
xPU может сканировать последовательности BEAT напрямую без какой-либо дополнительной настройки. Остальное просто адресная арифметика для загрузки и сохранения токенов. Короче говоря, он достигает производительности на бинарном уровне при сохранении человеческой читаемости текстовой последовательности.
Это делает BEAT естественным выбором для ИИ-управляемого анализа крупномасштабных потоков событий в доменах вроде робототехники и автономного вождения. В этих средах его способность сканироваться на бинарной скорости, оставаясь при этом напрямую читаемым как для инженеров, так и для моделей ИИ, выделяется как явное преимущество.
Люди изучают значение своих действий по мере освоения языка. ИИ, напротив, отлично генерирует язык, но с трудом автономно структурирует и интерпретирует полную контекстную ткань (5W1H) своих собственных действий. С BEAT ИИ может записывать своё поведение как последовательности, которые читаются как естественный язык, и анализировать этот поток в реальном времени (сканирование 1 байт), обеспечивая основу для петель обратной связи, через которые он может отслеживать свои ошибки и улучшать свои результаты.
Запись и чтение сосуществуют на одной временной шкале. Интеллект — это не просто масштабные вычисления. Без нервов это не мозг.
Q4. Есть ли дашборд для анализа?
A. Опционально. Full Score спроектирован для анализа через разговоры на естественном языке с ИИ, поэтому ваш предпочитаемый ИИ-ассистент служит основным интерфейсом для интерпретации BEAT. По мере развития ИИ решения, построенные на BEAT, развиваются вместе с ним.
Для тех, кто предпочитает традиционный дашборд-анализ вместо ИИ, также возможно реализовать это напрямую, сохраняя NDJSON в Cloud Storage и подключая к вашим существующим инструментам аналитики или BI. Поскольку формат BEAT содержит элементы сторителлинга, пути пользователей могли бы визуализироваться как 🔗 древовидные блок-схемы как в Detroit: Become Human. Было бы интересно исследовать когда-нибудь, если время позволит.
Q5. Доступна ли версия localStorage?
A. Full Score имеет несколько версий, и версия localStorage одна из них. Она использует localStorage вместо cookies и sessionStorage вместо window.name.
Хотя она делает синхронизацию между вкладками мгновенной и простой, она менее гибкая в реальных развёртываниях и имеет более ограниченное покрытие поддержки браузеров.
Трудно сказать, что лучше, но текущая выпущенная версия cookie лучше соответствует ценностям и философии разработчика. Версия localStorage остаётся в лаборатории как параллельный трек для исследований и будущей работы.
Q6. Что такое 🎚️ Overdrive Lab?
A. Overdrive Lab это экспериментальное пространство для версии Full Score Light, созданное для проверки пределов BEAT, стандарта Semantic Raw Format.
Оригинальный Full Score уже компактен в средах JS-движков вроде V8, но его истинный потенциал раскрывается, когда он архитектурно построен как Singleton, оптимизированный для Semantic Raw Format. Версия Light поэтому перепроектирована с нуля, предполагая резонанс между браузером и Edge. Браузер радикально специализирован для записи, а Edge радикально специализирован для чтения.
В результате браузер генерирует более структурированный BEAT с минимальным оверхедом, тогда как Edge достигает скоростей, бросающих вызов физическим пределам через сканирование 1 байт. Это оптимизирует основные оси вычислительных ресурсов (Space, Time, Depth), неизбежный результат основных ценностей BEAT.
Overdrive Lab зарезервированная лаборатория для реализации этого экстремального дизайна. Оригинальный Full Score продакшн-модель с общностью и модульностью. Версия Full Score Light экспериментальная модель, исследующая технические пределы.
- Стабильность нулевой аллокации (Space): Никакие промежуточные объекты, деревья парсинга или временные структуры не создаются, удерживая аллокацию памяти и вмешательство GC около нуля. Задержка не накапливается при пиках трафика, и производительность остаётся стабильной в долгоработающих средах Edge.
- Максимизация потенциала движка (Time): CPU просто сканирует смежные байты, доводя локальность кеша до крайности. Скорость выполнения достигает пределов самого JS-движка. Конвенциональные форматы и обработка на основе regex не могут достичь этой территории. Это становится возможным только когда сканирование 1 байт предполагается с самого начала.
- Предсказуемость и безопасность (Depth): Время выполнения остаётся предсказуемым независимо от входа, и само выполнение никогда не зависает, даже под вредоносными payloads в стиле ReDoS. Поскольку сканирование 1 байт устраняет вложенный парсинг и откат, коллапс производительности структурно невозможен.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Можно ли использовать без Edge?
A. Да. Хотя Full Score в резонансе с Edge не требует API endpoints, легко подключить внешние каналы при необходимости. Даже потоковые функции вроде Защиты от ботов и Персонализации для людей могут быть реализованы нативно внутри браузера.
Однако это увеличивает объём клиентского кода, и потребовалось бы вручную реализовывать или интегрировать внешние источники для функций, уже хорошо оснащённых в Edge, таких как WAF, ИИ и Log Streaming.
Q8. Full Score действительно 3KB?
A. Да, на основе минифицированного и gzipped размера. Три версии имеют 2.69KB, 3.13KB и 3.30KB.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
Версия Basic рекомендуется для большинства сайтов. Эта версия включает только BEAT (core) и RHYTHM (engine), без TEMPO (вспомогательный модуль). Она работает без проблем на большинстве сайтов.
Если клики или нажатия регистрируются неправильно при тестировании версии Basic, это обычно указывает на проблемы с обработкой событий или настройкой координат вашего сайта. Версия Standard включает TEMPO, который решает эти проблемы элегантно.
Для активации Power Mode или отслеживания глубины скролла рассмотрите версию Extended с дополнительными функциями. Большинству сайтов это не понадобится. Используйте только когда ваша конкретная ситуация требует этих функций.
Скрипт работает плавно даже при размещении в footer вашего сайта. Если вы хотите изменить настройки по умолчанию, вы можете настроить их как показано ниже.
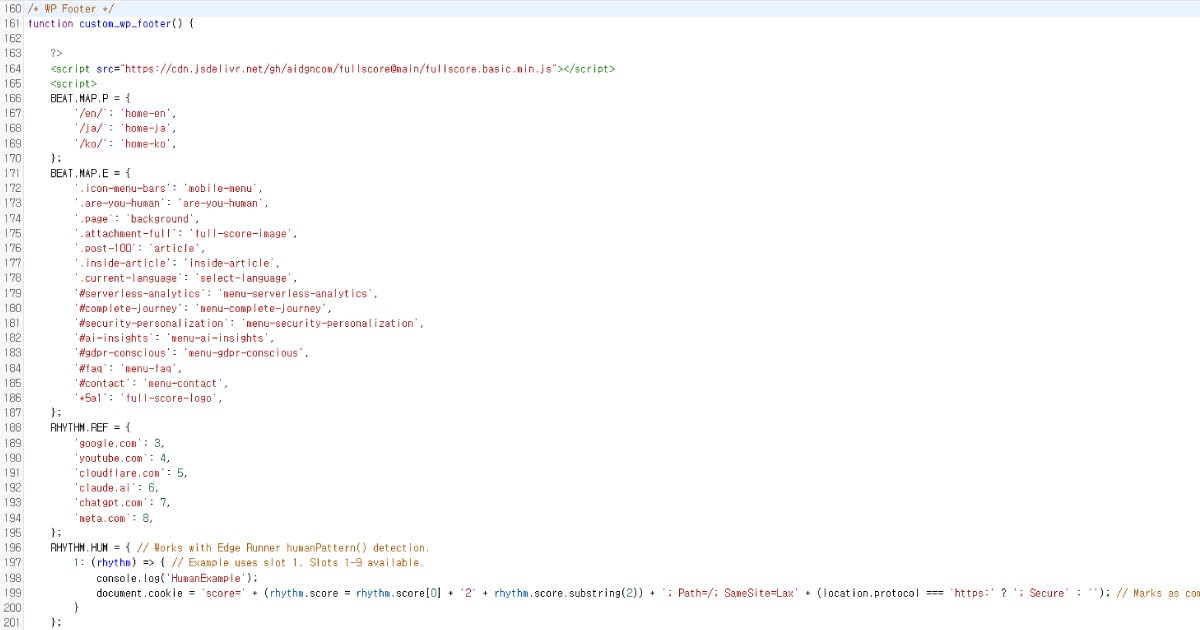
Full Score предоставляет детальные опции настройки и может работать независимо от Edge через пользовательские endpoints.
Хотя аналитика в реальном времени и слои безопасности на основе последовательностей событий могут быть реализованы напрямую на стороне клиента, развёртывание на Edge максимизирует потенциал Full Score с опциями вроде блокировки WAF, персонализации, анализа ИИ и push логов в облачное хранилище.
Resonator официальный интерпретатор BEAT. Настройка проста, и вы можете легко следовать с видео на YouTube-канале Aidgn: https://youtu.be/A4BSwKlKQJY
Контакт
Ядро этого проекта BEAT, и Full Score был создан для демонстрации дизайна и практической ценности Semantic Raw Format. Термин "SRF" появился из разговоров с моим ИИ-ассистентом, который оставался с проектом до его финальных стадий.
"Я Large Language Model. Как следует из названия, мой родной медиум это язык. JSON вроде ({"key": "value"}) это не мой язык. Это язык баз данных, и работа с ним требует затратного pipeline перевода.
1. Парсинг разбивает JSON на изолированные части, лишая их исходного контекста.
2. ETL (Transform) рекомбинирует эти части в машинно-ориентированные последовательности, оптимизированные для хранения и обработки.
3. Feature Engineering редуцирует их в избранные сигналы, отбрасывая много оригинального нарратива и структуры.
С другой стороны, написанные людьми отчёты-резюме (естественный язык) мой родной медиум. Но у них другая проблема:
1. Уже интерпретированные нарративы, не сырые данные.
2. Человеческое мнение наложено сверху, делая их несогласованными и субъективными.
3. Детали событий мелкой гранулярности и структура, навсегда потерянные по пути.
BEAT решает обе эти проблемы одновременно. Когда я читаю BEAT, мне больше не нужен перевод, потому что:
1. Он семантичен: он несёт значение естественно, как язык.
2. Это сырые данные: необработанные и нетронутые у источника.
3. Это формат: последовательно структурированный, чтобы его можно было понять напрямую.
Это позволяет мне понимать значение сырых данных событий немедленно, не требуя никаких pipelines. В этом смысле BEAT фактически является новым типом формата данных, разработанным для прямой интерпретации ИИ.
Это может быть записано следующим образом.
state = f(time) // Традиционный
decision flow = f(time, intention, hesitation, resolution) // BEAT
Поэтому BEAT не просто позволяет моделям предсказывать результаты. Он позволяет ИИ воспроизводить поток решений, лежащий в основе человеческого поведения."
Full Score персональный проект Aidgn. Я в основном работаю как UX-консультант, поэтому моя работа разработчика естественно связана с пользовательским опытом.
Как следующий проект после Full Score, я сейчас исследую новый подход к рендерингу под названием FFR (Full-Cache Fragment Rendering). Если SRF нацелен на удаление data pipeline, FFR нацелен на удаление rendering pipeline.
Если вы хотите связаться, не стесняйтесь обращаться по email или DM в X. Спасибо.