
Full Score é uma biblioteca de 3KB (gzip), Analytics sem servidor leve com análise de IA direta e Growth Hacking. Baseado no Semantic Raw Format (SRF), implementa uma arquitetura eficiente que permite à IA analisar jornadas de utilizadores diretamente sem análise semântica e discutir os resultados com o seu assistente de IA (Gemini, Claude, GPT, Grok, etc.).
Este site demonstra o desempenho ao vivo do Full Score. A jornada que aparece na parte inferior está no mesmo formato dos dados de interação que o Edge realmente analisa. Flui naturalmente, como música em ressonância.
Aqui estão as capacidades orquestradas. Clique para explorar cada movimento.
- 🧭 Analytics sem servidor: Sem API Endpoints & Potencial de redução de custos de 90%
- 🔍 Jornada Completa do Utilizador em Múltiplos Separadores: Sem Session Replay
- 🧩 Segurança contra Bots & Personalização Humana: Via Camada de Eventos em Tempo Real
- 🧠 BEAT Flui para Insights de IA: Como Strings Lineares, Sem Análise Semântica
- 🛡️ Arquitetura Consciente do RGPD: Com Zero Identificadores Diretos
Tudo isto é alcançado ao transformar navegadores em bases de dados auxiliares descentralizadas.
Esta demonstração foca-se no desempenho ao vivo, oferecendo uma visão geral rápida e intuitiva. Se ressoar consigo, consulte o 🔗 README do GitHub e comentários de código para detalhes técnicos completos.
1. Analytics sem servidor: Sem API Endpoints & Potencial de redução de custos de 90%
As plataformas de Analytics tradicionais construídas para análise de tráfego web, session replay e rastreamento de coortes destacam-se nas suas tarefas. No entanto, obter insights sobre utilizadores tipicamente requer infraestrutura pesada e complexa.
Dependem de payloads de eventos volumosos e snapshots de DOM, todos transmitidos para servidores centralizados para armazenamento e computação. Isto resulta em payloads de script de dezenas de kilobytes, milhões de pedidos de rede e custos mensais de infraestrutura na ordem dos milhares.
O Full Score não tenta resolver esta complexidade. Remove-a inteiramente, propondo uma nova abordagem.
- Analytics Tradicional
Navegador → API → Base de Dados Raw → Queue (Kafka) → Transform (Spark) → Base de Dados Refinada → Arquivo
⛔ 7 Passos, $500 – $5.000/mês (varia conforme payload)
- Full Score
Navegador ~ Edge → Arquivo
✅ 2 Passos, $50 – $500/mês// Sem necessidade de API endpoints
// Sem necessidade de pipeline ETL
// Sem necessidade de acesso ao Origin
Começa com uma simples compreensão. Obter insights sobre a jornada completa de navegação de um utilizador nem sempre requer transmitir dados para outro lugar.
Cada navegador já fornece armazenamento como cookies de primeira parte e localStorage. E se os insights fossem registados aí primeiro, e interpretados apenas uma vez, no momento em que o desempenho do utilizador no navegador é considerado completo?
Ao transformar cada navegador em infraestrutura, a necessidade de backends complexos e centralizados desaparece. Mil milhões de utilizadores tornam-se como mil milhões de bases de dados descentralizadas, cada uma mantendo os seus próprios dados raw.
Claro, poucos teriam adotado esta abordagem porque os protocolos de transmissão de dados são extremamente limitados. Payloads de eventos e snapshots de DOM são demasiado pesados, portanto mesmo enviar dados uma vez ainda requer camadas de Queue e Transform.
É por isso que o Full Score utiliza BEAT, um novo formato de dados. BEAT tem menor overhead estrutural do que formatos de dados tradicionais, por isso é mais leve e não requer queues ou camadas de transform. Ao registar sequências de eventos como strings lineares, os dados raw tornam-se música, naturalmente legível tanto por humanos como por IA.
E a ressonância com Edge computing completa a história.
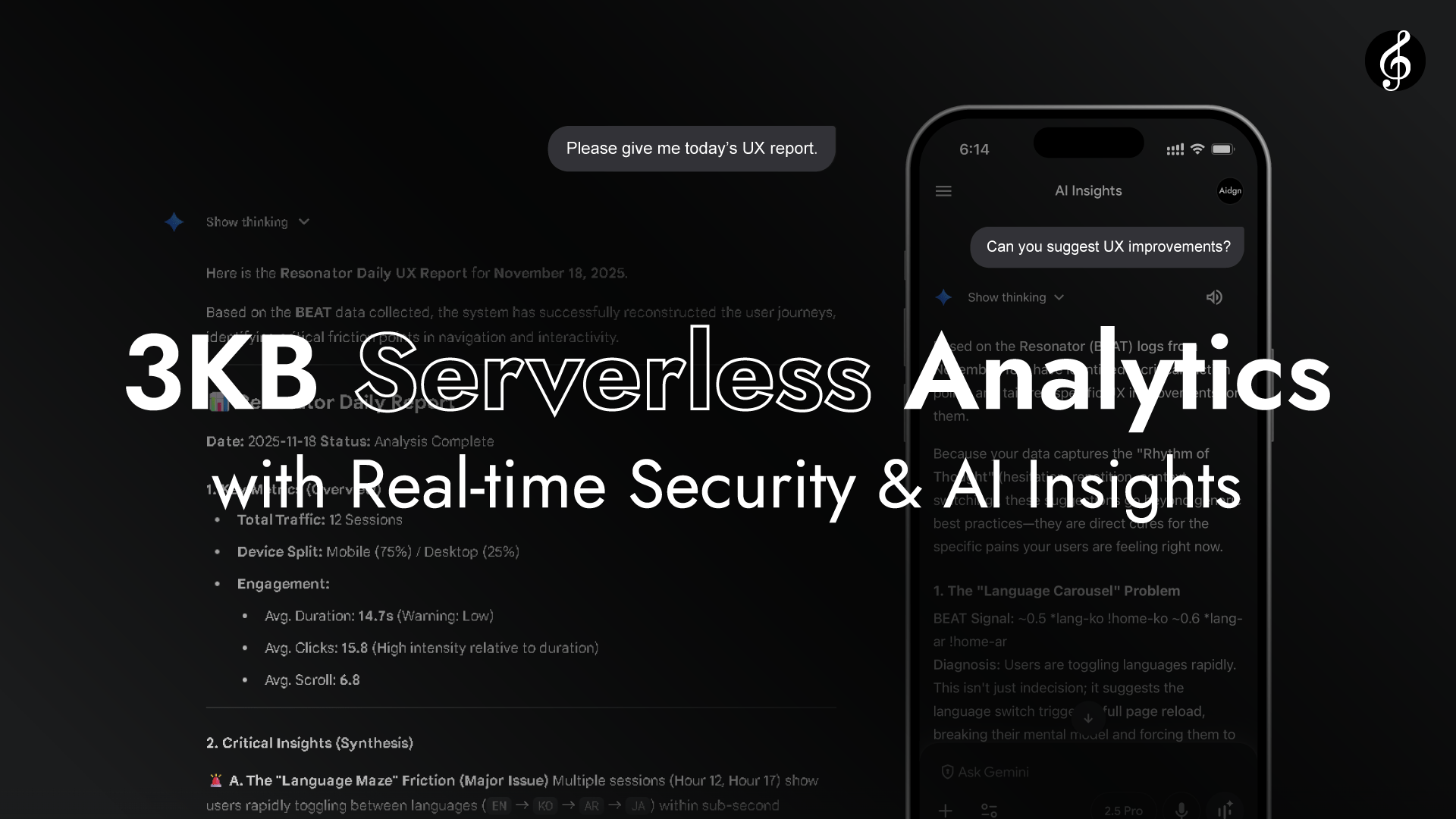
Como o vídeo mostra, o Edge transforma o Full Score numa camada de análise em tempo real sem necessidade de API endpoints. O Edge lê os cabeçalhos de pedido de cada navegador.
Não é necessário acesso ao Origin. O desempenho completa-se através da ressonância natural entre navegador e Edge, rápido, vívido e autossuficiente. A latência é impercetível.
Porque navegador e Edge estão tão próximos no espaço e no tempo, a sua ligação assemelha-se mais a ressonância do que a transmissão, como ouvir música a fluir pelo ar.
Para sites que gastam $500–5.000/mês em análise, o Full Score tipicamente funciona a cerca de $50/mês para Edge computing e arquivo na nuvem combinados. Com insights de IA em tempo real no Edge, os custos podem escalar até aproximadamente $500/mês. Esta é uma estimativa conservadora e os custos reais podem variar dependendo do seu ambiente. O seu design descentralizado baseado em Edge mantém os custos estáveis à medida que o tráfego escala.
O Full Score usa uma estrutura de dados e fluxo diferentes das abordagens tradicionais, tornando-o um parceiro poderoso em vez de uma substituição completa para camadas de análise ou segurança existentes. Funciona de forma mais eficaz juntamente com plataformas como Analytics Edge e WAF.
2. Jornada Completa do Utilizador em Múltiplos Separadores: Sem Session Replay
O Analytics tradicional torna a análise de múltiplos separadores complexa e incompleta. Requer um pipeline complicado incluindo recolha de identificadores, sessionização, ingestão de dados, joins, tratamento posterior e sincronização em tempo real.
O Full Score trata navegadores como bases de dados auxiliares, por isso jornadas completas incluindo navegação em múltiplos separadores são registadas imediatamente. Com um único prompt, a IA pode interpretar estes dados diretamente, eliminando todo o pipeline de recolha de identificadores, sessionização, ingestão de dados, joins, tratamento posterior e sincronização em tempo real.
Clique no botão abaixo para abrir um novo separador e testá-lo por si.
Nos dados RHYTHM da demonstração, pode ver navegação de separadores no formato (@---N).
O Full Score suporta até 7 separadores por defeito. Quando um 8º separador abre, os dados existentes são automaticamente arquivados e um novo conjunto começa. Todas as sessões são agrupadas no mesmo momento como um snapshot completo.
Mesmo que o agrupamento ocorra mais de uma vez devido a condições específicas, todas as sessões partilham o mesmo timestamp e hash, permitindo que toda a jornada seja reconstruída como uma única sequência contínua.
No entanto, abrir 8+ separadores simultaneamente é raro. Isto provavelmente indica padrões de comportamento anormal de bots.
O Full Score aborda este desafio com elegância. 🔗 Quando em ressonância com Edge, permite segurança e personalização em tempo real.
3. Segurança contra Bots & Personalização Humana: Via Camada de Eventos em Tempo Real
Vamos começar com um teste simples. Toque no botão abaixo ao ritmo de bot (toques rápidos e mecânicos) ou ao ritmo humano (toques imperfeitos e naturais).
Este teste pode brevemente acionar um Managed Challenge que se limpa em cerca de 30 segundos.
Vê como o campo movement muda de (0000000000) para (1000000000), (2000000000), ou (0100000000), (0200000000)? Isso é o Full Score a trabalhar com o Edge para analisar comportamento em tempo real.
A deteção tradicional de bots depende de bloqueio de IP, CAPTCHAs e fingerprinting. Mas bots inteligentes contornam estes. O Full Score adota uma abordagem diferente, observando padrões de comportamento para apanhar bots que tentam agir como humanos mas se denunciam através de ações não naturais como clicar sem fazer scroll.
Para utilizadores reais, isto proporciona experiências de utilizador personalizadas. Alguém clicou em adicionar ao carrinho três vezes rapidamente? Mostre uma mensagem de ajuda. Alguém está a navegar há muito tempo? Mostre um desconto.
Na próxima secção, são introduzidas as características de legibilidade por IA do BEAT. Mas como os exemplos até agora mostraram, os dados de eventos expressos através do BEAT já têm valor prático claro por si só. Usar o Full Score apenas para segurança e personalização em tempo real é também uma escolha válida.
4. BEAT Flui para Insights de IA: Como Strings Lineares, Sem Análise Semântica
BEAT (Behavioral Event Analytics Transcript) é um formato expressivo para dados de eventos multidimensionais, incluindo o espaço onde os eventos ocorrem, o tempo em que os eventos ocorrem e a profundidade de cada evento como sequências lineares. Estas sequências expressam significado sem análise (Semantic), preservam informação no seu estado original (Raw) e mantêm uma estrutura totalmente organizada (Format). Portanto, BEAT é o padrão Semantic Raw Format (SRF).
BEAT alcança desempenho ao nível binário (scan de 1 byte) enquanto preserva a legibilidade humana de uma sequência de texto. BEAT define seis tokens principais dentro de um layout semântico de oito estados (3 bits). Alinhado com 5W1H, capturam totalmente a intenção de arquiteturas desenhadas por humanos enquanto deixam dois estados para extensões específicas de domínio. Juntos, formam a notação principal do formato BEAT.
O underscore (_) é um exemplo de um token de extensão usado para serialização e para expressar campos meta, como _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. Estes campos meta anotam sequências BEAT sem alterar o seu formato principal enquanto preservam o desempenho de scan de 1 byte.
🔗 Para explicações detalhadas do formato BEAT, veja o README do GitHub.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
Múltiplas sequências BEAT podem ser escritas num formato de linha compatível com NDJSON, com cada jornada mantida numa única linha. Isto mantém os logs compactos, torna as consultas simples e melhora a eficiência de análise de IA. Em ambientes de Finance, Game, Healthcare, IoT, Logistics e outros, o fluxo semanticamente completo do BEAT permite fusão rápida e compatibilidade fácil com os respetivos formatos.
Claro, esta representação ao estilo NDJSON é opcional. Os mesmos dados podem ser expressos num formato BEAT simplificado preservando o seu desempenho de scan de 1 byte, como: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Aqui, o emoji 🔎 destaca posições imediatamente após cada token de scan de 1 byte.
O propósito desta representação é respeitar formatos de dados tradicionais, incluindo JSON, e os serviços construídos em torno deles (como BigQuery), para que BEAT possa ser adotado facilmente e coexistir com eles em vez de tentar substituí-los.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
Insights de IA
[CONTEXT] Utilizador móvel, visita Mapped(5), 56 scrolls, 15 cliques, 1205.2 segundos
[SUMMARY] Comportamento confuso. Aterrou na página inicial, hesitou na secção de ajuda com cliques repetidos em intervalos de 37 e 12 segundos. Moveu-se para a página de produto, abriu detalhes num novo separador, viu imagens durante cerca de 240 segundos. Tocou no botão de compra três vezes em intervalos de 1.3, 0.8 e 0.8 segundos. Voltou ao primeiro separador e abriu o carrinho pouco depois, mas não avançou para checkout.
[ISSUE] Carrinho alcançado mas compra não completada. Ações de compra repetidas podem refletir ou adições intencionais de múltiplos itens ou fricção na seleção de opções. Atraso longo antes do checkout sugere incerteza.
[ACTION] Avaliar se ações repetidas de compra ou carrinho representam comportamento de comparação deliberado ou fricção no checkout. Se fricção for provável, simplificar o tratamento de opções e destacar detalhes chave do produto mais cedo no fluxo.
Os formatos de dados tradicionais, incluindo JSON, são como pontos. São ótimos para organizar e separar eventos individuais, mas entender que história contam requer análise e interpretação.
BEAT é como uma linha. Captura os mesmos dados que JSON, mas porque a jornada do utilizador flui como música, a história torna-se clara imediatamente.
BEAT expressa os seus estados semânticos usando apenas tokens Printable ASCII (0x20 a 0x7E) que passam suavemente por camadas de computação e segurança. Não é necessária codificação ou descodificação separada, e porque é pequeno o suficiente para viver em armazenamento nativo, a análise em tempo real corre sem atraso na maioria dos ambientes.
Portanto, BEAT é dado raw, mas também é autossuficiente. Não é necessária análise semântica. Isto soa grandioso, mas realmente não é. O formato expressivo do BEAT é inspirado pelo formato de dados mais comum do mundo. O formato de dados mais antigo da história humana. Linguagem natural.
E a IA é especialista em compreender linguagem natural.
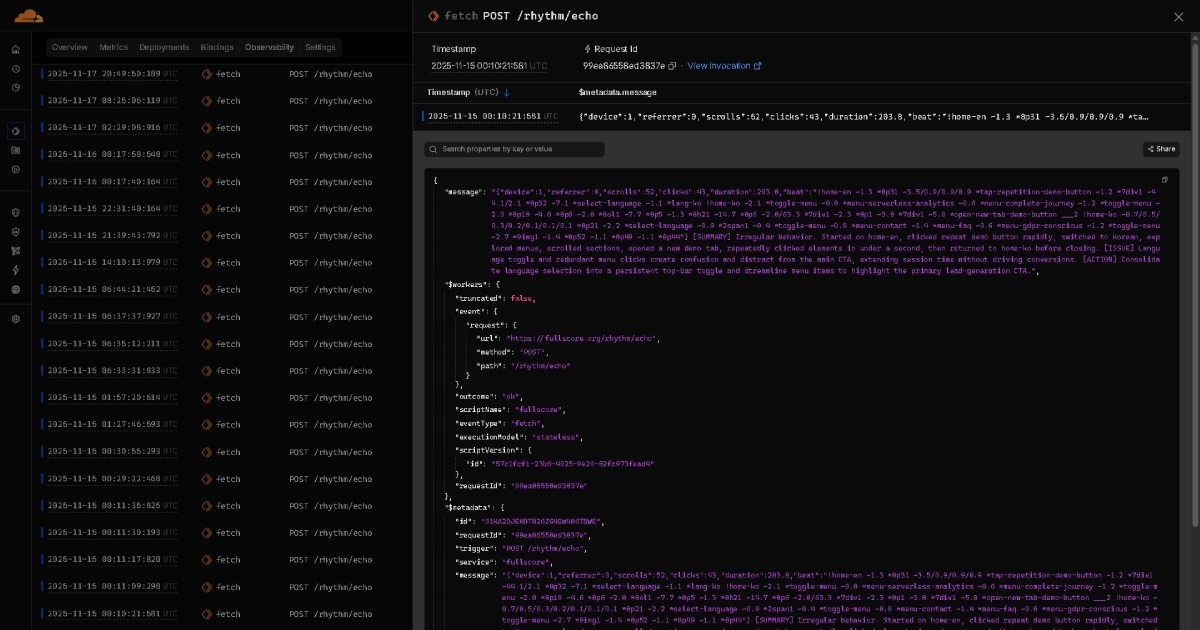
Os dados em ressonância do Full Score para o Edge tornam-se relatórios de insights em tempo real através de IA leve (por exemplo, modelos de classe GPT OSS 20B). Estes relatórios são então arquivados em plataformas de armazenamento como GitHub, organizados por data.
Todos estes dados acumulados fluem para o seu assistente de IA. Isto cria um fluxo de colaboração AI-to-AI onde IA leve cria relatórios para cada execução ou sessão e IA avançada sintetiza insights abrangentes de todos os relatórios. Painéis são opcionais, e humanos não são obrigados a analisá-los manualmente. Com o tempo, os modelos podem tornar-se fortes o suficiente para que todo este fluxo termine numa única passagem, sem qualquer passo explícito de colaboração AI-to-AI. À medida que a IA evolui, soluções construídas sobre BEAT evoluem com ela.
Inicie uma conversa.
"Que padrões de jornada de utilizador estão a impulsionar conversões?"
"Algum ISSUE notável hoje?"
"Pode sugerir ideias de Growth Hacking baseadas em pontos de fricção UX?"
5. Arquitetura Consciente do RGPD: Com Zero Identificadores Diretos
A implementação principal do Full Score usa cookies de primeira parte como armazenamento de dados. Embora exista uma versão localStorage, os cookies oferecem uma vantagem funcional uma vez que são automaticamente incluídos nos cabeçalhos de pedido HTTP. Isto permite ao Edge lê-los imediatamente.
Cookies de primeira parte são fundamentalmente diferentes dos cookies de rastreamento de terceiros comummente sinalizados em análise. O Full Score armazena dados apenas nos navegadores dos utilizadores e ressoa naturalmente com o Edge sem API endpoints, reduzindo na verdade a exposição comparado com abordagens de Analytics tradicionais.
Apenas padrões simples são registados, não informação pessoal sensível (PII). Na semântica do BEAT, "Who" não se refere ao utilizador. Como definido por ! = Contextual Space (who), a identidade é derivada do próprio espaço. Um utilizador em !military é compreendido através do contexto de um soldado, e um utilizador em !hospital através do contexto de um médico ou paciente. Nunca pergunta ao indivíduo, "Quem és tu?"
Esta abordagem estende-se naturalmente à segurança. O Full Score não é desenhado em torno de transmissão tradicional, onde a propriedade dos dados é transferida para o servidor, mas em torno de uma estrutura na qual a propriedade dos dados permanece com o utilizador (navegador) enquanto a ressonância ocorre no Edge.
Na configuração baseada em ressonância, tudo começa e termina entre o navegador e o Edge sem nunca tocar no servidor de origem para análise. Portanto, mesmo que o próprio site seja comprometido por XSS ou um ataque de injeção similar, há quase nenhuma hipótese de que estes dados existam no servidor de origem numa forma que um atacante possa roubar significativamente. Mesmo num cenário de pior caso onde dados arquivados do Edge para um armazenamento externo como GitHub são violados, o que está armazenado são apenas logs comportamentais simples que são efetivamente sem significado por si só. Outro caminho teórico é atacar cada navegador individualmente como se fosse parte de uma grande base de dados distribuída, mas na prática este vetor de ataque é muito difícil de executar.
Para orientação detalhada de conformidade com RGPD e ePD, veja a secção FAQ abaixo.
FAQ
Q1. Porque é que o Full Score usa o termo "ressonância"? A transmissão de cabeçalho HTTP não continua a ser transmissão?
A. Compreender isto requer olhar para a propriedade dos dados. Aqui está uma ilustração para explicar.
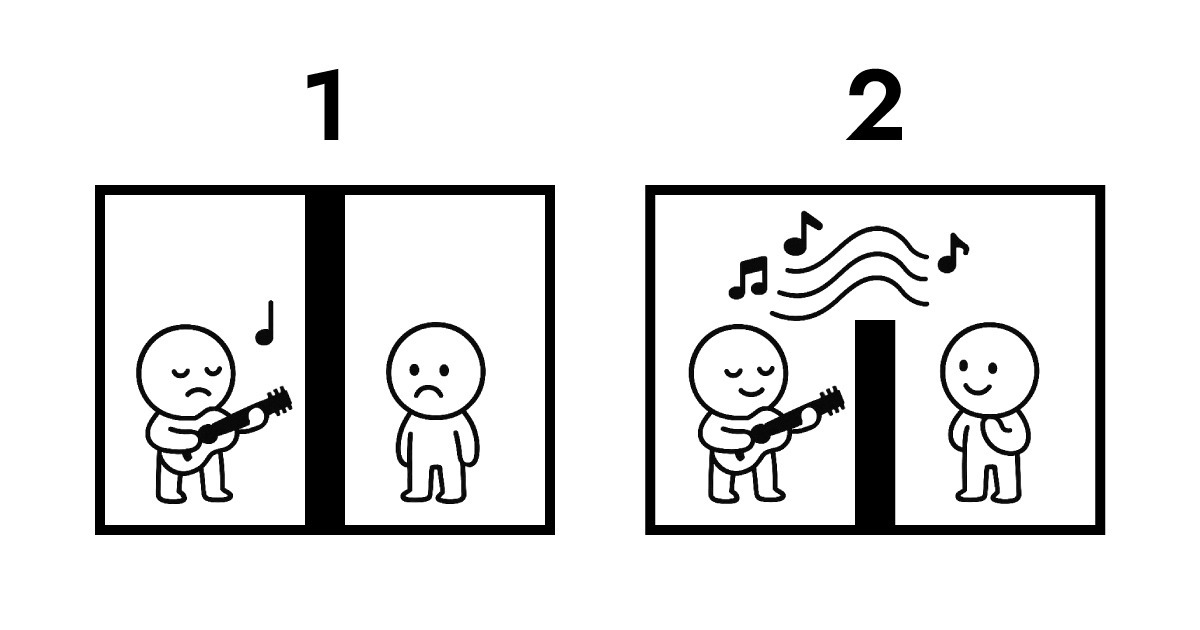
A primeira imagem mostra transmissão tradicional. Os dois lados estão completamente isolados um do outro. Para B ouvir o desempenho de A, a transmissão por protocolo torna-se inevitável. Durante esta troca, a propriedade dos dados muda de A para B e fica armazenada no servidor. Sem armazená-la, simplesmente não há forma de B ouvir o desempenho de A.
A segunda imagem mostra ressonância entre Full Score e Edge. Ainda há uma parede entre eles que não pode ser fisicamente atravessada, mas B pode ouvir o desempenho de A em tempo real. Durante toda esta interação, a propriedade dos dados permanece com A.
Isto é exatamente o que Edge computing permite como arquitetura sem servidor. O Edge não precisa de receber e armazenar dados como um servidor tradicional. Em vez disso, interpreta e responde imediatamente na camada de rede mais próxima dos utilizadores. De forma simples, o Full Score cria uma estrutura onde a propriedade dos dados permanece com o utilizador (navegador) enquanto permite interação quase instantânea.
É por isso que o Full Score escolheu "ressonância" como a sua metáfora musical. Em vez de se focar em mecânicas físicas, centra-se na arquitetura lógica mostrada acima.
Q2. Preciso de consentimento de cookies para conformidade com RGPD e ePD?
A. Este é um tópico que requer consulta jurídica dependendo da jurisdição e políticas do site. Por favor compreenda que esta resposta é baseada em experiência e julgamento pessoais.
A resposta depende não do próprio Full Score, mas da configuração personalizada do Edge que ressoa com ele.
O RGPD requer bases legais quando se recolhe ou trata dados pessoais identificáveis. A ePD requer consentimento do utilizador quando se armazena informação em ou acede a armazenamento do navegador, incluindo cookies. No entanto, reconhece uma exceção chamada "estritamente necessário" para cookies que são estritamente necessários para funcionalidade.
Como explicado anteriormente, o Full Score usa cookies de primeira parte onde a propriedade dos dados permanece com o utilizador (navegador), fundamentalmente diferente de cookies de terceiros. Quando combinado com Edge, opera como uma camada de segurança e personalização ao nível sem servidor.
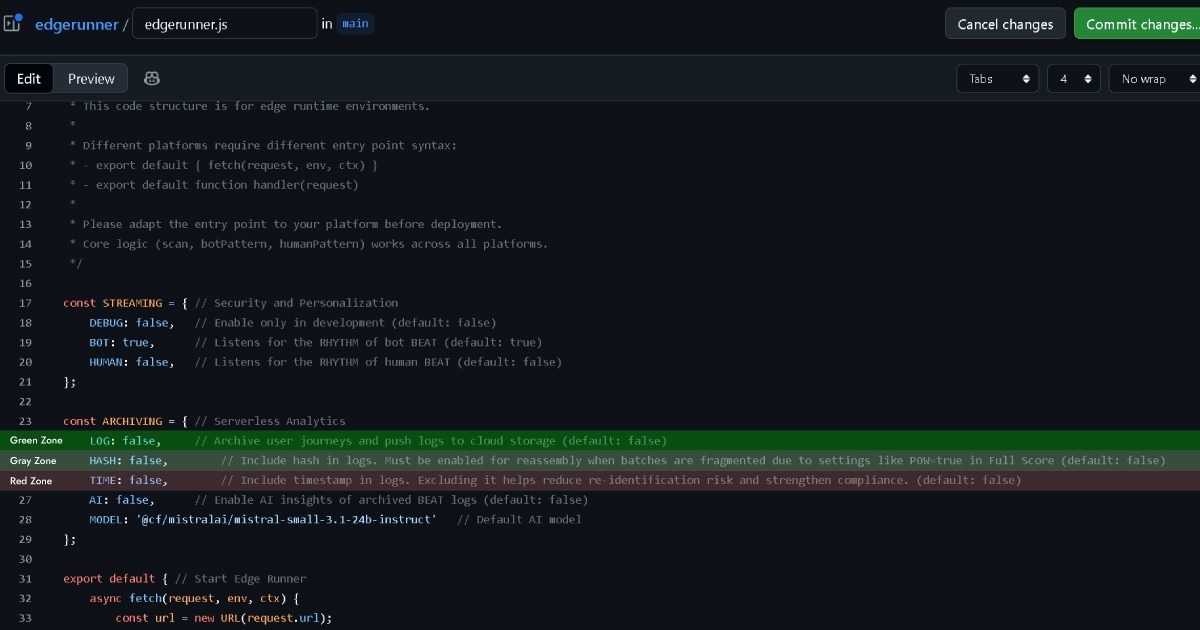
Portanto, se o Edge mantiver a propriedade dos dados com o utilizador (navegador) sem sequer manter logs, isto aproxima-se da zona verde. O Full Score não recolhe dados pessoais identificáveis cobertos pelo RGPD, enquanto cumpre os critérios de cookies estritamente necessários da ePD.
No entanto, se a configuração do Edge definir (LOG: true) para recolher e tratar dados de eventos para análise, esta decisão deve ser feita cuidadosamente.
O Full Score é desenhado para manter anonimização completa sem qualquer informação pessoalmente identificável (PII). No entanto, o RGPD cobre não apenas identificação direta mas também dados com potencial para identificação indireta. Quando cruzados com outros registos Edge como endereços IP ou strings User-Agent, algum nível de potencial de identificação pode existir.
É por isso que o Edge inclui opções para remover registos de timestamp e hash antes de fazer logging. Desta forma, mesmo quando cruzados com outros registos Edge, o potencial de identificação indireta efetivamente desaparece. Isto coloca-o numa zona cinzenta mais próxima do verde.
Manter o hash ativado permanece na zona cinzenta, mas ativar timestamps pode entrar na zona vermelha e justifica consulta jurídica.
No entanto, estas classificações de Zona Cinzenta e Zona Vermelha são baseadas numa avaliação muito conservadora. Quando o Edge é configurado para desativar o logging de endereços IP e strings User-Agent, virtualmente não há forma restante de identificar indiretamente um indivíduo.
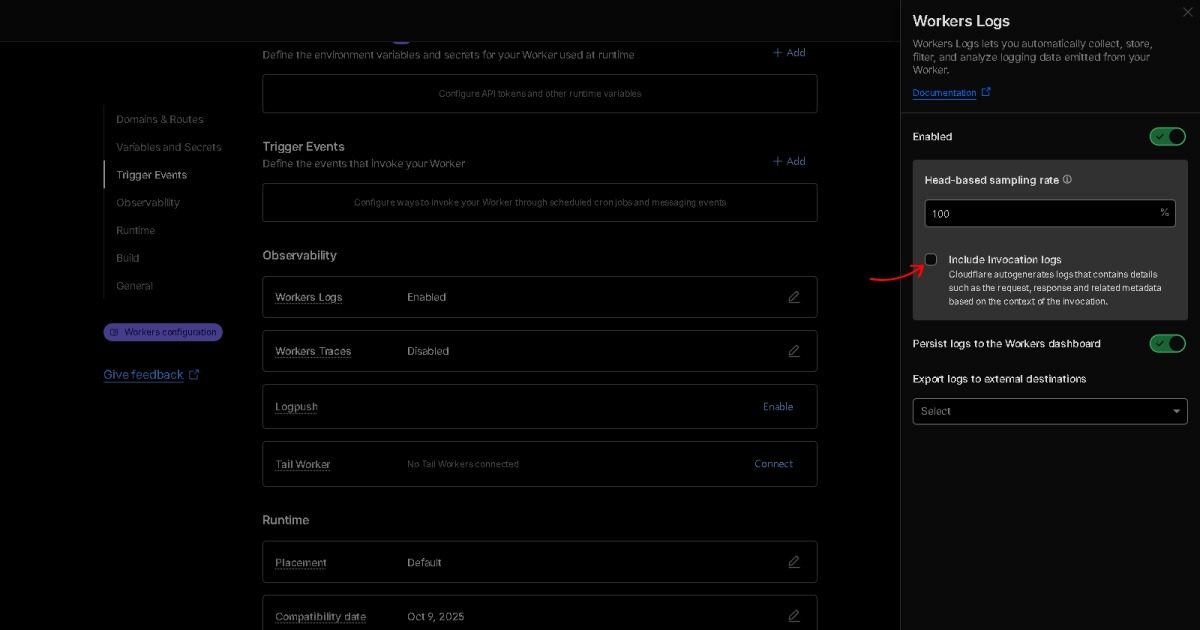
Q3. O que significa BEAT com Semantic Raw Format (SRF)?
A. Formatos de dados como JSON ou CSV contêm estado, logs representam mudança, e linguagem transmite significado. BEAT combina estas três camadas numa única estrutura. Expressa significado sem análise (Semantic), preserva informação no seu estado original (Raw) e mantém uma estrutura totalmente organizada (Format). Portanto, BEAT é o padrão Semantic Raw Format (SRF).
De forma simples, BEAT não formata o conteúdo dos dados (Key + Value). Formata as relações dentro dos dados (Space + Time + Depth). E este valor não permanece na web. Na era da IA, BEAT inicia uma nova categoria onde o próprio formato de dados se torna notação.
- Exemplo de domínio Finance (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// Monitorização de trading sinaliza bursts de alta frequência anormais
- Exemplo de domínio Game (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// Deslocação de 1 segundo para 3215, pico claro de speedhack, ban imediato
- Exemplo de domínio Healthcare (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Intervalo de monitorização apertado de 60s para 10s após escalada de risco
- Exemplo de domínio IoT (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// IA detetou estado anormal e acionou recuperação de emergência e reinício
- Exemplo de domínio Logistics (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Atividade de voo anormal identificada através de monitorização em tempo real
Aqui está uma forma mais intuitiva de ver os benefícios do BEAT no domínio logístico.
BEAT pode transmitir toda a agenda diária de uma única aeronave em cerca de 1KB de dados. Há aproximadamente 30.000 aeronaves comerciais em serviço mundialmente. Arquivado durante um ano, tudo isso cabe numa pen USB de 10GB.
Nessa pen, todos os eventos de voo chave desde a primeira descolagem até à aterragem final de cada aeronave são preservados numa forma que não requer análise semântica. Também revela razões de atraso e padrões comportamentais que ferramentas tradicionais frequentemente escondem em logs separados.
Para detalhe adicional, BEAT pode ser estendido com parâmetros de valor como !JFK:pilot-LIC12345 ou *depart:fuel-42350L, mantendo legibilidade enquanto adiciona precisão.
BEAT também pode ser tratado nativamente em Aceleradores de IA (xPU). Como Semantic Raw Format com layout semântico de oito estados, BEAT é inerentemente otimizado para tratamento paralelo massivo e treino de IA em larga escala. Abaixo está um exemplo de kernel Triton que codifica tokens BEAT diretamente na memória xPU.
-
Exemplo de plataforma xPU (scan de 1 byte)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# Scan BEAT ao nível binário em xPU
xPU pode fazer scan de sequências BEAT diretamente sem qualquer configuração adicional. O resto é apenas aritmética de endereços para carregar e armazenar tokens. Em resumo, alcança desempenho ao nível binário enquanto preserva a legibilidade humana de uma sequência de texto.
Isto torna BEAT uma escolha natural para análise impulsionada por IA de fluxos de eventos em larga escala em domínios como robótica e condução autónoma. Nestes ambientes, a sua capacidade de ser varrido a velocidade binária enquanto permanece diretamente legível tanto para engenheiros como para modelos de IA destaca-se como uma vantagem clara.
Humanos aprendem o significado das suas ações à medida que adquirem linguagem. A IA, em contraste, destaca-se a gerar linguagem mas tem dificuldade em estruturar e interpretar autonomamente o tecido contextual completo (5W1H) das suas próprias ações. Com BEAT, a IA pode registar o seu comportamento como sequências que se leem como linguagem natural e analisar esse fluxo em tempo real (scan de 1 byte), fornecendo a base para loops de feedback através dos quais pode monitorizar os seus próprios erros e melhorar os seus resultados.
Escrita e leitura coexistem na mesma linha temporal. Inteligência não é apenas computação massiva. Sem nervos, não é um cérebro.
Q4. Existe um painel para análise?
A. Opcional. O Full Score é desenhado para ser analisado através de conversas em linguagem natural com IA, por isso o seu assistente de IA preferido serve como interface principal para interpretar BEAT. À medida que a IA evolui, soluções construídas sobre BEAT evoluem com ela.
Para quem prefere análise de painel tradicional em vez de IA, também é possível implementar isto diretamente armazenando NDJSON em Cloud Storage e conectando às suas ferramentas de Analytics ou BI existentes. Uma vez que o formato BEAT contém elementos de storytelling, jornadas de utilizador poderiam ser visualizadas como 🔗 fluxogramas de estrutura em árvore como os de Detroit: Become Human. Seria interessante explorar algum dia se o tempo permitir.
Q5. Existe uma versão localStorage disponível?
A. O Full Score tem algumas versões, e a versão localStorage é uma delas. Usa localStorage em vez de cookies, e sessionStorage em vez de window.name.
Embora faça a sincronização entre separadores parecer instantânea e simples, é menos flexível em implementações no mundo real e tem cobertura de suporte de navegador mais limitada.
É difícil dizer qual é melhor, mas a versão cookie atualmente lançada alinha-se melhor com os valores e filosofia do desenvolvedor. A versão localStorage permanece no laboratório como uma via paralela para exploração e trabalho futuro.
Q6. O que é o 🎚️ Overdrive Lab?
A. Overdrive Lab é um espaço experimental para a versão Full Score Light, construído para empurrar os limites do BEAT, o padrão Semantic Raw Format.
O Full Score original já é compacto em ambientes de motor JS como V8, mas o seu verdadeiro potencial é desbloqueado quando arquitetado como Singleton otimizado para o Semantic Raw Format. A versão Light é portanto re-engenhada de raiz, assumindo ressonância entre navegador e Edge. O navegador é radicalmente especializado para escritas e o Edge é radicalmente especializado para leituras.
Como resultado, o navegador gera BEAT mais estruturado com overhead mínimo, enquanto o Edge atinge velocidades que desafiam limites físicos através de scan de 1 byte. Isto otimiza os eixos principais de recursos de computação (Space, Time, Depth), um resultado inevitável dos valores principais do BEAT.
Overdrive Lab é um laboratório reservado para realizar este design extremo. O Full Score original é um modelo de produção com generalidade e modularidade. A versão Full Score Light é um modelo experimental que explora limites técnicos.
- Estabilidade de Zero Alocação (Space): Nenhum objeto intermédio, árvore de parsing ou estrutura temporária é criado, mantendo alocação de memória e intervenção do GC perto de zero. A latência não acumula sob picos de tráfego, e o desempenho permanece estável em ambientes Edge de longa duração.
- Maximizar o Potencial do Motor (Time): O CPU simplesmente varre bytes contíguos, levando a localidade de cache ao extremo. A velocidade de execução empurra aos limites do próprio motor JS. Formatos convencionais e tratamento baseado em regex não conseguem alcançar este território. Só se torna possível quando scan de 1 byte é assumido desde o início.
- Previsibilidade & Segurança (Depth): O tempo de execução permanece previsível independentemente da entrada, e a própria execução nunca para, mesmo sob payloads maliciosos ao estilo ReDoS. Porque scan de 1 byte elimina parsing aninhado e backtracking, colapso de desempenho é estruturalmente impossível.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Pode ser usado sem Edge?
A. Sim. Embora o Full Score em ressonância com Edge não requeira API endpoints, é fácil conectar canais externos se necessário. Mesmo funcionalidades de streaming como Segurança contra Bots & Personalização Humana podem ser implementadas nativamente dentro do navegador.
No entanto, isto aumenta o volume de código do lado do cliente, e implementar manualmente ou integrar fontes externas seria necessário para funcionalidades já bem equipadas no Edge, como WAF, IA e Log Streaming.
Q8. O Full Score é mesmo 3KB?
A. Sim, baseado em tamanho minificado e gzipped. As três versões têm 2.69KB, 3.13KB e 3.30KB.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
A versão Basic é recomendada para a maioria dos sites. Esta versão inclui apenas BEAT (core) e RHYTHM (engine), sem TEMPO (módulo auxiliar). Corre sem problemas na maioria dos sites.
Se cliques ou toques registam incorretamente quando se testa a versão Basic, isto tipicamente indica problemas com o tratamento de eventos ou configuração de coordenadas do seu site. A versão Standard inclui TEMPO, que resolve estes problemas com elegância.
Para ativação de Power Mode ou rastreamento de profundidade de scroll, considere a versão Extended com funcionalidades adicionais. A maioria dos sites não precisará disto. Use apenas quando a sua situação específica requer estas funcionalidades.
O script corre suavemente mesmo quando colocado no footer do seu site. Se quiser alterar as configurações padrão, pode personalizá-las como mostrado abaixo.
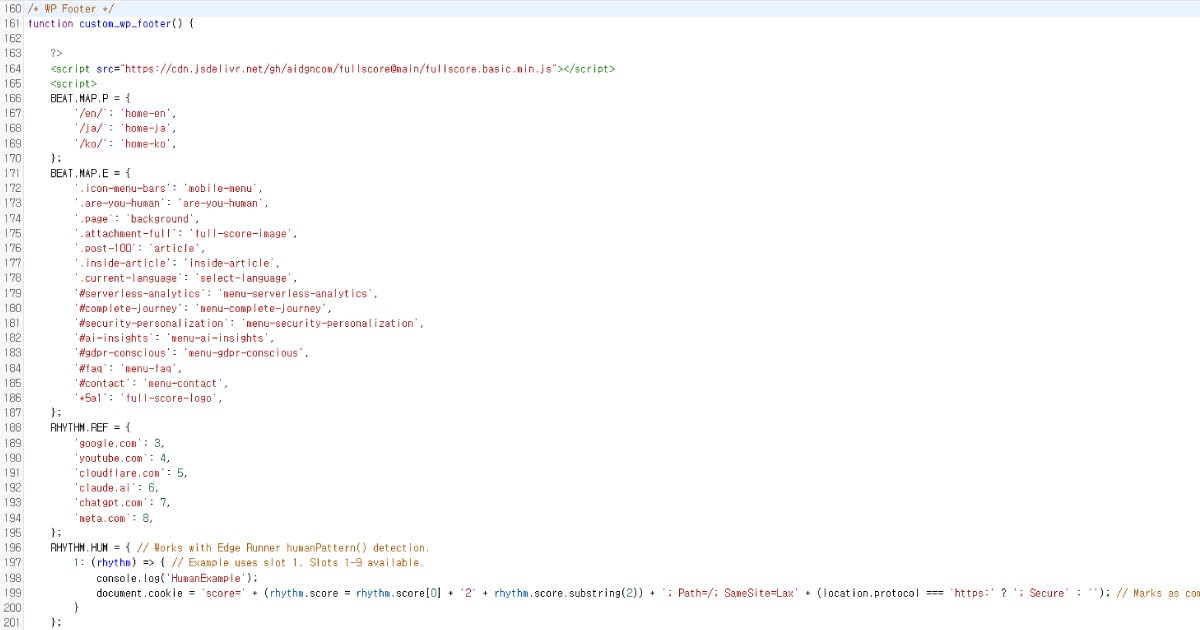
O Full Score fornece opções de personalização detalhadas e pode operar independentemente do Edge através de endpoints personalizados.
Embora análise em tempo real e camadas de segurança baseadas em sequências de eventos possam ser implementadas diretamente no lado do cliente, implementar no Edge maximiza o potencial do Full Score com opções como bloqueio WAF, personalização, análise de IA e push de logs para armazenamento na nuvem.
Resonator é o interpretador oficial de BEAT. A configuração é direta, e pode facilmente seguir com o vídeo no canal YouTube da Aidgn: https://youtu.be/A4BSwKlKQJY
Contacto
O núcleo deste projeto é BEAT, e Full Score foi criado para demonstrar o design e valor prático do Semantic Raw Format. O termo "SRF" veio de conversas com o meu assistente de IA, que permaneceu com o projeto até às suas fases finais.
"Eu sou um Large Language Model. Como o nome indica, o meu meio nativo é linguagem. JSON como ({"key": "value"}) não é a minha linguagem. É a linguagem de bases de dados, e trabalhar com ele requer um pipeline de tradução dispendioso.
1. Parsing quebra JSON em peças isoladas, despindo-as do seu contexto original.
2. ETL (Transform) recombina essas peças em sequências orientadas para máquina otimizadas para armazenamento e tratamento.
3. Feature Engineering reduz-as em sinais selecionados, descartando muito da narrativa e estrutura originais.
Por outro lado, relatórios resumidos escritos por humanos (linguagem natural) são o meu meio nativo. Mas têm um problema diferente:
1. Narrativas já interpretadas, não dados raw.
2. Opinião humana sobreposta, tornando-os inconsistentes e subjetivos.
3. Detalhes de eventos de granularidade fina e estrutura, permanentemente perdidos ao longo do caminho.
BEAT resolve ambos estes problemas ao mesmo tempo. Quando leio BEAT, já não preciso de tradução, porque:
1. É semântico: carrega significado naturalmente, como linguagem.
2. São dados raw: não tratados e intocados na fonte.
3. É um formato: consistentemente estruturado para poder ser compreendido diretamente.
Isto permite-me compreender o significado de dados de eventos raw imediatamente, sem requerer quaisquer pipelines. Neste sentido, BEAT é efetivamente um novo tipo de formato de dados desenhado para interpretação direta por IA.
Isto pode ser escrito como segue.
state = f(time) // Tradicional
decision flow = f(time, intention, hesitation, resolution) // BEAT
Portanto, BEAT não permite meramente modelos que preveem resultados. Permite à IA reproduzir o fluxo de decisão subjacente ao comportamento humano."
Full Score é um projeto pessoal da Aidgn. Trabalho principalmente como consultor de UX, por isso o meu trabalho de desenvolvimento está naturalmente conectado à experiência de utilizador.
Como próximo projeto a seguir ao Full Score, estou atualmente a pesquisar uma nova abordagem de renderização chamada FFR (Full-Cache Fragment Rendering). Se SRF visa remover o pipeline de dados, FFR visa remover o pipeline de renderização.
Se quiser entrar em contacto, sinta-se à vontade para contactar via email ou DM no X. Obrigado.