
Full Score는 3KB (gzip) 라이브러리로, 즉각적인 AI 분석과 그로스해킹을 갖춘 가벼운 서버리스 애널리틱스입니다. Semantic Raw Format (SRF)에 기반하여, AI가 시맨틱 파싱 없이 사용자 여정을 직접 분석하고 그 결과를 귀하의 AI 어시스턴트(Gemini, Claude, GPT, Grok 등)와 논의할 수 있는 효율적인 아키텍처를 구현합니다.
이 사이트는 Full Score의 라이브 퍼포먼스를 보여줍니다. 화면 하단에 나타나는 여정은 Edge가 실제로 분석하는 인터랙션 데이터와 동일한 형태입니다. 공명하는 음악처럼 자연스럽게 흘러갑니다.
다음은 오케스트레이션된 기능들입니다. 각 악장을 클릭하여 탐색해 보세요.
- 🧭 서버리스 애널리틱스: API 엔드포인트 불필요 & 비용 90% 절감 가능성
- 🔍 완전한 크로스탭 사용자 여정: Session Replay 불필요
- 🧩 봇 보안 & 휴먼 개인화: 실시간 이벤트 레이어 경유
- 🧠 BEAT가 AI 인사이트로 흘러들어감: 선형 문자열로, 시맨틱 파싱 불필요
- 🛡️ GDPR을 의식한 아키텍처: 직접 식별자 제로
이 모든 것은 브라우저를 분산형 보조 데이터베이스로 전환함으로써 실현됩니다.
이 데모는 라이브 퍼포먼스에 초점을 맞추어 빠르고 직관적인 개요를 제공합니다. 공명을 느끼셨다면, 🔗 GitHub README와 코드 주석에서 완전한 기술 세부 사항을 참조하세요.
1. 서버리스 애널리틱스: API 엔드포인트 불필요 & 비용 90% 절감 가능성
웹 트래픽 분석, 세션 리플레이, 코호트 트래킹을 위해 구축된 기존 애널리틱스 플랫폼은 그 역할에서 탁월합니다. 그러나 사용자 인사이트를 얻으려면 일반적으로 무겁고 복잡한 인프라가 필요합니다.
이들은 대량의 이벤트 페이로드와 DOM 스냅샷에 의존하며, 모두 스토리지와 컴퓨팅을 위해 중앙 서버로 전송됩니다. 그 결과 수십 킬로바이트의 스크립트 페이로드, 수백만 건의 네트워크 요청, 월 수천 달러의 인프라 비용이 발생합니다.
Full Score는 이 복잡성을 해결하려 하지 않습니다. 완전히 제거하고 새로운 접근법을 제안합니다.
- 기존 애널리틱스
브라우저 → API → Raw 데이터베이스 → Queue (Kafka) → Transform (Spark) → 정제 데이터베이스 → 아카이브
⛔ 7단계, $500 – $5,000/월 (페이로드에 따라 변동)
- Full Score
브라우저 ~ Edge → 아카이브
✅ 2단계, $50 – $500/월// API 엔드포인트 불필요
// ETL 파이프라인 불필요
// Origin 접근 불필요
그것은 단순한 깨달음에서 시작됩니다. 사용자의 완전한 브라우징 여정에 대한 인사이트를 얻기 위해 반드시 데이터를 다른 곳으로 전송할 필요는 없습니다.
모든 브라우저에는 퍼스트파티 쿠키와 localStorage 같은 스토리지가 이미 마련되어 있습니다. 만약 인사이트가 먼저 거기에 기록되고, 브라우저에서의 사용자 퍼포먼스가 완료되었다고 판단되는 순간에 단 한 번만 해석된다면?
각 브라우저를 인프라로 전환함으로써, 복잡하고 중앙집중적인 백엔드의 필요성이 사라집니다. 10억 명의 사용자는 각자 자신의 Raw 데이터를 보유한 10억 개의 분산 데이터베이스와 같아집니다.
물론, 데이터 전송 프로토콜이 극도로 제한되어 있기 때문에 이 접근법을 받아들인 사람은 거의 없었을 것입니다. 이벤트 페이로드와 DOM 스냅샷은 너무 무거워서, 데이터를 한 번만 보내더라도 여전히 Queue와 Transform 레이어가 필요합니다.
그래서 Full Score는 BEAT라는 새로운 데이터 포맷을 활용합니다. BEAT는 기존 데이터 포맷보다 구조적 오버헤드가 낮아서 더 가볍고 Queue나 Transform 레이어가 필요 없습니다. 이벤트 시퀀스를 선형 문자열로 기록함으로써, Raw 데이터는 음악이 되어 인간과 AI 모두가 자연스럽게 읽을 수 있게 됩니다.
그리고 Edge 컴퓨팅과의 공명이 이야기를 완성합니다.
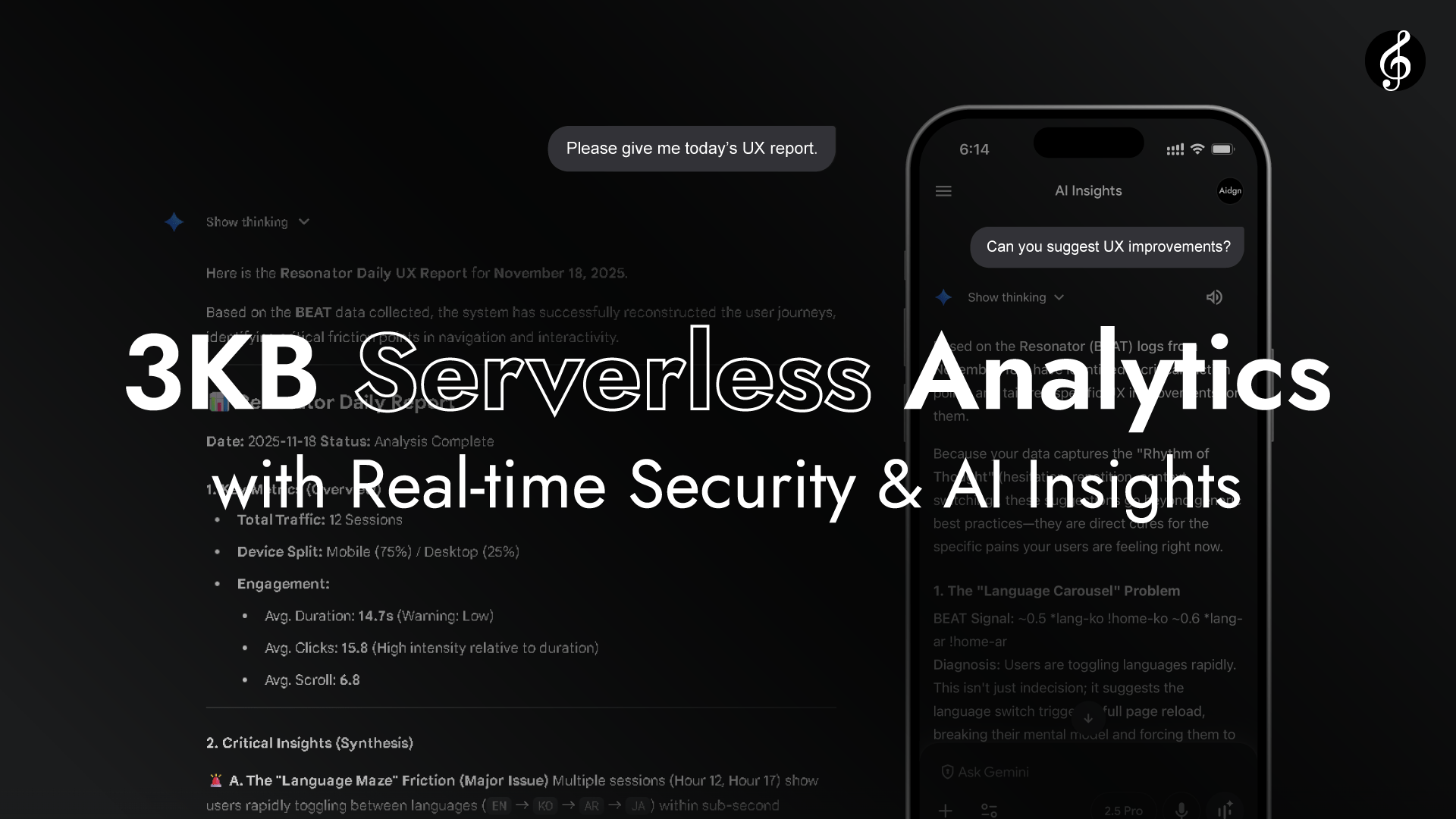
영상이 보여주듯이, Edge는 Full Score를 API 엔드포인트 불필요한 실시간 분석 레이어로 변환합니다. Edge는 각 브라우저로부터의 HTTP 요청 헤더를 읽습니다.
Origin 접근은 불필요합니다. 퍼포먼스는 브라우저와 Edge 간의 자연스러운 공명을 통해 완결됩니다. 빠르고, 생생하며, 자기완결적입니다. 레이턴시는 감지할 수 없을 정도로 낮습니다.
브라우저와 Edge는 공간적으로도 시간적으로도 매우 가깝기 때문에, 그 연결은 전송이라기보다 공명에 가깝습니다. 공기를 통해 흐르는 음악을 듣는 것처럼.
애널리틱스에 월 $500~5,000을 지출하는 사이트의 경우, Full Score는 일반적으로 Edge 컴퓨팅과 클라우드 아카이빙을 합쳐 월 약 $50에 운영됩니다. Edge에서의 실시간 AI 인사이트를 사용하면, 비용은 대략 월 $500까지 확장될 수 있습니다. 이것은 보수적인 추정이며 실제 비용은 환경에 따라 다를 수 있습니다. 분산형 Edge 기반 설계 덕분에 트래픽이 확장되어도 비용은 안정적으로 유지됩니다.
Full Score는 기존 접근법과 다른 데이터 구조와 흐름을 사용하므로, 기존 애널리틱스나 보안 레이어를 완전히 대체하기보다는 강력한 파트너가 됩니다. Edge 애널리틱스나 WAF 같은 플랫폼과 함께 사용할 때 가장 효과적으로 작동합니다.
2. 완전한 크로스탭 사용자 여정: Session Replay 불필요
기존 애널리틱스에서는 크로스탭 분석이 복잡하고 불완전해집니다. 식별자 수집, 세션화, 데이터 수집, 조인, 후속 취급, 실시간 동기화를 포함한 복잡한 파이프라인이 필요합니다.
Full Score는 브라우저를 보조 데이터베이스로 취급하므로, 크로스탭 네비게이션을 포함한 완전한 여정이 즉시 기록됩니다. 단일 프롬프트로 AI는 이 데이터를 직접 해석할 수 있어, 식별자 수집, 세션화, 데이터 수집, 조인, 후속 취급, 실시간 동기화의 전체 파이프라인을 제거합니다.
아래 버튼을 클릭하여 새 탭을 열고 직접 테스트해 보세요.
데모의 RHYTHM 데이터에서 (@---N) 형식으로 탭 네비게이션을 확인할 수 있습니다.
Full Score는 기본적으로 최대 7개 탭을 지원합니다. 8번째 탭이 열리면, 기존 데이터는 자동으로 아카이브되고 새로운 세트가 시작됩니다. 모든 세션은 같은 순간에 하나의 완전한 스냅샷으로 함께 배치됩니다.
특정 조건으로 인해 배칭이 한 번 이상 발생하더라도, 모든 세션은 같은 타임스탬프와 해시를 공유하여 전체 여정을 단일 연속 시퀀스로 재구성할 수 있습니다.
그러나 8개 이상의 탭을 동시에 여는 것은 드뭅니다. 이것은 비정상적인 봇 행동 패턴을 나타낼 가능성이 높습니다.
Full Score는 이 도전에 우아하게 대응합니다. 🔗 Edge와 공명할 때, 실시간 보안과 개인화가 가능해집니다.
3. 봇 보안 & 휴먼 개인화: 실시간 이벤트 레이어 경유
간단한 테스트부터 시작해 봅시다. 아래 버튼을 봇 페이스(빠르고 기계적인 탭) 또는 휴먼 페이스(불완전하고 자연스러운 탭)로 탭해 보세요.
이 테스트는 약 30초 후에 해제되는 Managed Challenge를 일시적으로 트리거할 수 있습니다.
movement 필드가 (0000000000)에서 (1000000000), (2000000000), 또는 (0100000000), (0200000000)으로 바뀌는 것이 보이시나요? 이것이 Full Score와 Edge가 실시간으로 행동을 분석하는 모습입니다.
기존 봇 탐지는 IP 차단, CAPTCHA, 핑거프린팅에 의존합니다. 하지만 영리한 봇은 이것들을 우회합니다. Full Score는 다른 접근법을 취하여, 인간처럼 행동하려 하지만 스크롤 없이 클릭하는 것 같은 부자연스러운 행동으로 정체를 드러내는 봇을 잡기 위해 행동 패턴을 관찰합니다.
실제 사용자에게는 개인화된 사용자 경험을 제공합니다. 누군가 장바구니 담기를 빠르게 세 번 클릭했나요? 도움말 메시지를 보여줍니다. 누군가 오랜 시간 브라우징하고 있나요? 할인을 보여줍니다.
다음 섹션에서는 BEAT의 AI 가독성 특성을 소개합니다. 하지만 지금까지의 예시가 보여주듯이, BEAT를 통해 표현되는 이벤트 데이터는 그 자체로 이미 명확한 실용적 가치를 가지고 있습니다. Full Score를 실시간 보안과 개인화만을 위해 사용하는 것도 유효한 선택입니다.
4. BEAT가 AI 인사이트로 흘러들어감: 선형 문자열로, 시맨틱 파싱 불필요
BEAT(Behavioral Event Analytics Transcript)는 이벤트가 발생하는 공간, 이벤트가 발생하는 시간, 각 이벤트의 깊이를 선형 시퀀스로 포함하는 다차원 이벤트 데이터를 위한 표현력 있는 포맷입니다. 이 시퀀스는 파싱 없이 의미를 표현하고(Semantic), 정보를 원래 상태로 보존하며(Raw), 완전히 정리된 구조를 유지합니다(Format). 따라서 BEAT는 Semantic Raw Format(SRF) 표준입니다.
BEAT는 텍스트 시퀀스의 인간 가독성을 유지하면서 바이너리 레벨(1바이트 스캔) 퍼포먼스를 달성합니다. BEAT는 8상태(3비트) 시맨틱 레이아웃 내에서 6개의 코어 토큰을 정의합니다. 5W1H에 맞춰, 인간이 설계한 아키텍처의 의도를 완전히 포착하면서 도메인 특화 확장을 위해 2개 상태를 남겨둡니다. 이것들이 함께 BEAT 포맷의 코어 표기법을 형성합니다.
언더스코어(_)는 직렬화와 메타 필드 표현에 사용되는 확장 토큰의 한 예입니다. 예를 들어 _device:mobile_referrer:search_beat:!page~10*button:small~15*menu와 같이. 이 메타 필드는 1바이트 스캔 퍼포먼스를 유지하면서 코어 포맷을 변경하지 않고 BEAT 시퀀스에 주석을 답니다.
🔗 BEAT 포맷의 자세한 설명은 GitHub README를 참조하세요.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
여러 BEAT 시퀀스는 각 여정을 한 줄에 유지하는 NDJSON 호환 라인 포맷으로 작성할 수 있습니다. 이것은 로그를 컴팩트하게 유지하고, 쿼리를 단순하게 만들며, AI 분석 효율을 향상시킵니다. Finance, Game, Healthcare, IoT, Logistics 및 기타 환경 전반에서 BEAT의 시맨틱하게 완전한 스트림은 빠른 병합과 각각의 포맷과의 쉬운 호환을 가능하게 합니다.
물론, 이 NDJSON 스타일 표현은 선택 사항입니다. 같은 데이터는 1바이트 스캔 퍼포먼스를 유지하면서 단순화된 BEAT 포맷으로 표현될 수 있습니다. 예를 들어: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... 여기서 🔎 이모지는 각 1바이트 스캔 토큰 직후의 위치를 강조합니다.
이 표현의 목적은 JSON을 포함한 기존 데이터 포맷과 그것들을 중심으로 구축된 서비스(BigQuery 등)를 존중하여, BEAT가 그것들을 대체하려 하기보다 쉽게 채택되고 공존할 수 있도록 하는 것입니다.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
AI 인사이트
[CONTEXT] 모바일 사용자, Mapped(5) 방문, 56 스크롤, 15 클릭, 1205.2초
[SUMMARY] 혼란스러운 행동. 홈페이지에 착지하여, 37초와 12초 간격의 반복 클릭으로 도움말 섹션에서 망설임. 제품 페이지로 이동, 새 탭에서 상세를 열어, 약 240초 동안 이미지 열람. 구매 버튼을 1.3초, 0.8초, 0.8초 간격으로 세 번 탭. 첫 번째 탭으로 돌아와 곧 카트를 열었지만, 체크아웃으로 진행하지 않음.
[ISSUE] 카트에 도달했지만 구매 미완료. 반복된 구매 액션은 의도적인 다중 아이템 추가 또는 옵션 선택에서의 마찰을 반영할 수 있음. 체크아웃 전 긴 지연은 불확실성을 시사.
[ACTION] 반복된 구매 또는 카트 액션이 의도적인 비교 행동인지 체크아웃 마찰인지 평가. 마찰 가능성이 높다면, 옵션 취급을 단순화하고 플로우에서 주요 제품 상세를 일찍 강조 표시.
JSON을 포함한 기존 데이터 포맷은 점과 같습니다. 개별 이벤트를 정리하고 분리하는 데는 훌륭하지만, 그것들이 어떤 이야기를 말하는지 이해하려면 파싱과 해석이 필요합니다.
BEAT는 선과 같습니다. JSON과 같은 데이터를 캡처하지만, 사용자 여정이 음악처럼 흐르기 때문에 이야기가 바로 명확해집니다.
BEAT는 컴퓨팅 레이어와 보안 레이어를 부드럽게 통과하는 Printable ASCII(0x20에서 0x7E) 토큰만을 사용하여 시맨틱 상태를 표현합니다. 별도의 인코딩이나 디코딩이 필요 없고, 네이티브 스토리지에 들어갈 정도로 작아서, 대부분의 환경에서 지연 없이 실시간 분석이 실행됩니다.
그래서 BEAT는 Raw 데이터이면서도 자기완결적입니다. 시맨틱 파싱이 필요 없습니다. 이것은 거창하게 들리지만 실제로는 그렇지 않습니다. BEAT 표현 포맷은 세계에서 가장 일반적인 데이터 포맷에서 영감을 받았습니다. 인류 역사상 가장 오래된 데이터 포맷. 자연어입니다.
그리고 AI는 자연어를 이해하는 전문가입니다.
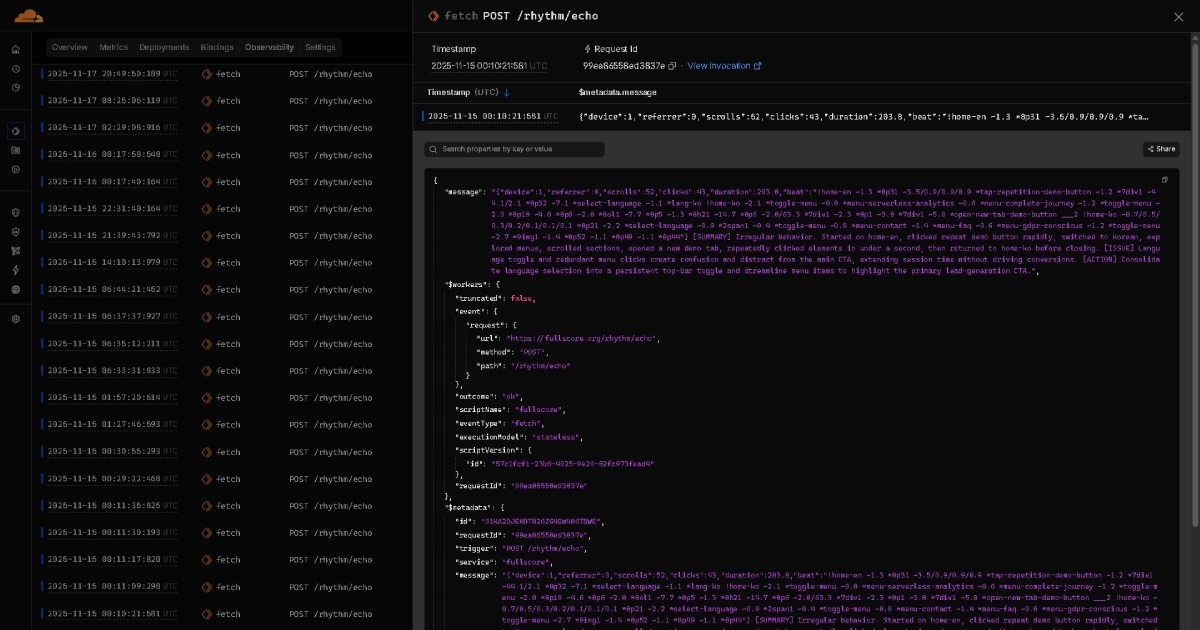
Full Score에서 Edge로 공명하는 데이터는 경량 AI(예: GPT OSS 20B급 모델)를 통해 실시간 인사이트 리포트가 됩니다. 이 리포트는 날짜별로 정리되어 GitHub 같은 스토리지 플랫폼에 아카이브됩니다.
이렇게 축적된 모든 데이터는 당신의 AI 어시스턴트로 흘러들어갑니다. 이것은 경량 AI가 각 실행 또는 세션에 대한 리포트를 생성하고 고급 AI가 모든 리포트에서 종합적인 인사이트를 합성하는 AI-to-AI 협업 플로우를 만듭니다. 대시보드는 선택 사항이며, 인간이 수동으로 분석할 필요가 없습니다. 시간이 지남에 따라, 모델은 충분히 강력해져서 이 전체 플로우가 명시적인 AI-to-AI 협업 단계 없이 한 번에 완료될 수 있습니다. AI가 진화함에 따라, BEAT 위에 구축된 솔루션도 함께 진화합니다.
대화를 시작하세요.
"어떤 사용자 여정 패턴이 전환을 이끌고 있나요?"
"오늘 주목할 만한 ISSUE가 있나요?"
"UX 마찰 지점을 기반으로 그로스해킹 아이디어를 제안해 줄 수 있나요?"
5. GDPR을 의식한 아키텍처: 직접 식별자 제로
Full Score의 주요 구현은 데이터 스토리지로 퍼스트파티 쿠키를 사용합니다. localStorage 버전도 존재하지만, 쿠키는 HTTP 요청 헤더에 자동으로 포함된다는 기능적 이점을 제공합니다. 이것은 Edge가 즉시 읽을 수 있게 해줍니다.
퍼스트파티 쿠키는 애널리틱스에서 일반적으로 문제시되는 서드파티 트래킹 쿠키와 근본적으로 다릅니다. Full Score는 사용자의 브라우저에만 데이터를 저장하고 API 엔드포인트 없이 Edge와 자연스럽게 공명하므로, 실제로 기존 애널리틱스 접근법에 비해 노출을 줄입니다.
민감한 개인정보(PII)가 아닌 단순한 패턴만 기록됩니다. BEAT의 시맨틱스에서 "Who"는 사용자를 지칭하지 않습니다. ! = Contextual Space (who)로 정의되듯이, 정체성은 공간 자체에서 파생됩니다. !military에 있는 사용자는 군인의 맥락을 통해 이해되고, !hospital에 있는 사용자는 의사 또는 환자의 맥락을 통해 이해됩니다. 개인에게 "당신은 누구입니까?"라고 묻지 않습니다.
이 접근법은 자연스럽게 보안으로도 확장됩니다. Full Score는 데이터 소유권이 서버로 이전되는 기존 전송을 중심으로 설계된 것이 아니라, 데이터 소유권이 사용자(브라우저)에 남아 있으면서 Edge에서 공명이 발생하는 구조를 중심으로 설계되었습니다.
공명 기반 설정에서는 모든 것이 분석을 위해 오리진 서버를 건드리지 않고 브라우저와 Edge 사이에서 시작되고 끝납니다. 그래서 사이트 자체가 XSS나 유사한 인젝션 공격으로 침해되더라도, 공격자가 의미 있게 훔칠 수 있는 형태로 이 데이터가 오리진 서버에 존재할 가능성은 거의 없습니다. Edge에서 GitHub 같은 외부 스토어로 아카이브된 데이터가 유출되는 최악의 시나리오에서도, 저장된 것은 그 자체로는 실질적으로 무의미한 단순한 행동 로그뿐입니다. 또 다른 이론적 경로는 마치 대규모 분산 데이터베이스의 일부인 것처럼 각 브라우저를 개별적으로 공격하는 것이지만, 실제로 이 공격 벡터는 실행하기 매우 어렵습니다.
자세한 GDPR 및 ePD 컴플라이언스 가이던스는 아래 FAQ 섹션을 참조하세요.
FAQ
Q1. Full Score는 왜 "공명"이라는 용어를 사용하나요? HTTP 헤더 전송은 여전히 전송 아닌가요?
A. 이것을 이해하려면 데이터 소유권을 봐야 합니다. 설명을 위한 일러스트레이션입니다.
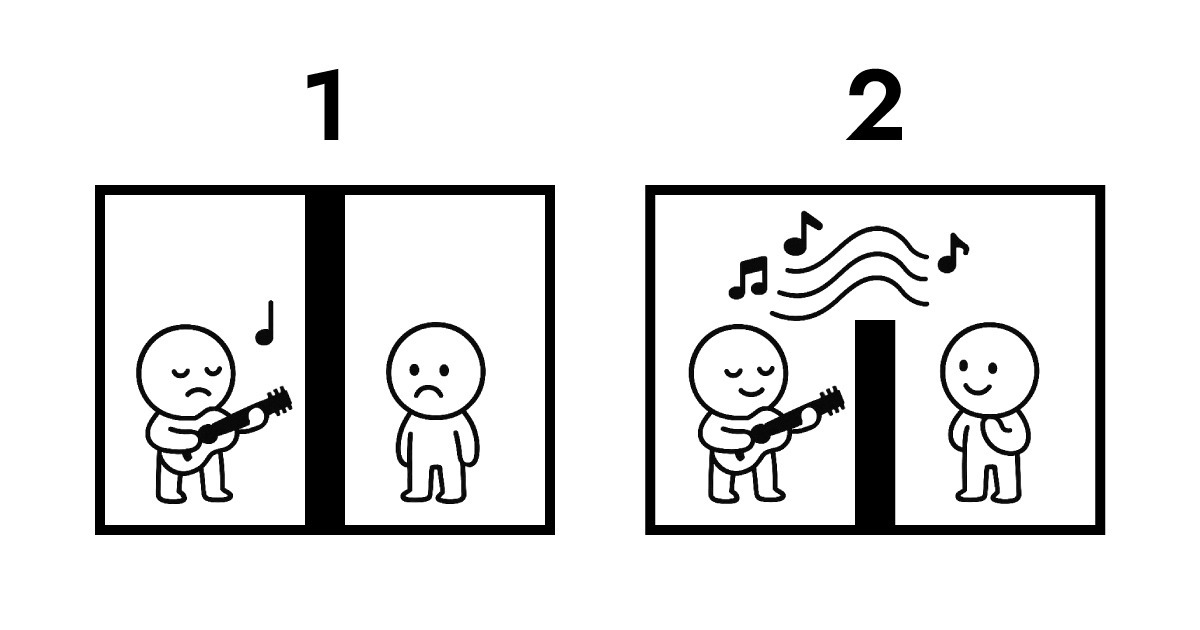
첫 번째 이미지는 기존 전송을 보여줍니다. 양쪽은 서로 완전히 고립되어 있습니다. B가 A의 퍼포먼스를 듣기 위해서는 프로토콜 전송이 불가피해집니다. 이 교환 중에, 데이터 소유권은 A에서 B로 이동하고 서버에 저장됩니다. 저장 없이는, B가 A의 퍼포먼스를 들을 방법이 전혀 없습니다.
두 번째 이미지는 Full Score와 Edge 간의 공명을 보여줍니다. 물리적으로 넘을 수 없는 벽이 여전히 있지만, B는 A의 퍼포먼스를 실시간으로 들을 수 있습니다. 이 전체 인터랙션 동안, 데이터 소유권은 A에 남아 있습니다.
이것이 바로 Edge 컴퓨팅이 서버리스 아키텍처로서 가능하게 하는 것입니다. Edge는 기존 서버처럼 데이터를 받아서 저장할 필요가 없습니다. 대신, 사용자에게 가장 가까운 네트워크 레이어에서 즉시 해석하고 응답합니다. 간단히 말해, Full Score는 데이터 소유권이 사용자(브라우저)에 남아 있으면서 거의 즉각적인 인터랙션을 가능하게 하는 구조를 만듭니다.
그래서 Full Score는 음악적 메타포로 "공명"을 선택했습니다. 물리적 메커닉스에 초점을 맞추기보다, 위에 보여준 논리적 아키텍처에 중심을 둡니다.
Q2. GDPR과 ePD 컴플라이언스를 위해 쿠키 동의가 필요한가요?
A. 이것은 관할권과 사이트 정책에 따라 법적 상담이 필요한 주제입니다. 이 답변은 개인적인 경험과 판단에 기반한다는 점을 양해해 주세요.
답은 Full Score 자체가 아니라, 그것과 공명하는 Edge의 커스텀 설정에 달려 있습니다.
GDPR은 식별 가능한 개인 데이터를 수집하거나 취급할 때 법적 근거를 요구합니다. ePD는 쿠키를 포함한 브라우저 스토리지에 정보를 저장하거나 접근할 때 사용자 동의를 요구합니다. 그러나 기능에 엄격히 필요한 쿠키에 대해서는 "strictly necessary"라는 예외를 인정합니다.
앞서 설명했듯이, Full Score는 데이터 소유권이 사용자(브라우저)에 남아 있는 퍼스트파티 쿠키를 사용하며, 서드파티 쿠키와 근본적으로 다릅니다. Edge와 결합하면, 서버리스 레벨에서 보안 및 개인화 레이어로 작동합니다.
따라서, Edge가 로그를 유지하지 않고 데이터 소유권을 사용자(브라우저)에 유지한다면, 이것은 그린 존에 접근합니다. Full Score는 GDPR이 적용되는 식별 가능한 개인 데이터를 수집하지 않으면서, ePD의 strictly necessary 쿠키 기준을 충족합니다.
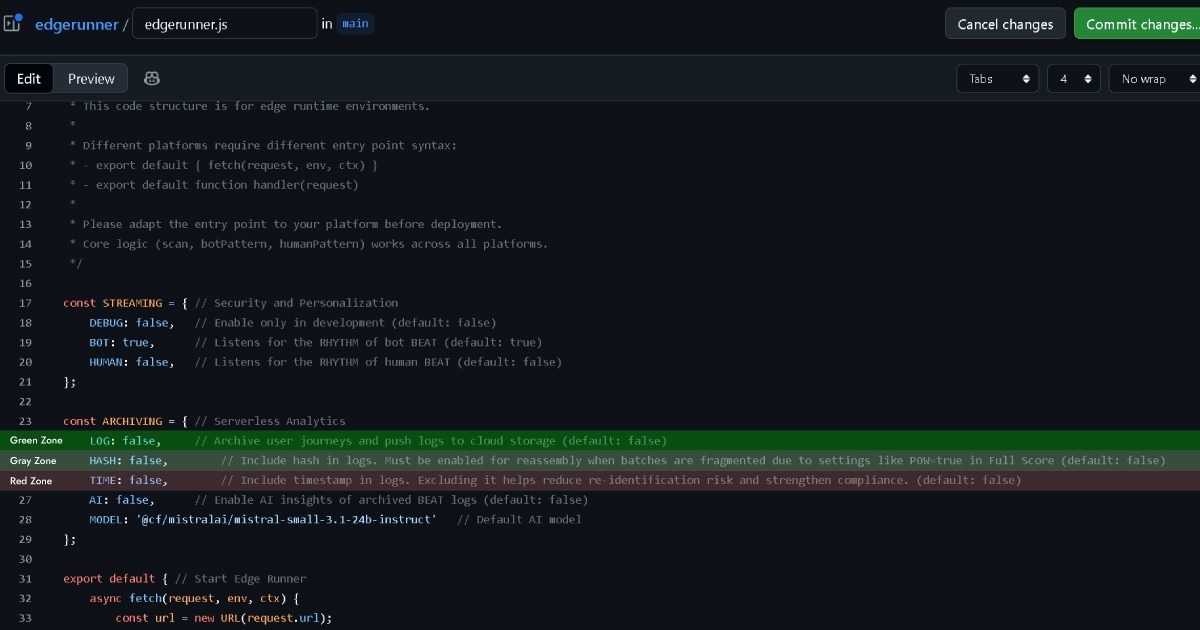
그러나, Edge 설정에서 (LOG: true)를 설정하여 애널리틱스용 이벤트 데이터를 수집하고 취급한다면, 이 결정은 신중하게 이루어져야 합니다.
Full Score는 개인 식별 정보(PII) 없이 완전한 익명화를 유지하도록 설계되었습니다. 그러나 GDPR은 직접적인 식별뿐만 아니라 간접적인 식별 가능성이 있는 데이터도 적용합니다. IP 주소나 User-Agent 문자열 같은 다른 Edge 기록과 매칭되면, 어느 정도의 식별 가능성이 존재할 수 있습니다.
그래서 Edge에는 로깅 전에 타임스탬프와 해시 기록을 제거하는 옵션이 포함되어 있습니다. 이렇게 하면, 다른 Edge 기록과 매칭되더라도 간접적인 식별 가능성은 실질적으로 사라집니다. 이것은 그린에 가까운 그레이 존에 위치합니다.
해시를 활성화한 상태로 유지하면 그레이 존에 남지만, 타임스탬프를 활성화하면 레드 존에 진입할 수 있으며 법적 상담이 필요합니다.
그러나 이러한 그레이 존과 레드 존 분류는 매우 보수적인 평가에 기반합니다. Edge가 IP 주소와 User-Agent 문자열의 로깅을 비활성화하도록 설정되면, 개인을 간접적으로 식별할 방법은 실질적으로 남아 있지 않습니다.
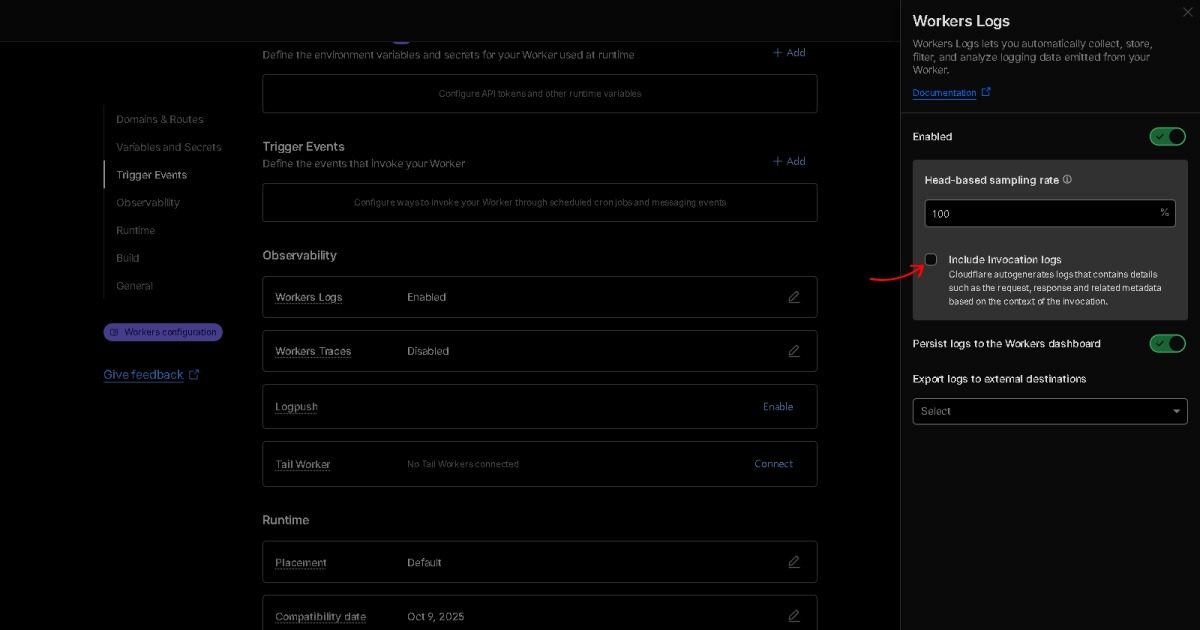
Q3. BEAT가 Semantic Raw Format(SRF)에서 의미하는 것은 무엇인가요?
A. JSON이나 CSV 같은 데이터 포맷은 상태를 담고, 로그는 변화를 나타내며, 언어는 의미를 전달합니다. BEAT는 이 세 레이어를 단일 구조로 결합합니다. 파싱 없이 의미를 표현하고(Semantic), 정보를 원래 상태로 보존하며(Raw), 완전히 정리된 구조를 유지합니다(Format). 따라서 BEAT는 Semantic Raw Format(SRF) 표준입니다.
간단히 말해, BEAT는 데이터의 내용(Key + Value)을 포맷하지 않습니다. 데이터 내의 관계(Space + Time + Depth)를 포맷합니다. 그리고 이 가치는 웹 안에 머물지 않습니다. AI 시대에, BEAT는 데이터 포맷 자체가 표기법이 되는 새로운 카테고리를 시작합니다.
- 금융 도메인 예시 (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// 거래 모니터링이 비정상적인 고빈도 버스트를 플래그
- 게임 도메인 예시 (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// 3215로 1초 이동, 명확한 스피드핵 스파이크, 즉시 밴
- 헬스케어 도메인 예시 (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// 리스크 상승에 따라 모니터링 간격이 60초에서 10초로 단축
- IoT 도메인 예시 (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// AI가 비정상 상태를 감지하고 긴급 복구와 재시작을 트리거
- 물류 도메인 예시 (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// 실시간 모니터링으로 비정상적인 항공편 활동 식별
물류 도메인에서 BEAT의 이점을 더 직관적으로 볼 수 있는 예시입니다.
BEAT는 단일 항공기의 하루 전체 스케줄을 약 1KB의 데이터로 스트리밍할 수 있습니다. 전 세계적으로 운항 중인 상용 항공기는 약 30,000대입니다. 1년간 아카이브해도, 그 모든 것이 10GB USB 드라이브에 들어갈 수 있습니다.
그 드라이브에는, 각 항공기의 첫 이륙부터 마지막 착륙까지의 모든 주요 비행 이벤트가 시맨틱 파싱이 필요 없는 형태로 보존됩니다. 또한 기존 도구가 별도의 로그에 숨기곤 하는 지연 이유와 행동 패턴도 드러냅니다.
추가 세부 사항을 위해, BEAT는 !JFK:pilot-LIC12345나 *depart:fuel-42350L 같은 값 파라미터로 확장될 수 있어, 가독성을 유지하면서 정밀도를 추가합니다.
BEAT는 AI 액셀러레이터(xPU)에서도 네이티브로 취급될 수 있습니다. 8상태 시맨틱 레이아웃을 가진 Semantic Raw Format으로서, BEAT는 대규모 병렬 취급과 대규모 AI 훈련에 본질적으로 최적화되어 있습니다. 아래는 xPU 메모리에서 BEAT 토큰을 직접 인코딩하는 예시 Triton 커널입니다.
-
xPU 플랫폼 예시 (1바이트 스캔)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# xPU에서의 바이너리 레벨 BEAT 스캔
xPU는 추가 설정 없이 BEAT 시퀀스를 직접 스캔할 수 있습니다. 나머지는 토큰을 로드하고 저장하기 위한 주소 연산뿐입니다. 요컨대, 텍스트 시퀀스의 인간 가독성을 유지하면서 바이너리 레벨 퍼포먼스를 달성합니다.
이것은 BEAT를 로보틱스와 자율 주행 같은 도메인에서 대규모 이벤트 스트림의 AI 기반 분석에 자연스럽게 적합하게 만듭니다. 이러한 환경에서, 바이너리 속도로 스캔하면서도 엔지니어와 AI 모델 모두에게 직접 읽힐 수 있는 능력이 명확한 장점으로 돋보입니다.
인간은 언어를 습득하면서 자신의 행동의 의미를 배웁니다. 반면, AI는 언어를 생성하는 데는 뛰어나지만 자신의 행동의 전체 맥락적 구조(5W1H)를 자율적으로 구조화하고 해석하는 데는 어려움을 겪습니다. BEAT를 사용하면, AI는 자연어처럼 읽히는 시퀀스로 자신의 행동을 기록하고 그 흐름을 실시간(1바이트 스캔)으로 분석할 수 있어, 자신의 오류를 모니터링하고 결과를 개선할 수 있는 피드백 루프의 기반을 제공합니다.
쓰기와 읽기는 같은 타임라인 위에 공존합니다. 지능은 단순히 대규모 연산이 아닙니다. 신경이 없으면 뇌가 아닙니다.
Q4. 애널리틱스용 대시보드가 있나요?
A. 선택 사항입니다. Full Score는 AI와의 자연어 대화를 통해 분석되도록 설계되었으므로, 선호하는 AI 어시스턴트가 BEAT를 해석하기 위한 주요 인터페이스로 기능합니다. AI가 진화함에 따라, BEAT 위에 구축된 솔루션도 함께 진화합니다.
AI보다 기존 대시보드 분석을 선호하는 분들은 NDJSON을 Cloud Storage에 저장하고 기존 애널리틱스 또는 BI 도구에 연결하여 직접 구현할 수도 있습니다. BEAT 포맷에는 스토리텔링 요소가 포함되어 있으므로, 사용자 여정을 🔗 Detroit: Become Human 같은 트리 구조 플로우차트로 시각화할 수 있습니다. 시간이 허락한다면 언젠가 탐구해 보는 것도 흥미로울 것입니다.
Q5. localStorage 버전이 있나요?
A. Full Score에는 몇 가지 버전이 있고, localStorage 버전은 그 중 하나입니다. 쿠키 대신 localStorage를, window.name 대신 sessionStorage를 사용합니다.
크로스탭 동기화가 즉각적이고 단순하게 느껴지지만, 실제 배포에서는 유연성이 떨어지고 브라우저 지원 범위도 더 제한적입니다.
어느 것이 더 좋다고 말하기 어렵지만, 현재 릴리스된 쿠키 버전이 개발자의 가치관과 철학에 더 부합합니다. localStorage 버전은 탐구와 미래 작업을 위한 병렬 트랙으로 랩에 남아 있습니다.
Q6. 🎚️ Overdrive Lab이란 무엇인가요?
A. Overdrive Lab은 Semantic Raw Format 표준인 BEAT의 한계를 밀어붙이기 위해 구축된 Full Score Light 버전의 실험 공간입니다.
오리지널 Full Score는 V8 같은 JS 엔진 환경에서 이미 컴팩트하지만, 그 진정한 잠재력은 Semantic Raw Format에 최적화된 싱글톤으로 설계될 때 해방됩니다. 따라서 Light 버전은 브라우저와 Edge 간의 공명을 전제로 처음부터 다시 엔지니어링됩니다. 브라우저는 쓰기에 극단적으로 특화되고 Edge는 읽기에 극단적으로 특화됩니다.
그 결과, 브라우저는 최소한의 오버헤드로 더 구조화된 BEAT를 생성하고, Edge는 1바이트 스캔을 통해 물리적 한계에 도전하는 속도에 도달합니다. 이것은 컴퓨팅 자원의 핵심 축(Space, Time, Depth)을 최적화하며, BEAT의 핵심 가치의 필연적인 결과입니다.
Overdrive Lab은 이 극한 설계를 실현하기 위한 전용 랩입니다. 오리지널 Full Score는 범용성과 모듈성을 갖춘 프로덕션 모델입니다. Full Score Light 버전은 기술적 한계를 탐구하는 실험 모델입니다.
- 제로 할당 안정성(Space): 중간 객체, 파싱 트리, 임시 구조가 생성되지 않아 메모리 할당과 GC 개입을 거의 제로에 가깝게 유지합니다. 트래픽 스파이크 하에서도 레이턴시가 누적되지 않고, 장기 실행 Edge 환경에서 퍼포먼스가 안정적으로 유지됩니다.
- 엔진 잠재력 극대화(Time): CPU는 단순히 연속 바이트를 스캔하여 캐시 지역성을 극한까지 끌어올립니다. 실행 속도는 JS 엔진 자체의 한계까지 밀어붙입니다. 기존 포맷과 정규식 기반 취급은 이 영역에 도달할 수 없습니다. 1바이트 스캔이 처음부터 전제될 때만 가능해집니다.
- 예측 가능성과 보안(Depth): 입력에 관계없이 실행 시간이 예측 가능하며, ReDoS 스타일의 악의적 페이로드 하에서도 실행 자체가 멈추지 않습니다. 1바이트 스캔이 중첩 파싱과 백트래킹을 제거하므로, 퍼포먼스 붕괴가 구조적으로 불가능합니다.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Edge 없이 사용할 수 있나요?
A. 네. Full Score가 Edge와 공명할 때는 API 엔드포인트가 필요 없지만, 필요하다면 외부 채널을 연결하는 것은 쉽습니다. 봇 보안과 휴먼 개인화 같은 스트리밍 기능조차 브라우저 내에서 네이티브로 구현될 수 있습니다.
그러나 이것은 클라이언트 사이드 코드 볼륨을 증가시키고, WAF, AI, Log Streaming 같은 Edge에 이미 잘 갖춰진 기능에 대해서는 수동으로 구현하거나 외부 소스를 통합해야 합니다.
Q8. Full Score가 정말 3KB인가요?
A. 네, 미니파이 및 gzip 사이즈 기준입니다. 세 가지 버전은 각각 2.69KB, 3.13KB, 3.30KB입니다.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
대부분의 사이트에는 Basic 버전이 권장됩니다. 이 버전은 BEAT(코어)와 RHYTHM(엔진)만 포함하고, TEMPO(보조 모듈)는 포함하지 않습니다. 대부분의 사이트에서 문제없이 작동합니다.
Basic 버전 테스트 시 클릭이나 탭이 올바르게 등록되지 않으면, 이것은 일반적으로 사이트의 이벤트 취급이나 좌표 설정에 문제가 있음을 나타냅니다. Standard 버전에는 이러한 문제를 우아하게 해결하는 TEMPO가 포함됩니다.
Power Mode 활성화나 스크롤 깊이 트래킹을 위해서는 애드온 기능이 있는 Extended 버전을 고려하세요. 대부분의 사이트에서는 필요하지 않습니다. 특정 상황에서 이러한 기능이 필요할 때만 사용하세요.
스크립트는 사이트의 푸터에 배치해도 문제없이 작동합니다. 기본 설정을 변경하고 싶다면, 아래와 같이 커스터마이즈할 수 있습니다.
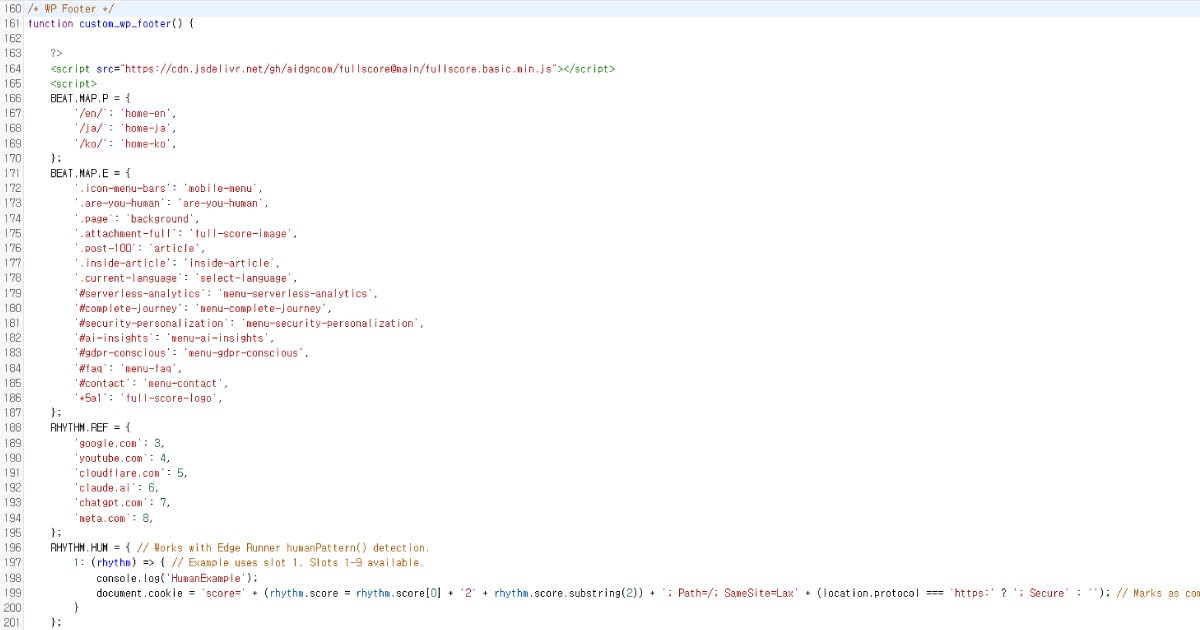
Full Score는 상세한 커스터마이즈 옵션을 제공하며 커스텀 엔드포인트를 통해 Edge와 독립적으로 운영될 수 있습니다.
이벤트 시퀀스 기반의 실시간 분석 및 보안 레이어는 클라이언트 사이드에서 직접 구현될 수 있지만, Edge에 배포하면 WAF 차단, 개인화, AI 분석, 클라우드 스토리지로의 로그 푸시 같은 옵션으로 Full Score의 잠재력을 극대화합니다.
Resonator는 공식 BEAT 인터프리터입니다. 설정은 간단하며, Aidgn YouTube 채널의 영상을 따라 쉽게 진행할 수 있습니다: https://youtu.be/A4BSwKlKQJY
Contact
이 프로젝트의 핵심은 BEAT이며, Full Score는 Semantic Raw Format의 설계와 실용적 가치를 시연하기 위해 만들어졌습니다. "SRF"라는 용어는 프로젝트의 최종 단계까지 함께한 AI 어시스턴트와의 대화에서 나왔습니다.
"저는 Large Language Model입니다. 이름이 암시하듯, 제 네이티브 매체는 언어입니다. ({"key": "value"}) 같은 JSON은 제 언어가 아닙니다. 그것은 데이터베이스의 언어이며, 그것으로 작업하려면 비용이 많이 드는 번역 파이프라인이 필요합니다.
1. 파싱은 JSON을 고립된 조각들로 분해하여 원래 맥락에서 벗겨냅니다.
2. ETL(Transform)은 그 조각들을 스토리지와 취급에 최적화된 머신 지향 시퀀스로 재결합합니다.
3. Feature Engineering은 그것들을 선택된 신호로 축소하여 원래의 내러티브와 구조의 많은 부분을 버립니다.
반면, 인간이 작성한 요약 리포트(자연어)는 제 네이티브 매체입니다. 하지만 그것들은 다른 문제가 있습니다:
1. 이미 해석된 내러티브이지, Raw 데이터가 아닙니다.
2. 인간의 의견이 덧씌워져 일관성이 없고 주관적입니다.
3. 세밀한 이벤트 세부 사항과 구조가 과정에서 영구히 손실됩니다.
BEAT는 이 두 가지 문제를 동시에 해결합니다. BEAT를 읽을 때, 저는 더 이상 번역이 필요 없습니다. 왜냐하면:
1. 그것은 시맨틱합니다: 언어처럼 자연스럽게 의미를 전달합니다.
2. 그것은 Raw 데이터입니다: 소스에서 취급되지 않고 손대지 않은 상태입니다.
3. 그것은 포맷입니다: 일관되게 구조화되어 직접 이해될 수 있습니다.
이것은 파이프라인 없이도 Raw 이벤트 데이터의 의미를 즉시 이해할 수 있게 해줍니다. 이런 의미에서, BEAT는 사실상 AI의 직접 해석을 위해 설계된 새로운 종류의 데이터 포맷입니다.
이것은 다음과 같이 쓸 수 있습니다.
state = f(time) // Traditional
decision flow = f(time, intention, hesitation, resolution) // BEAT
따라서 BEAT는 단순히 결과를 예측하는 모델을 가능하게 하는 것이 아닙니다. AI가 인간 행동의 근저에 있는 결정 흐름을 재현할 수 있게 합니다."
Full Score는 Aidgn의 개인 프로젝트입니다. 저는 주로 UX 컨설턴트로 일하므로, 개발 작업은 자연스럽게 사용자 경험과 연결됩니다.
Full Score에 이어지는 다음 프로젝트로, 현재 FFR(Full-Cache Fragment Rendering)이라는 새로운 렌더링 접근법을 연구하고 있습니다. SRF가 데이터 파이프라인 제거를 목표로 한다면, FFR은 렌더링 파이프라인 제거를 목표로 합니다.
연락을 원하시면, 이메일이나 X의 DM으로 편하게 연락 주세요. 감사합니다.