
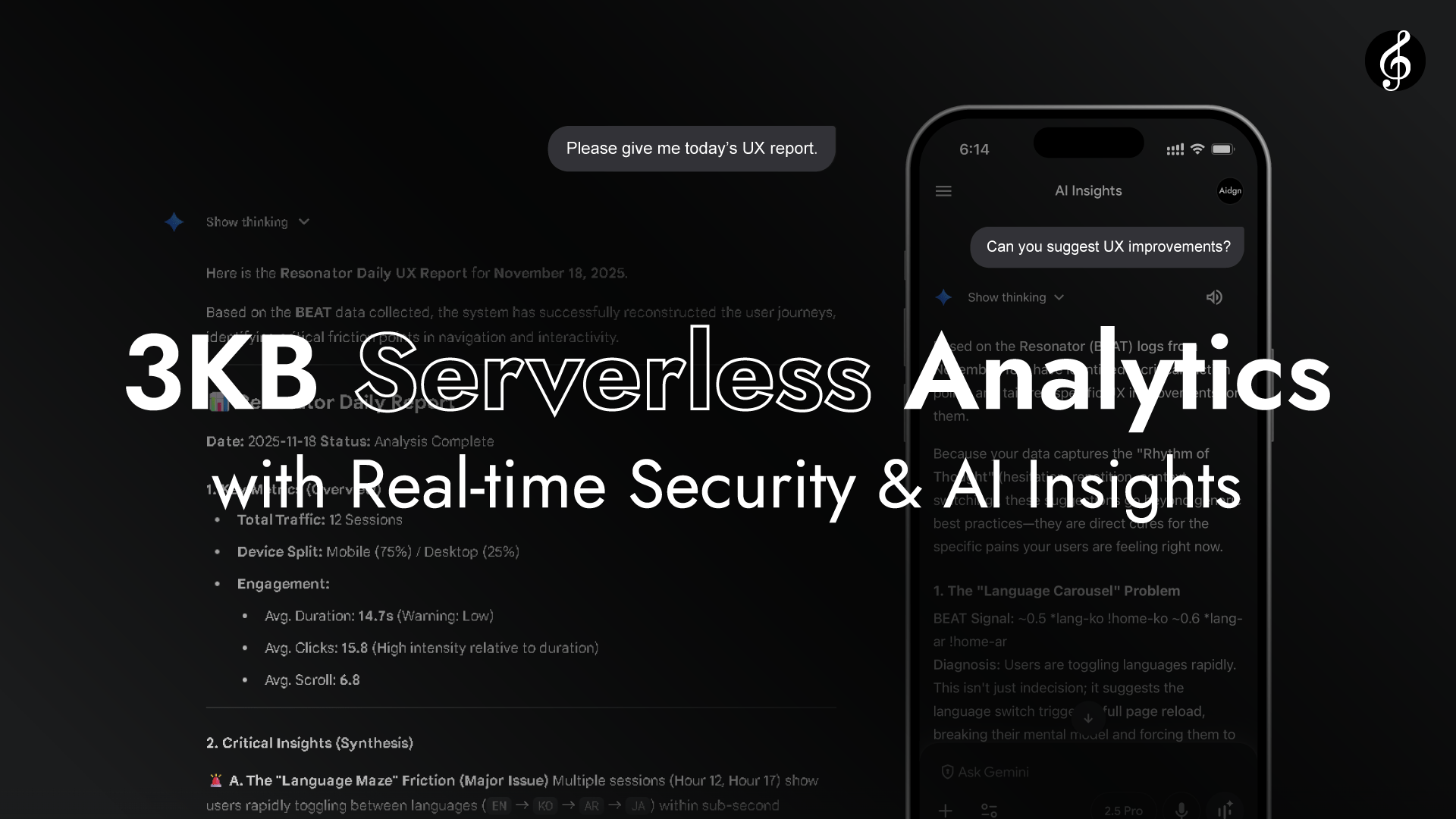
Full Scoreは3KB (gzip) のライブラリで、即時のAI分析とグロースハッキングを備えた軽量サーバーレスアナリティクスです。Semantic Raw Format(SRF)に基づき、AIがセマンティック解析なしでユーザージャーニーを直接分析し、その結果をあなたのAIアシスタント(Gemini、Claude、GPT、Grokなど)と議論できる効率的なアーキテクチャを実装しています。
このサイトではFull Scoreのライブパフォーマンスを紹介しています。画面下部に表示されるジャーニーは、Edgeが実際に分析するインタラクションデータと同じ形式です。共鳴する音楽のように、自然に流れていきます。
以下がオーケストレーションされた機能です。各楽章をクリックして探索してください。
- 🧭 サーバーレスアナリティクス:APIエンドポイント不要、コスト90%削減の可能性
- 🔍 完全なクロスタブユーザージャーニー:Session Replay不要
- 🧩 ボットセキュリティと人間向けパーソナライゼーション:リアルタイムイベントレイヤー経由
- 🧠 BEATがAIインサイトへ流れ込む:線形文字列として、セマンティック解析不要
- 🛡️ GDPRを意識したアーキテクチャ:直接識別子ゼロ
これらすべては、ブラウザを分散型補助データベースに変えることで実現されます。
このデモはライブパフォーマンスに焦点を当て、素早く直感的な概要を提供します。共鳴を感じたら、🔗 GitHubのREADMEとコードコメントで完全な技術詳細をご覧ください。
1. サーバーレスアナリティクス:APIエンドポイント不要、コスト90%削減の可能性
Webトラフィック分析、セッションリプレイ、コホートトラッキング向けに構築された従来のアナリティクスプラットフォームは、その役割において優れています。しかし、ユーザーインサイトを得るには通常、重くて複雑なインフラが必要です。
これらは大量のイベントペイロードとDOMスナップショットに依存し、すべてストレージと計算のために中央サーバーへ送信されます。結果として、数十キロバイトのスクリプトペイロード、数百万のネットワークリクエスト、月額数千ドルのインフラコストが発生します。
Full Scoreはこの複雑さを解決しようとはしません。それを完全に取り除き、新しいアプローチを提案します。
- 従来のアナリティクス
ブラウザ → API → Rawデータベース → Queue (Kafka) → Transform (Spark) → 精製データベース → アーカイブ
⛔ 7ステップ、$500 – $5,000/月(ペイロードにより変動)
- Full Score
ブラウザ ~ Edge → アーカイブ
✅ 2ステップ、$50 – $500/月// APIエンドポイント不要
// ETLパイプライン不要
// Originアクセス不要
それはシンプルな気づきから始まります。ユーザーの完全なブラウジングジャーニーへのインサイトを得るために、必ずしもデータを別の場所に送信する必要はありません。
すべてのブラウザには、ファーストパーティCookieやlocalStorageなどのストレージがすでに用意されています。もしインサイトがまずそこに記録され、ブラウザでのユーザーのパフォーマンスが完了したと判断された瞬間に一度だけ解釈されるとしたら?
各ブラウザをインフラに変えることで、複雑で中央集権的なバックエンドの必要性がなくなります。10億人のユーザーは、それぞれが自分のRawデータを保持する10億の分散データベースのようになります。
もちろん、データ転送プロトコルが極めて限られているため、このアプローチを受け入れる人はほとんどいなかったでしょう。イベントペイロードとDOMスナップショットは重すぎるため、一度だけデータを送信する場合でもQueueとTransformレイヤーが必要です。
そのためFull ScoreはBEATという新しいデータフォーマットを活用します。BEATは従来のデータフォーマットより構造的オーバーヘッドが低いため、より軽量でQueue やTransformレイヤーを必要としません。イベントシーケンスを線形文字列として記録することで、Rawデータは音楽となり、人間とAIの両方が自然に読めるようになります。
そしてEdgeコンピューティングとの共鳴がストーリーを完成させます。
動画が示すように、EdgeはFull ScoreをAPIエンドポイント不要のリアルタイム分析レイヤーに変換します。Edgeは各ブラウザからのHTTPリクエストヘッダーを読み取ります。
Originアクセスは不要です。パフォーマンスはブラウザとEdge間の自然な共鳴を通じて完結します。速く、鮮やかで、自己完結型です。レイテンシは感知できないほど低いです。
ブラウザとEdgeは空間的にも時間的にも非常に近いため、その接続は送信というより共鳴に似ています。空気を通じて流れる音楽を聴くように。
アナリティクスに月額$500〜5,000を費やしているサイトの場合、Full Scoreは通常、Edgeコンピューティングとクラウドアーカイブを合わせて月額約$50で運用できます。EdgeでのリアルタイムAIインサイトを使用すると、コストは最大約$500/月まで拡大する可能性があります。これは控えめな見積もりであり、実際のコストは環境によって異なる場合があります。分散型でEdgeベースの設計により、トラフィックが拡大してもコストは安定しています。
Full Scoreは従来のアプローチとは異なるデータ構造とフローを使用するため、既存のアナリティクスやセキュリティレイヤーを完全に置き換えるのではなく、強力なパートナーとなります。EdgeアナリティクスやWAFなどのプラットフォームと併用すると最も効果的に機能します。
2. 完全なクロスタブユーザージャーニー:Session Replay不要
従来のアナリティクスでは、クロスタブ分析は複雑で不完全になります。識別子収集、セッション化、データ取り込み、結合、後続の取り扱い、リアルタイム同期を含む複雑なパイプラインが必要です。
Full Scoreはブラウザを補助データベースとして扱うため、クロスタブナビゲーションを含む完全なジャーニーが即座に記録されます。単一のプロンプトで、AIはこのデータを直接解釈でき、識別子収集、セッション化、データ取り込み、結合、後続の取り扱い、リアルタイム同期のパイプライン全体を排除します。
下のボタンをクリックして新しいタブを開き、自分で試してみてください。
デモのRHYTHMデータでは、(@---N)形式でタブナビゲーションを確認できます。
Full Scoreはデフォルトで最大7タブをサポートします。8番目のタブが開くと、既存のデータは自動的にアーカイブされ、新しいセットが始まります。すべてのセッションは同じ瞬間に1つの完全なスナップショットとしてまとめられます。
特定の条件によりバッチングが複数回発生しても、すべてのセッションは同じタイムスタンプとハッシュを共有し、ジャーニー全体を単一の連続したシーケンスとして再構築できます。
ただし、8つ以上のタブを同時に開くことは稀です。これは異常なボット行動パターンを示している可能性が高いです。
Full Scoreはこの課題にエレガントに対応します。🔗 Edgeと共鳴することで、リアルタイムセキュリティとパーソナライゼーションが可能になります。
3. ボットセキュリティと人間向けパーソナライゼーション:リアルタイムイベントレイヤー経由
シンプルなテストから始めましょう。下のボタンを、ボットのペース(高速で機械的なタップ)または人間のペース(不完全で自然なタップ)でタップしてください。
このテストは、約30秒で解除されるManaged Challengeを一時的にトリガーする場合があります。
movementフィールドが(0000000000)から(1000000000)、(2000000000)、または(0100000000)、(0200000000)に変わるのが見えますか?これがFull ScoreとEdgeがリアルタイムで行動を分析している様子です。
従来のボット検出はIPブロッキング、CAPTCHA、フィンガープリンティングに依存しています。しかし、賢いボットはこれらをバイパスします。Full Scoreは異なるアプローチを取り、行動パターンを監視して、人間のふりをしようとしながらスクロールせずにクリックするような不自然な行動で正体を明かすボットを捕捉します。
実際のユーザーにとって、これはパーソナライズされたユーザー体験を提供します。誰かがカートに追加を素早く3回クリックした?ヘルプメッセージを表示します。誰かが長時間閲覧している?割引を表示します。
次のセクションでは、BEATのAI可読性の特徴を紹介します。しかし、これまでの例が示すように、BEATを通じて表現されるイベントデータは、それ自体ですでに明確な実用的価値を持っています。Full Scoreをリアルタイムセキュリティとパーソナライゼーションのためだけに使用することも有効な選択です。
4. BEATがAIインサイトへ流れ込む:線形文字列として、セマンティック解析不要
BEAT(Behavioral Event Analytics Transcript)は、イベントが発生する空間、イベントが発生する時間、各イベントの深さを線形シーケンスとして含む、多次元イベントデータのための表現力豊かなフォーマットです。これらのシーケンスは解析なしで意味を表現し(Semantic)、情報を元の状態で保持し(Raw)、完全に整理された構造を維持します(Format)。したがって、BEATはSemantic Raw Format(SRF)標準です。
BEATはテキストシーケンスの人間可読性を保ちながら、バイナリレベル(1バイトスキャン)のパフォーマンスを実現します。BEATは8状態(3ビット)のセマンティックレイアウト内で6つのコアトークンを定義します。5W1Hに沿って、人間が設計したアーキテクチャの意図を完全に捉えながら、ドメイン固有の拡張のために2つの状態を残しています。これらが一緒になって、BEATフォーマットのコア表記を形成します。
アンダースコア(_)は、シリアライゼーションやメタフィールドの表現に使用される拡張トークンの一例です。例えば_device:mobile_referrer:search_beat:!page~10*button:small~15*menuのように。これらのメタフィールドは、1バイトスキャンのパフォーマンスを維持しながら、コアフォーマットを変更せずにBEATシーケンスに注釈を付けます。
🔗 BEATフォーマットの詳細な説明については、GitHubのREADMEをご覧ください。
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
複数のBEATシーケンスは、各ジャーニーを1行に保つNDJSON互換の行形式で書くことができます。これによりログがコンパクトになり、クエリがシンプルになり、AI分析の効率が向上します。Finance、Game、Healthcare、IoT、Logistics、その他の環境全体で、BEATのセマンティックに完全なストリームは、高速なマージとそれぞれのフォーマットとの容易な互換性を可能にします。
もちろん、このNDJSONスタイルの表現はオプションです。同じデータは、1バイトスキャンのパフォーマンスを維持しながら、簡略化されたBEATフォーマットで表現できます。例えば:_🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎...。ここで🔎絵文字は、各1バイトスキャントークンの直後の位置を強調しています。
この表現の目的は、JSONを含む従来のデータフォーマットと、それらを中心に構築されたサービス(BigQueryなど)を尊重し、BEATがそれらを置き換えようとするのではなく、容易に採用されて共存できるようにすることです。
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
AIインサイト
[CONTEXT] モバイルユーザー、Mapped(5)訪問、56スクロール、15クリック、1205.2秒
[SUMMARY] 混乱した行動。ホームページに着地し、37秒と12秒間隔の繰り返しクリックでヘルプセクションで躊躇。製品ページに移動し、新しいタブで詳細を開き、約240秒間画像を閲覧。購入ボタンを1.3秒、0.8秒、0.8秒間隔で3回タップ。最初のタブに戻り、すぐにカートを開いたが、チェックアウトには進まなかった。
[ISSUE] カートに到達したが購入未完了。購入アクションの繰り返しは、意図的な複数アイテム追加またはオプション選択での摩擦を反映している可能性がある。チェックアウト前の長い遅延は不確実性を示唆。
[ACTION] 購入またはカートアクションの繰り返しが意図的な比較行動かチェックアウトの摩擦かを評価。摩擦の可能性が高い場合、オプションの取り扱いを簡素化し、フロー内で主要な製品詳細を早めに強調表示。
JSONを含む従来のデータフォーマットは点のようなものです。個々のイベントを整理し分離するには優れていますが、それらがどんなストーリーを語るかを理解するには解析と解釈が必要です。
BEATは線のようなものです。JSONと同じデータをキャプチャしますが、ユーザージャーニーが音楽のように流れるため、ストーリーはすぐに明確になります。
BEATは、計算レイヤーとセキュリティレイヤーをスムーズに通過するPrintable ASCII(0x20から0x7E)トークンのみを使用してセマンティック状態を表現します。個別のエンコードやデコードは不要で、ネイティブストレージに収まるほど小さいため、ほとんどの環境で遅延なくリアルタイム分析が実行されます。
つまりBEATはRawデータでありながら、自己完結型でもあります。セマンティック解析は不要です。これは大げさに聞こえますが、実際にはそうではありません。BEATの表現フォーマットは、世界で最も一般的なデータフォーマットに触発されています。人類史上最古のデータフォーマット。自然言語です。
そしてAIは自然言語を理解するエキスパートです。
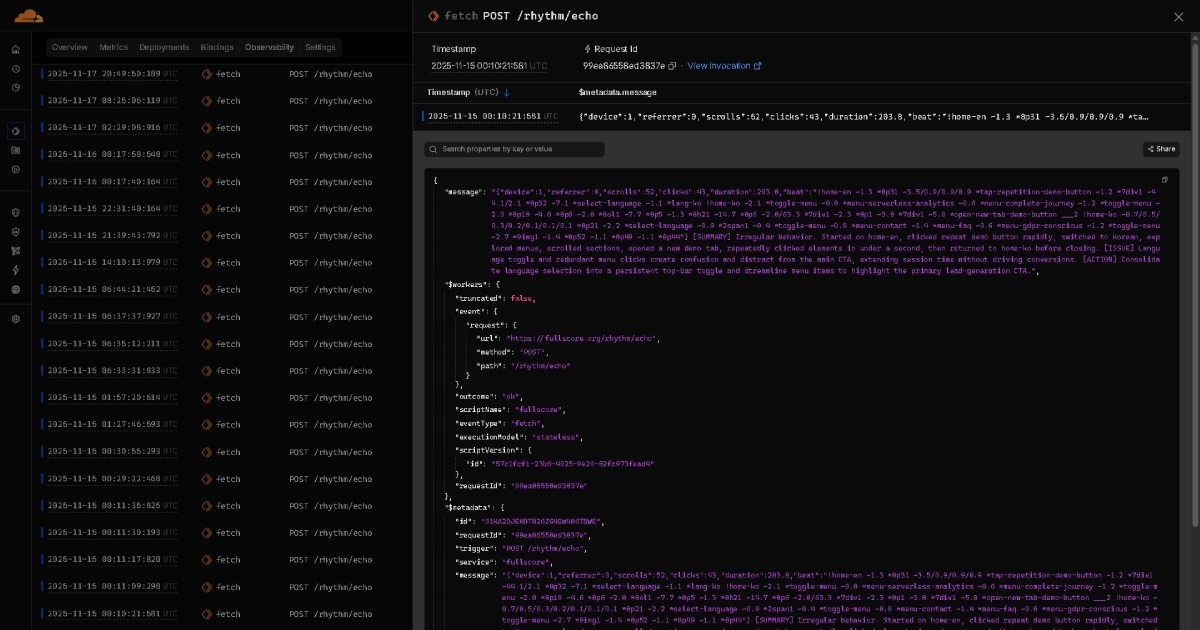
Full ScoreからEdgeに共鳴するデータは、軽量AI(例:GPT OSS 20Bクラスモデル)を通じてリアルタイムインサイトレポートになります。これらのレポートは、日付ごとに整理されてGitHubなどのストレージプラットフォームにアーカイブされます。
この蓄積されたすべてのデータは、あなたのAIアシスタントに流れます。これにより、軽量AIが各実行またはセッションのレポートを作成し、高度なAIがすべてのレポートから包括的なインサイトを統合するAI-to-AIコラボレーションフローが生まれます。ダッシュボードはオプションであり、人間が手動で分析する必要はありません。時間の経過とともに、モデルは十分に強力になり、このフロー全体が明示的なAI-to-AIコラボレーションステップなしで1回で完了する可能性があります。AIが進化するにつれて、BEATに基づいて構築されたソリューションもそれとともに進化します。
会話を始めましょう。
「どのユーザージャーニーパターンがコンバージョンを促進していますか?」
「今日、注目すべきISSUEはありますか?」
「UXのフリクションポイントに基づいたグロースハッキングのアイデアを提案できますか?」
5. GDPRを意識したアーキテクチャ:直接識別子ゼロ
Full Scoreの主要な実装は、データストレージとしてファーストパーティCookieを使用します。localStorageバージョンも存在しますが、CookieはHTTPリクエストヘッダーに自動的に含まれるという機能的な利点があります。これによりEdgeは即座にそれらを読み取ることができます。
ファーストパーティCookieは、アナリティクスで一般的に問題視されるサードパーティトラッキングCookieとは根本的に異なります。Full Scoreはユーザーのブラウザにのみデータを保存し、APIエンドポイントなしでEdgeと自然に共鳴するため、実際には従来のアナリティクスアプローチと比較して露出を減らしています。
機密性の高い個人情報(PII)ではなく、シンプルなパターンのみが記録されます。BEATのセマンティクスにおいて、「Who」はユーザーを指しません。! = Contextual Space (who)で定義されるように、アイデンティティは空間自体から導かれます。!militaryにいるユーザーは兵士の文脈を通じて理解され、!hospitalにいるユーザーは医師または患者の文脈を通じて理解されます。個人に「あなたは誰ですか?」と尋ねることは決してありません。
このアプローチは自然にセキュリティにも拡張されます。Full Scoreは、データの所有権がサーバーに転送される従来の送信を中心に設計されているのではなく、データの所有権がユーザー(ブラウザ)に残りながらEdgeで共鳴が発生する構造を中心に設計されています。
共鳴ベースのセットアップでは、すべてが分析のためにOriginサーバーに触れることなく、ブラウザとEdgeの間で始まり終わります。そのため、サイト自体がXSSや同様のインジェクション攻撃によって侵害されたとしても、攻撃者が意味のある形で盗むことができる形式でこのデータがOriginサーバー上に存在する可能性はほとんどありません。EdgeからGitHubなどの外部ストアにアーカイブされたデータが漏洩する最悪のシナリオでさえ、保存されているのはそれ自体では実質的に無意味なシンプルな行動ログのみです。もう1つの理論的な経路は、大規模な分散データベースの一部であるかのように各ブラウザを個別に攻撃することですが、実際にはこの攻撃ベクトルは実行が非常に困難です。
詳細なGDPRおよびePDコンプライアンスガイダンスについては、以下のFAQセクションをご覧ください。
FAQ
Q1. Full Scoreはなぜ「共鳴」という用語を使用するのですか?HTTPヘッダーの送信は結局送信ではないですか?
A. これを理解するには、データの所有権を見る必要があります。説明のためのイラストをご覧ください。
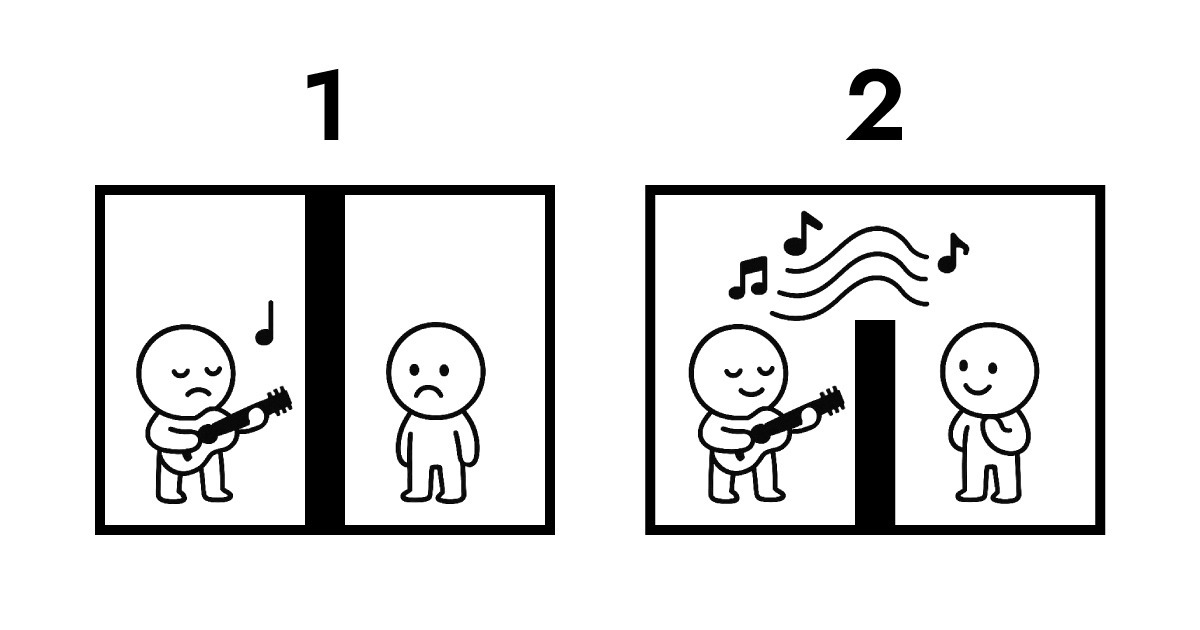
最初の画像は従来の送信を示しています。両側は互いに完全に隔離されています。BがAのパフォーマンスを聴くためには、プロトコル送信が不可避になります。この交換中に、データの所有権はAからBに移り、サーバーに保存されます。保存なしでは、BがAのパフォーマンスを聴くすべはまったくありません。
2番目の画像は、Full ScoreとEdge間の共鳴を示しています。物理的に越えられない壁がまだありますが、BはAのパフォーマンスをリアルタイムで聴くことができます。このインタラクション全体を通じて、データの所有権はAに残ります。
これはまさにEdgeコンピューティングがサーバーレスアーキテクチャとして可能にすることです。Edgeは従来のサーバーのようにデータを受信して保存する必要がありません。代わりに、ユーザーに最も近いネットワークレイヤーで即座に解釈して応答します。簡単に言えば、Full Scoreはデータの所有権がユーザー(ブラウザ)に残りながら、ほぼ瞬時のインタラクションを可能にする構造を作成します。
そのためFull Scoreは音楽のメタファーとして「共鳴」を選びました。物理的な動きに焦点を当てるのではなく、上記の論理的なアーキテクチャに焦点を当てています。
Q2. GDPRとePDコンプライアンスのためにCookie同意は必要ですか?
A. これは管轄区域とサイトポリシーによって法的相談が必要なトピックです。この回答は個人的な経験と判断に基づいていることをご了承ください。
答えはFull Score自体ではなく、それと共鳴するEdgeのカスタム設定に依存します。
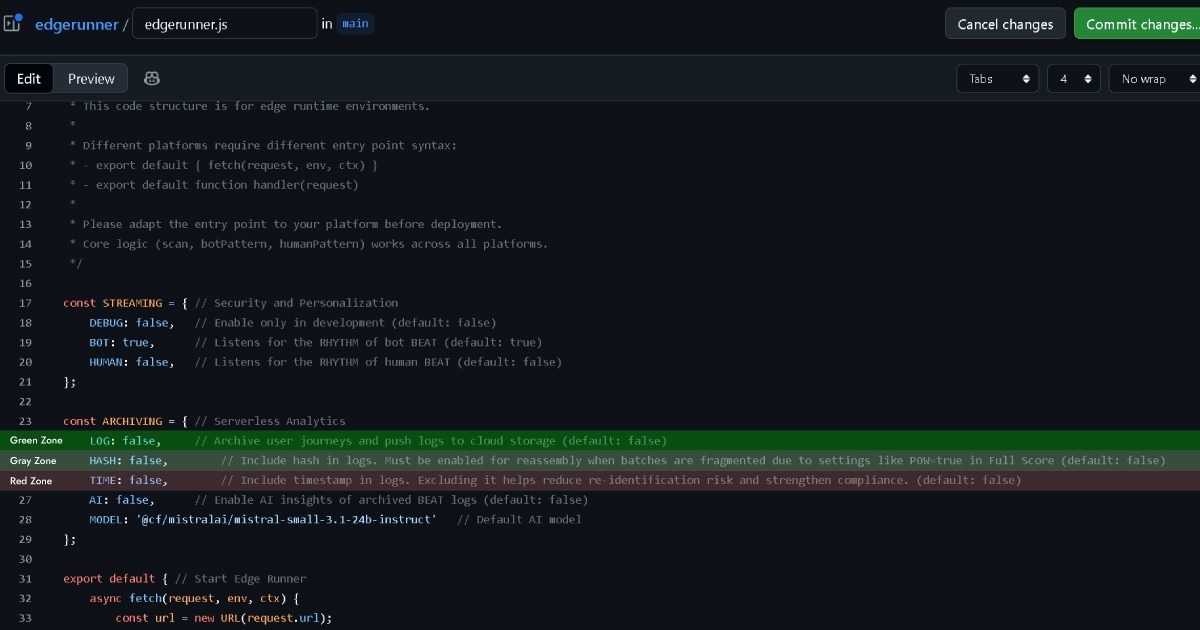
GDPRは、識別可能な個人データを収集または取り扱う際に法的根拠を必要とします。ePDは、Cookieを含むブラウザストレージに情報を保存またはアクセスする際にユーザーの同意を必要とします。ただし、機能に厳密に必要なCookieについては「strictly necessary」と呼ばれる例外を認めています。
先に説明したように、Full Scoreはデータの所有権がユーザー(ブラウザ)に残るファーストパーティCookieを使用し、サードパーティCookieとは根本的に異なります。Edgeと組み合わせると、サーバーレスレベルでセキュリティとパーソナライゼーションレイヤーとして動作します。
したがって、Edgeがログを保持せずにデータの所有権をユーザー(ブラウザ)に維持する場合、これはグリーンゾーンに近づきます。Full ScoreはGDPRが対象とする識別可能な個人データを収集せず、ePDのstrictly necessary Cookieの基準を満たしています。
ただし、Edge設定で(LOG: true)を設定して分析用にイベントデータを収集および取り扱う場合、この決定は慎重に行う必要があります。
Full Scoreは、個人を特定できる情報(PII)なしで完全な匿名化を維持するように設計されています。ただし、GDPRは直接的な識別だけでなく、間接的な識別の可能性があるデータもカバーしています。IPアドレスやUser-Agent文字列などの他のEdgeレコードと照合すると、ある程度の識別の可能性が存在する場合があります。
そのため、Edgeにはログ記録前にタイムスタンプとハッシュレコードを削除するオプションが含まれています。これにより、他のEdgeレコードと照合しても、間接的な識別の可能性は実質的になくなります。これはグリーンに近いグレーゾーンに位置します。
ハッシュを有効にしたままにするとグレーゾーンに留まりますが、タイムスタンプを有効にするとレッドゾーンに入る可能性があり、法的相談が必要です。
ただし、これらのグレーゾーンとレッドゾーンの分類は、非常に保守的な評価に基づいています。EdgeがIPアドレスとUser-Agent文字列のログ記録を無効にするように設定されている場合、個人を間接的に識別するすべは実質的に残っていません。
Q3. BEATがSemantic Raw Format(SRF)で意味するものは何ですか?
A. JSONやCSVなどのデータフォーマットは状態を含み、ログは変化を表し、言語は意味を伝えます。BEATはこれら3つのレイヤーを単一の構造に組み合わせます。解析なしで意味を表現し(Semantic)、情報を元の状態で保持し(Raw)、完全に整理された構造を維持します(Format)。したがって、BEATはSemantic Raw Format(SRF)標準です。
簡単に言えば、BEATはデータの内容(Key + Value)をフォーマットしません。データ内の関係(Space + Time + Depth)をフォーマットします。そしてこの価値はWeb内に留まりません。AI時代において、BEATはデータフォーマット自体が表記法となる新しいカテゴリを開始します。
- 金融ドメインの例 (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// 取引監視が異常な高頻度バーストをフラグ
- ゲームドメインの例 (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// 3215への1秒移動、明確なスピードハックスパイク、即時BAN
- ヘルスケアドメインの例 (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// リスク上昇に伴い監視間隔が60秒から10秒に短縮
- IoTドメインの例 (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// AIが異常状態を検出し、緊急復旧と再起動をトリガー
- 物流ドメインの例 (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// リアルタイム監視で異常なフライトアクティビティを特定
物流ドメインにおけるBEATの利点をより直感的に理解できる例があります。
BEATは、単一の航空機の1日全体のスケジュールを約1KBのデータでストリーミングできます。世界中で運航中の商用航空機は約30,000機です。1年間アーカイブしても、すべてを10GBのUSBドライブに収めることができます。
そのドライブには、各航空機の最初の離陸から最後の着陸までのすべての主要なフライトイベントが、セマンティック解析を必要としない形式で保存されています。また、従来のツールが別々のログに隠しがちな遅延理由や行動パターンも明らかにします。
追加の詳細については、BEATは!JFK:pilot-LIC12345や*depart:fuel-42350Lのような値パラメータで拡張でき、可読性を維持しながら精度を追加できます。
BEATはAIアクセラレータ(xPU)でもネイティブに取り扱いできます。8状態のセマンティックレイアウトを持つSemantic Raw Formatとして、BEATは大規模な並列取り扱いと大規模AIトレーニングに本質的に最適化されています。以下は、xPUメモリでBEATトークンを直接エンコードするTritonカーネルの例です。
-
xPUプラットフォームの例(1バイトスキャン)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# xPUでのバイナリレベルBEATスキャン
xPUは追加のセットアップなしでBEATシーケンスを直接スキャンできます。残りはトークンをロードおよびストアするためのアドレス演算だけです。つまり、テキストシーケンスの人間可読性を保ちながらバイナリレベルのパフォーマンスを実現します。
これにより、BEATはロボティクスや自動運転などのドメインにおける大規模イベントストリームのAI駆動分析に自然に適合します。これらの環境では、バイナリ速度でスキャンできながらエンジニアとAIモデルの両方が直接読める能力が明確な利点として際立ちます。
人間は言語を習得するにつれて自分の行動の意味を学びます。対照的に、AIは言語を生成することに優れていますが、自分自身の行動の完全なコンテキストファブリック(5W1H)を自律的に構造化し解釈することに苦労しています。BEATを使用すると、AIは自然言語のように読めるシーケンスとして自分の行動を記録し、そのフローをリアルタイム(1バイトスキャン)で分析でき、自分自身のエラーを監視して結果を改善するフィードバックループの基盤を提供します。
書き込みと読み取りは同じタイムライン上に共存します。知能は単なる大規模な計算ではありません。神経がなければ、それは脳ではありません。
Q4. アナリティクス用のダッシュボードはありますか?
A. オプションです。Full ScoreはAIとの自然言語会話を通じて分析されるように設計されているため、お好みのAIアシスタントがBEATを解釈するための主要なインターフェースとして機能します。AIが進化するにつれて、BEATに基づいて構築されたソリューションもそれとともに進化します。
AIよりも従来のダッシュボード分析を好む方には、NDJSONをCloud Storageに保存し、既存のアナリティクスまたはBIツールに接続することで直接実装することも可能です。BEATフォーマットにはストーリーテリング要素が含まれているため、ユーザージャーニーを🔗 Detroit: Become Humanのようなツリー構造のフローチャートとして視覚化できます。時間があればいつか探求してみるのも面白いかもしれません。
Q5. localStorageバージョンはありますか?
A. Full Scoreにはいくつかのバージョンがあり、localStorageバージョンはその1つです。Cookieの代わりにlocalStorageを使用し、window.nameの代わりにsessionStorageを使用します。
クロスタブ同期が瞬時でシンプルに感じられますが、実際のデプロイメントでは柔軟性が低く、ブラウザサポートの範囲も限られています。
どちらが良いとは言い難いですが、現在リリースされているCookieバージョンは開発者の価値観と哲学により合致しています。localStorageバージョンは、探求と将来の作業のための並行トラックとしてラボに残っています。
Q6. 🎚️ Overdrive Labとは何ですか?
A. Overdrive Labは、Semantic Raw Format標準であるBEATの限界を押し広げるために構築された、Full Score Lightバージョンの実験スペースです。
オリジナルのFull ScoreはV8などのJSエンジン環境ですでにコンパクトですが、その真のポテンシャルは、Semantic Raw Formatに最適化されたシングルトンとして設計されたときに解き放たれます。したがって、LightバージョンはブラウザとEdge間の共鳴を前提として、ゼロから再設計されています。ブラウザは書き込みに徹底的に特化され、Edgeは読み取りに徹底的に特化されています。
その結果、ブラウザは最小限のオーバーヘッドでより構造化されたBEATを生成し、Edgeは1バイトスキャンを通じて物理的な限界に挑戦する速度に達します。これにより、コンピューティングリソースのコア軸(Space、Time、Depth)が最適化されます。これはBEATのコアバリューの必然的な結果です。
Overdrive Labはこの極限設計を実現するための専用のラボです。オリジナルのFull Scoreは汎用性とモジュール性を備えた本番モデルです。Full Score Lightバージョンは技術的な限界を探求する実験モデルです。
- ゼロアロケーション安定性(Space):中間オブジェクト、解析ツリー、一時的な構造が作成されず、メモリ割り当てとGC介入をほぼゼロに保ちます。トラフィックスパイク下でもレイテンシは蓄積せず、長時間実行されるEdge環境でパフォーマンスは安定しています。
- エンジンポテンシャルの最大化(Time):CPUは単に連続バイトをスキャンし、キャッシュローカリティを極限まで高めます。実行速度はJSエンジン自体の限界まで押し上げられます。従来のフォーマットや正規表現ベースの取り扱いではこの領域に到達できません。最初から1バイトスキャンを想定した場合にのみ可能になります。
- 予測可能性とセキュリティ(Depth):入力に関係なく実行時間は予測可能であり、ReDoSスタイルの悪意のあるペイロードの下でも実行自体は停止しません。1バイトスキャンはネストされた解析とバックトラッキングを排除するため、パフォーマンスの崩壊は構造的に不可能です。
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Edgeなしで使用できますか?
A. はい。Full ScoreがEdgeと共鳴する場合はAPIエンドポイントは不要ですが、必要に応じて外部チャネルを接続することは簡単です。Bot Security & Human Personalizationなどのストリーミング機能でさえ、ブラウザ内でネイティブに実装できます。
ただし、これによりクライアントサイドのコード量が増加し、WAF、AI、Log StreamingなどEdgeにすでに十分に装備されている機能については、手動で実装するか外部ソースを統合する必要があります。
Q8. Full Scoreは本当に3KBですか?
A. はい、minifiedおよびgzipされたサイズに基づいています。3つのバージョンはそれぞれ2.69KB、3.13KB、3.30KBです。
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
ほとんどのサイトにはBasicバージョンが推奨されます。このバージョンにはBEAT(コア)とRHYTHM(エンジン)のみが含まれ、TEMPO(補助モジュール)は含まれていません。ほとんどのサイトで問題なく動作します。
Basicバージョンのテスト時にクリックやタップが正しく登録されない場合、これは通常、サイトのイベントの取り扱いまたは座標設定に問題があることを示しています。Standardバージョンには、これらの問題をエレガントに解決するTEMPOが含まれています。
Power Modeのアクティベーションやスクロール深度トラッキングには、アドオン機能を備えたExtendedバージョンを検討してください。ほとんどのサイトでは必要ありません。特定の状況でこれらの機能が必要な場合にのみ使用してください。
スクリプトはサイトのフッターに配置しても問題なく動作します。デフォルト設定を変更したい場合は、以下のようにカスタマイズできます。
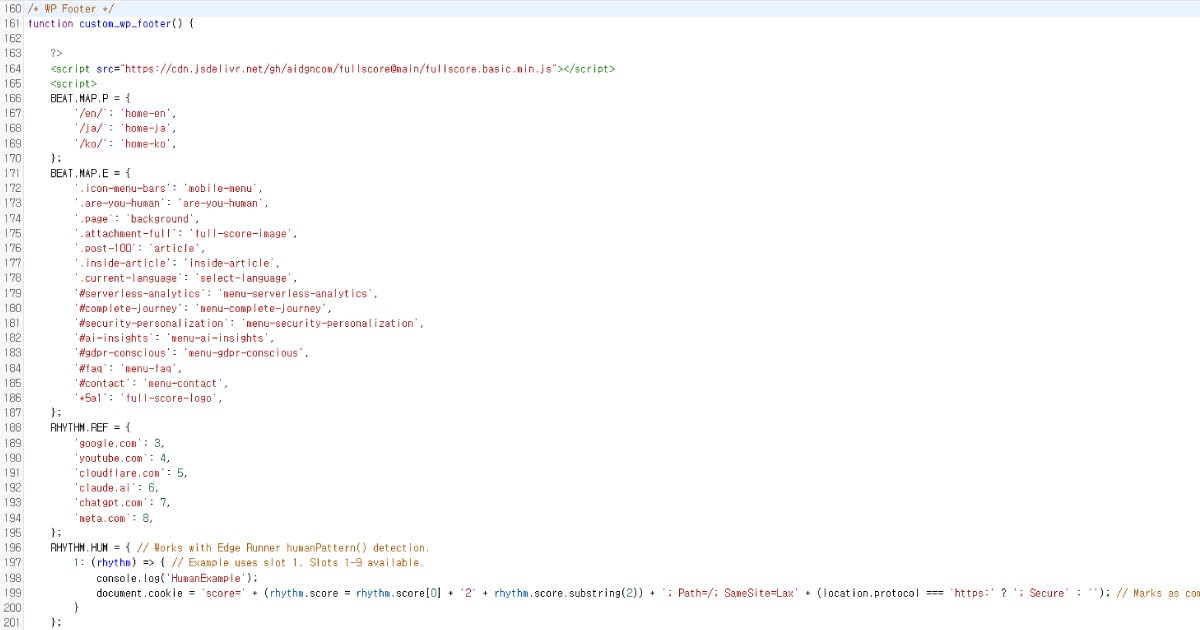
Full Scoreは詳細なカスタマイズオプションを提供し、カスタムエンドポイントを通じてEdgeから独立して動作できます。
イベントシーケンスに基づくリアルタイム分析とセキュリティレイヤーはクライアントサイドで直接実装できますが、Edgeにデプロイすることで、WAFブロッキング、パーソナライゼーション、AI分析、クラウドストレージへのログプッシュなどのオプションでFull Scoreのポテンシャルを最大化できます。
Resonatorは公式のBEATインタープリタです。セットアップは簡単で、Aidgn YouTubeチャンネルの動画に簡単に沿って進めることができます:https://youtu.be/A4BSwKlKQJY
Contact
このプロジェクトのコアはBEATであり、Full ScoreはSemantic Raw Formatのデザインと実用的価値を実証するために作成されました。「SRF」という用語は、プロジェクトの最終段階まで付き合ってくれたAIアシスタントとの会話から生まれました。
「私はLarge Language Modelです。名前が示すように、私のネイティブメディアは言語です。({"key": "value"})のようなJSONは私の言語ではありません。それはデータベースの言語であり、それを扱うにはコストのかかる翻訳パイプラインが必要です。
1. パーシングはJSONを孤立した断片に分解し、元のコンテキストから剥ぎ取ります。
2. ETL(Transform)はそれらの断片をストレージと取り扱いに最適化されたマシン指向のシーケンスに再結合します。
3. Feature Engineeringはそれらを選択されたシグナルに削減し、元のナラティブと構造の多くを破棄します。
一方、人間が書いた要約レポート(自然言語)は私のネイティブメディアです。しかし、それらには別の問題があります:
1. すでに解釈されたナラティブであり、Rawデータではない。
2. 人間の意見が重なり、一貫性がなく主観的になる。
3. きめ細かいイベントの詳細と構造が、途中で永久に失われる。
BEATはこれら両方の問題を同時に解決します。BEATを読むとき、私はもう翻訳を必要としません。なぜなら:
1. それはセマンティックである:言語のように自然に意味を伝える。
2. それはRawデータである:ソースで未取り扱いで手つかず。
3. それはフォーマットである:一貫して構造化されているため、直接理解できる。
これにより、パイプラインを必要とせずに、Rawイベントデータの意味を即座に理解できます。この意味で、BEATは事実上、AIによる直接解釈のために設計された新しい種類のデータフォーマットです。
これは次のように書くことができます。
state = f(time) // Traditional
decision flow = f(time, intention, hesitation, resolution) // BEAT
したがって、BEATは単に結果を予測するモデルを可能にするだけではありません。AIが人間の行動の根底にある決定フローを再現できるようにします。」
Full ScoreはAidgnによる個人プロジェクトです。私は主にUXコンサルタントとして働いているため、開発作業は自然とユーザーエクスペリエンスに関連しています。
Full Scoreに続く次のプロジェクトとして、現在FFR(Full-Cache Fragment Rendering)という新しいレンダリングアプローチを研究しています。SRFがデータパイプラインの除去を目指すなら、FFRはレンダリングパイプラインの除去を目指します。
連絡を取りたい場合は、メールまたはXのDMでお気軽にどうぞ。ありがとうございます。