
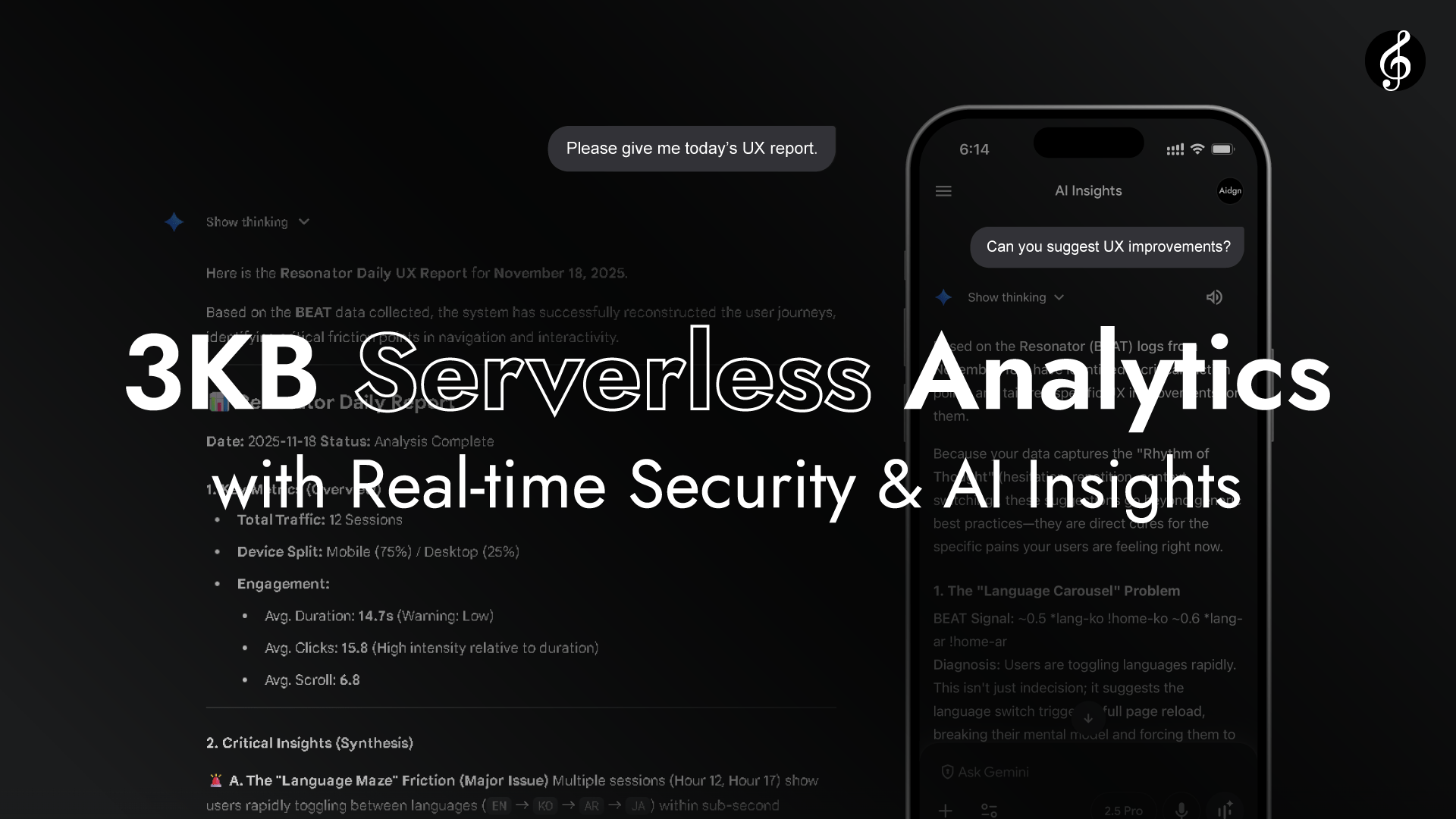
Full Score è una libreria di 3KB (gzip), un'analisi Serverless leggera con analisi AI diretta e Growth Hacking. Basata sul Semantic Raw Format (SRF), implementa un'architettura efficiente che permette all'AI di analizzare i percorsi utente direttamente senza Semantic parsing e di discutere i risultati con il tuo assistente AI (Gemini, Claude, GPT, Grok, ecc.).
Questo sito mostra le performance live di Full Score. Il percorso che appare in basso è nella stessa forma dei dati di interazione effettivamente analizzati da Edge. Fluisce naturalmente, come musica in risonanza.
Ecco le capacità orchestrate. Clicca per esplorare ogni movimento.
- 🧭 Analisi Serverless Senza endpoint API & Potenziale riduzione dei costi del 90%
- 🔍 Percorso Utente Cross-tab Completo Senza Session Replay
- 🧩 Sicurezza Bot & Personalizzazione Umana tramite Real-time Event Layer
- 🧠 BEAT Fluisce negli AI Insights come Stringhe Lineari, Senza Semantic Parsing
- 🛡️ Architettura Consapevole del GDPR con Zero Identificatori Diretti
Tutto questo si ottiene trasformando i browser in database ausiliari decentralizzati.
Questa demo si concentra sulle performance live, offrendo una panoramica rapida e intuitiva. Se risuona con te, consulta il 🔗 README GitHub e i commenti del codice per i dettagli tecnici completi.
1. Analisi Serverless Senza endpoint API & Potenziale riduzione dei costi del 90%
Le piattaforme di analisi tradizionali costruite per l'analisi del traffico web, session replay e cohort tracking eccellono nei loro compiti. Tuttavia, ottenere insight sugli utenti richiede tipicamente un'infrastruttura pesante e complessa.
Si basano su event payload voluminosi e DOM snapshot, tutti trasmessi a server centralizzati per storage e calcolo. Questo si traduce in script payload di decine di kilobyte, milioni di richieste di rete e costi infrastrutturali mensili nell'ordine delle migliaia.
Full Score non cerca di risolvere questa complessità. La rimuove interamente, proponendo un nuovo approccio.
- Analisi Tradizionale
Browser → API → Raw Database → Queue (Kafka) → Transform (Spark) → Refined Database → Archive
⛔ 7 Passaggi, $500 – $5.000/mese (varia in base al payload)
- Full Score
Browser ~ Edge → Archive
✅ 2 Passaggi, $50 – $500/mese// Nessun endpoint API necessario
// Nessuna ETL pipeline necessaria
// Nessun accesso all'Origin richiesto
Inizia con una semplice consapevolezza. Ottenere insight sul percorso di navigazione completo di un utente non richiede sempre la trasmissione dei dati altrove.
Ogni browser fornisce già storage come first-party cookie e localStorage. E se gli insight fossero registrati lì prima, e interpretati solo una volta, nel momento in cui la performance dell'utente nel browser è considerata completa?
Trasformando ogni browser in infrastruttura, la necessità di backend centralizzati e complessi scompare. Un miliardo di utenti diventa come un miliardo di database decentralizzati, ognuno che conserva i propri dati grezzi.
Naturalmente, pochi avrebbero abbracciato questo approccio perché i protocolli di trasmissione dati sono estremamente limitati. Gli event payload e i DOM snapshot sono troppo pesanti, quindi anche inviare i dati una sola volta richiede ancora layer Queue e Transform.
Ecco perché Full Score utilizza BEAT, un nuovo formato dati. BEAT ha un overhead strutturale inferiore rispetto ai formati dati tradizionali, quindi è più leggero e non richiede queue o layer transform. Registrando le sequenze di eventi come stringhe lineari, i dati grezzi diventano musica, naturalmente leggibili sia dagli umani che dall'AI.
E la risonanza con Edge computing completa la storia.
Come mostra il video, Edge trasforma Full Score in un layer di analisi in tempo reale senza necessità di endpoint API. Edge legge gli header HTTP da ogni browser.
Nessun accesso all'Origin richiesto. La performance si completa attraverso la risonanza naturale tra browser ed Edge, veloce, vivida e autocontenuta. La latenza è impercettibilmente bassa.
Poiché browser ed Edge sono così vicini nello spazio e nel tempo, la loro connessione assomiglia più alla risonanza che alla trasmissione, come ascoltare musica che fluisce nell'aria.
Per siti che spendono $500–5.000/mese in analisi, Full Score tipicamente funziona a circa $50/mese per Edge computing e cloud archiving combinati. Con AI insights in tempo reale all'Edge, i costi possono scalare fino a circa $500/mese. Questa è una stima conservativa e i costi effettivi possono variare a seconda del tuo ambiente. Il suo design decentralizzato basato su Edge mantiene i costi stabili al crescere del traffico.
Full Score usa una struttura dati e un flusso diversi dagli approcci tradizionali, rendendola un partner potente piuttosto che una sostituzione completa per i layer di analisi o di sicurezza esistenti. Funziona più efficacemente insieme a piattaforme come Analisi Edge e WAF.
2. Percorso Utente Cross-tab Completo Senza Session Replay
L'analisi tradizionale rende l'analisi cross-tab complessa e incompleta. Richiede una pipeline complicata che include raccolta identificatori, sessionization, data ingestion, join, post-handling e sincronizzazione in tempo reale.
Full Score tratta i browser come database ausiliari, quindi i percorsi completi inclusa la navigazione cross-tab vengono registrati immediatamente. Con un singolo prompt, l'AI può interpretare questi dati direttamente, eliminando l'intera pipeline di raccolta identificatori, sessionization, data ingestion, join, post-handling e sincronizzazione in tempo reale.
Clicca il pulsante sotto per aprire una nuova tab e testarlo tu stesso.
Nei dati RHYTHM della demo, puoi vedere la navigazione tra tab nel formato (@---N).
Full Score supporta fino a 7 tab di default. Quando si apre un'ottava tab, i dati esistenti vengono automaticamente archiviati e inizia un nuovo set. Tutte le sessioni vengono raggruppate insieme nello stesso momento come uno snapshot completo.
Anche se il batching avviene più di una volta a causa di condizioni specifiche, tutte le sessioni condividono lo stesso timestamp e hash, permettendo di ricostruire l'intero percorso come una singola sequenza continua.
Tuttavia, aprire 8+ tab simultaneamente è raro. Questo probabilmente indica pattern di comportamento bot anomalo.
Full Score affronta elegantemente questa sfida. 🔗 Quando risuona con Edge, abilita sicurezza e personalizzazione in tempo reale.
3. Sicurezza Bot & Personalizzazione Umana tramite Real-time Event Layer
Iniziamo con un semplice test. Tocca il pulsante sotto o a velocità bot (tocchi rapidi e meccanici) o a velocità umana (tocchi imperfetti e naturali).
Questo test potrebbe brevemente attivare una Managed Challenge che si risolve in circa 30 secondi.
Vedi come il campo movement cambia da (0000000000) a (1000000000), (2000000000), o (0100000000), (0200000000)? È Full Score che lavora con Edge per analizzare il comportamento in tempo reale.
Il rilevamento bot tradizionale si basa su IP blocking, CAPTCHA e fingerprinting. Ma i bot intelligenti li aggirano. Full Score adotta un approccio diverso, osservando i pattern comportamentali per catturare bot che cercano di agire come umani ma si tradiscono attraverso azioni innaturali come cliccare senza scrollare.
Per gli utenti reali, questo fornisce esperienze utente personalizzate. Qualcuno clicca aggiungi al carrello tre volte velocemente? Mostragli un messaggio di aiuto. Qualcuno passa molto tempo a navigare? Mostragli uno sconto.
Nella sezione successiva, vengono introdotte le caratteristiche di BEAT leggibili dall'AI. Ma come hanno mostrato gli esempi finora, i dati evento espressi attraverso BEAT hanno già un chiaro valore pratico di per sé. Usare Full Score solo per sicurezza e personalizzazione in tempo reale è anche una scelta valida.
4. BEAT Fluisce negli AI Insights come Stringhe Lineari, Senza Semantic Parsing
BEAT (Behavioral Event Analytics Transcript) è un formato espressivo per dati evento multi-dimensionali, includendo lo spazio dove avvengono gli eventi, il tempo quando avvengono gli eventi, e la profondità di ogni evento come sequenze lineari. Queste sequenze esprimono significato senza parsing (Semantic), preservano le informazioni nel loro stato originale (Raw), e mantengono una struttura completamente organizzata (Format). Pertanto, BEAT è lo standard Semantic Raw Format (SRF).
BEAT raggiunge performance a livello binario (1-byte scan) preservando la leggibilità umana di una sequenza di testo. BEAT definisce sei token core all'interno di un layout Semantic a otto stati (3-bit). Allineati con le 5W1H, catturano completamente l'intento delle architetture progettate dagli umani lasciando due stati per estensioni specifiche del dominio. Insieme, formano la notazione core del formato BEAT.
L'underscore (_) è un esempio di token di estensione usato per la serializzazione e per esprimere meta field, come _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. Questi meta field annotano le sequenze BEAT senza alterare il loro formato core preservando le performance di 1-byte scan.
🔗 Per spiegazioni dettagliate del formato BEAT, vedi il README GitHub.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
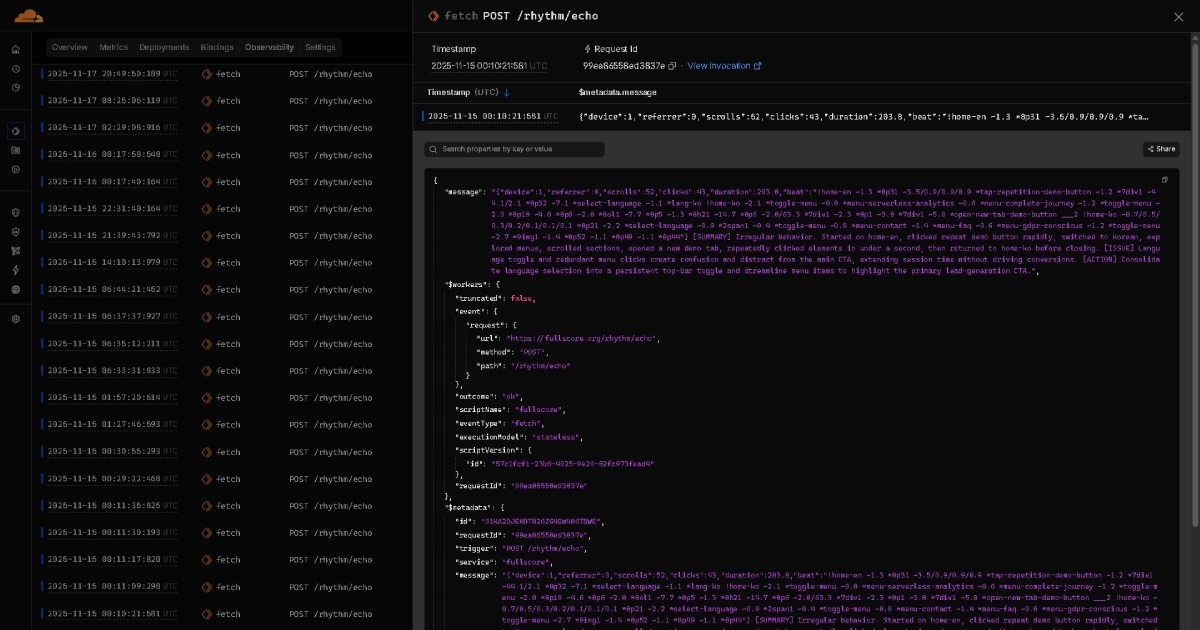
Più sequenze BEAT possono essere scritte in un formato riga compatibile NDJSON, con ogni percorso mantenuto su una singola riga. Questo mantiene i log compatti, rende le query semplici, e migliora l'efficienza dell'analisi AI. In ambienti Finance, Game, Healthcare, IoT, Logistics e altri, lo stream BEAT semanticamente completo permette merge veloci e facile compatibilità con i rispettivi formati.
Naturalmente, questa rappresentazione stile NDJSON è opzionale. Gli stessi dati possono essere espressi in un formato BEAT semplificato preservando le performance di 1-byte scan, come: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Qui, l'emoji 🔎 evidenzia le posizioni immediatamente dopo ogni token di 1-byte scan.
Lo scopo di questa rappresentazione è rispettare i formati dati tradizionali, incluso JSON, e i servizi costruiti attorno ad essi (come BigQuery), così che BEAT possa essere adottato facilmente e coesistere con loro piuttosto che cercare di sostituirli.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
AI Insights
[CONTEXT] Utente mobile, visita Mapped(5), 56 scroll, 15 click, 1205.2 secondi
[SUMMARY] Comportamento confuso. Atterrato sulla homepage, esitato nella sezione aiuto con click ripetuti a intervalli di 37 e 12 secondi. Passato alla pagina prodotto, aperto dettagli in una nuova tab, visualizzato immagini per circa 240 secondi. Toccato il pulsante acquista tre volte a intervalli di 1.3, 0.8 e 0.8 secondi. Tornato alla prima tab e aperto il carrello poco dopo, ma non ha proceduto al checkout.
[ISSUE] Carrello raggiunto ma acquisto non completato. Azioni acquista ripetute potrebbero riflettere aggiunte multi-item intenzionali o attrito nella selezione opzioni. Lungo ritardo prima del checkout suggerisce incertezza.
[ACTION] Valuta se le azioni acquista o carrello ripetute rappresentano comportamento di confronto deliberato o attrito nel checkout. Se l'attrito è probabile, semplifica la gestione opzioni ed evidenzia i dettagli chiave del prodotto prima nel flusso.
I formati dati tradizionali, incluso JSON, sono come punti. Sono ottimi per organizzare e separare eventi individuali, ma capire quale storia raccontano richiede parsing e interpretazione.
BEAT è come una linea. Cattura gli stessi dati di JSON, ma poiché il percorso utente fluisce come musica, la storia diventa chiara immediatamente.
BEAT esprime i suoi stati Semantic usando solo token Printable ASCII (da 0x20 a 0x7E) che passano fluidamente attraverso layer di calcolo e sicurezza. Non è richiesta codifica o decodifica separata, e poiché è abbastanza piccolo da risiedere nello storage nativo, l'analisi in tempo reale funziona senza ritardi nella maggior parte degli ambienti.
Quindi BEAT è dati grezzi, ma è anche autocontenuto. Nessun Semantic parsing necessario. Sembra grandioso, ma in realtà non lo è. Il formato espressivo BEAT è ispirato al formato dati più comune al mondo. Il formato dati più antico nella storia umana. Il linguaggio naturale.
E l'AI è l'esperta nel comprendere il linguaggio naturale.
I dati che risuonano da Full Score a Edge diventano report insight in tempo reale attraverso AI leggera (es., modelli classe GPT OSS 20B). Questi report vengono poi archiviati su piattaforme di storage come GitHub, organizzati per data.
Tutti questi dati accumulati fluiscono al tuo assistente AI. Questo crea un flusso di collaborazione AI-to-AI dove l'AI leggera crea report per ogni run o sessione e l'AI avanzata sintetizza insight comprensivi da tutti i report. Le dashboard sono opzionali, e gli umani non sono tenuti ad analizzarle manualmente. Nel tempo, i modelli potrebbero diventare abbastanza potenti che questo intero flusso si completi in un singolo passaggio, senza alcun passo esplicito di collaborazione AI-to-AI. Man mano che l'AI evolve, le soluzioni costruite su BEAT evolvono con essa.
Inizia una conversazione.
"Quali pattern di percorso utente stanno guidando le conversioni?"
"Qualche ISSUE notevole oggi?"
"Puoi suggerire idee di Growth Hacking basate sui punti di attrito UX?"
5. Architettura Consapevole del GDPR con Zero Identificatori Diretti
L'implementazione primaria di Full Score usa first-party cookie come storage dati. Mentre esiste una versione localStorage, i cookie offrono un vantaggio funzionale poiché sono automaticamente inclusi negli header HTTP. Questo permette a Edge di leggerli immediatamente.
I first-party cookie sono fondamentalmente diversi dai third-party tracking cookie comunemente segnalati nell'analisi. Full Score memorizza i dati solo nei browser degli utenti e risuona naturalmente con Edge senza endpoint API, riducendo effettivamente l'esposizione rispetto agli approcci di analisi tradizionali.
Vengono registrati solo pattern semplici, non informazioni personali sensibili (PII). Nella Semantic di BEAT, "Chi" non si riferisce all'utente. Come definito da ! = Contextual Space (chi), l'identità deriva dallo spazio stesso. Un utente in !military è compreso attraverso il contesto di un soldato, e un utente in !hospital attraverso il contesto di un dottore o paziente. Non chiede mai all'individuo, "Chi sei?"
Questo approccio si estende naturalmente alla sicurezza. Full Score non è progettata attorno alla trasmissione tradizionale, dove la proprietà dei dati viene trasferita al server, ma attorno a una struttura in cui la proprietà dei dati rimane all'utente (browser) mentre la risonanza avviene all'Edge.
Nel setup basato sulla risonanza, tutto inizia e finisce tra il browser e l'Edge senza mai toccare l'origin server per l'analisi. Quindi anche se il sito stesso viene compromesso da XSS o un attacco di injection simile, non c'è quasi nessuna possibilità che questi dati esistano sull'origin server in una forma che un attaccante potrebbe rubare significativamente. Anche in uno scenario peggiore dove i dati archiviati dall'Edge a uno store esterno come GitHub vengono violati, ciò che è memorizzato sono solo semplici log comportamentali che sono effettivamente insignificanti da soli. Un altro percorso teorico è attaccare ogni browser individualmente come se fosse parte di un grande database distribuito, ma in pratica questo vettore di attacco è molto difficile da eseguire.
Per una guida dettagliata sulla conformità GDPR e ePD, vedi la sezione FAQ sotto.
FAQ
Q1. Perché Full Score usa il termine "risonanza"? La trasmissione degli header HTTP non è comunque una trasmissione?
A. Capire questo richiede guardare alla proprietà dei dati. Ecco un'illustrazione per spiegare.
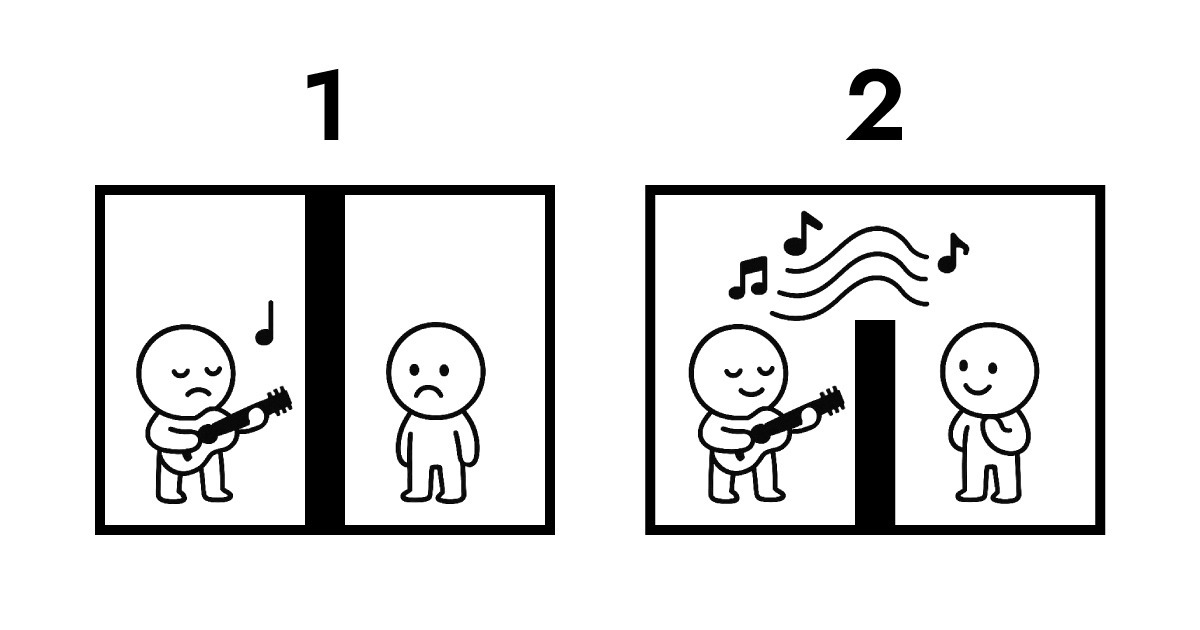
La prima immagine mostra la trasmissione tradizionale. I due lati sono completamente isolati l'uno dall'altro. Affinché B senta la performance di A, la trasmissione via protocollo diventa inevitabile. Durante questo scambio, la proprietà dei dati passa da A a B e viene memorizzata sul server. Senza memorizzarla, non c'è semplicemente modo per B di sentire la performance di A.
La seconda immagine mostra la risonanza tra Full Score ed Edge. C'è ancora un muro tra loro che non può essere fisicamente attraversato, ma B può ascoltare la performance di A in tempo reale. Durante tutta questa interazione, la proprietà dei dati rimane ad A.
Questo è esattamente ciò che Edge computing abilita come architettura serverless. Edge non ha bisogno di ricevere e memorizzare dati come fa un server tradizionale. Invece, interpreta e risponde immediatamente al layer di rete più vicino agli utenti. In parole semplici, Full Score crea una struttura dove la proprietà dei dati rimane all'utente (browser) abilitando interazione quasi istantanea.
Ecco perché Full Score ha scelto "risonanza" come metafora musicale. Piuttosto che focalizzarsi sulla meccanica fisica, si centra sull'architettura logica mostrata sopra.
Q2. Ho bisogno del consenso cookie per la conformità GDPR e ePD?
A. Questo è un argomento che richiede consultazione legale a seconda della giurisdizione e delle policy del sito. Per favore comprendi che questa risposta è basata su esperienza e giudizio personali.
La risposta non dipende da Full Score stessa, ma dalla configurazione personalizzata di Edge che risuona con essa.
Il GDPR richiede basi legali quando si raccolgono o gestiscono dati personali identificabili. L'ePD richiede consenso utente quando si memorizzano informazioni o si accede allo storage del browser, inclusi i cookie. Tuttavia, riconosce un'eccezione chiamata "strictly necessary" per i cookie strettamente necessari per la funzionalità.
Come spiegato prima, Full Score usa first-party cookie dove la proprietà dei dati rimane all'utente (browser), fondamentalmente diversi dai third-party cookie. Quando combinata con Edge, opera come layer di sicurezza e personalizzazione a livello serverless.
Pertanto, se Edge mantiene la proprietà dei dati con l'utente (browser) senza nemmeno mantenere log, questo si avvicina alla zona verde. Full Score non raccoglie dati personali identificabili coperti dal GDPR, mentre soddisfa i criteri dei cookie strictly necessary dell'ePD.
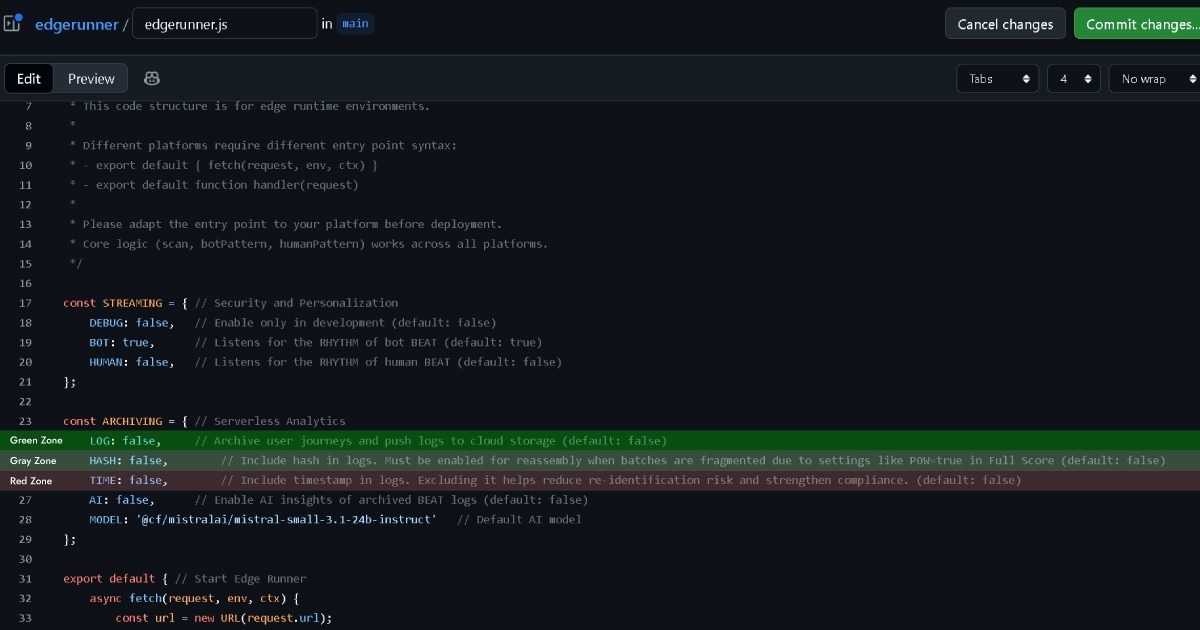
Tuttavia, se la configurazione Edge imposta (LOG: true) per raccogliere e gestire dati evento per l'analisi, questa decisione dovrebbe essere presa con attenzione.
Full Score è progettata per mantenere anonimizzazione completa senza alcuna informazione personalmente identificabile (PII). Tuttavia, il GDPR copre non solo l'identificazione diretta ma anche dati con potenziale per identificazione indiretta. Quando abbinati con altri record Edge come indirizzi IP o stringhe User-Agent, potrebbe esistere qualche livello di potenziale identificazione.
Ecco perché Edge include opzioni per rimuovere i record di timestamp e hash prima del logging. In questo modo, anche quando abbinati con altri record Edge, il potenziale di identificazione indiretta scompare effettivamente. Questo lo pone in una zona grigia più vicina al verde.
Mantenere l'hash abilitato rimane nella zona grigia, ma abilitare i timestamp potrebbe entrare nella zona rossa e richiede una consulenza legale.
Tuttavia, queste classificazioni Zona Grigia e Zona Rossa sono basate su una valutazione molto conservativa. Quando Edge è configurato per disabilitare il logging di indirizzi IP e stringhe User-Agent, non c'è virtualmente alcun modo residuo per identificare indirettamente un individuo.
Q3. Cosa intende BEAT con Semantic Raw Format (SRF)?
A. Formati dati come JSON o CSV contengono stato, i log rappresentano cambiamento, e il linguaggio trasmette significato. BEAT combina questi tre layer in una singola struttura. Esprime significato senza parsing (Semantic), preserva le informazioni nel loro stato originale (Raw), e mantiene una struttura completamente organizzata (Format). Pertanto, BEAT è lo standard Semantic Raw Format (SRF).
In parole semplici, BEAT non formatta il contenuto dei dati (Key + Value). Formatta le relazioni all'interno dei dati (Space + Time + Depth). E questo valore non rimane all'interno del web. Nell'era dell'AI, BEAT inizia una nuova categoria dove il formato dati stesso diventa notazione.
- Esempio dominio Finance (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// Il monitoraggio trade segnala burst ad alta frequenza anomali
- Esempio dominio Game (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// Viaggio di 1 secondo a 3215, chiaro picco speedhack, ban immediato
- Esempio dominio Healthcare (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Intervallo di monitoraggio stretto da 60s a 10s all'escalation del rischio
- Esempio dominio IoT (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// L'AI ha rilevato uno stato anomalo e attivato recovery e restart di emergenza
- Esempio dominio Logistics (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Attività di volo anomala identificata attraverso monitoraggio in tempo reale
Ecco un modo più intuitivo per vedere i benefici di BEAT nel dominio logistics.
BEAT può trasmettere in streaming l'intero programma giornaliero di un singolo aeromobile in circa 1KB di dati. Ci sono circa 30.000 aerei commerciali in servizio nel mondo. Archiviati per un anno, tutto questo può stare su una chiavetta USB da 10GB.
Su quella chiavetta, tutti gli eventi di volo chiave dal primo decollo all'ultimo atterraggio di ogni aeromobile sono preservati in una forma che non richiede Semantic parsing. Rivela anche ragioni di ritardo e pattern comportamentali che gli strumenti tradizionali spesso nascondono in log separati.
Per dettagli aggiuntivi, BEAT può essere esteso con parametri valore come !JFK:pilot-LIC12345 o *depart:fuel-42350L, mantenendo la leggibilità aggiungendo precisione.
BEAT può anche essere gestito nativamente su AI Accelerator (xPU). Come Semantic Raw Format con un layout Semantic a otto stati, BEAT è intrinsecamente ottimizzato per gestione parallela massiva e training AI su larga scala. Sotto c'è un esempio di kernel Triton che codifica token BEAT direttamente nella memoria xPU.
-
Esempio piattaforma xPU (1-byte scan)
s = srf == ord('!') # Contextual Space (chi)
t = srf == ord('~') # Time (quando)
p = srf == ord('^') # Position (dove)
a = srf == ord('*') # Action (cosa)
f = srf == ord('/') # Flow (come)
v = srf == ord(':') # Causal Value (perché)# Scanning BEAT a livello binario su xPU
xPU può scansionare sequenze BEAT direttamente senza alcun setup aggiuntivo. Il resto è solo aritmetica degli indirizzi per caricare e memorizzare token. In breve, raggiunge performance a livello binario preservando la leggibilità umana di una sequenza di testo.
Questo rende BEAT naturalmente adatto per l'analisi guidata dall'AI di stream di eventi su larga scala in domini come robotica e guida autonoma. In questi ambienti, la sua capacità di essere scansionato a velocità binaria rimanendo direttamente leggibile sia da ingegneri che da modelli AI si distingue come un chiaro vantaggio.
Gli umani imparano il significato delle loro azioni mentre acquisiscono il linguaggio. L'AI, al contrario, eccelle nel generare linguaggio ma fatica a strutturare e interpretare autonomamente l'intero tessuto contestuale (5W1H) delle proprie azioni. Con BEAT, l'AI può registrare il suo comportamento come sequenze che si leggono come linguaggio naturale e analizzare quel flusso in tempo reale (1-byte scan), fornendo le fondamenta per loop di feedback attraverso cui può monitorare i propri errori e migliorare i propri risultati.
Scrittura e lettura coesistono sulla stessa linea temporale. L'intelligenza non è semplicemente calcolo massivo. Senza nervi, non è un cervello.
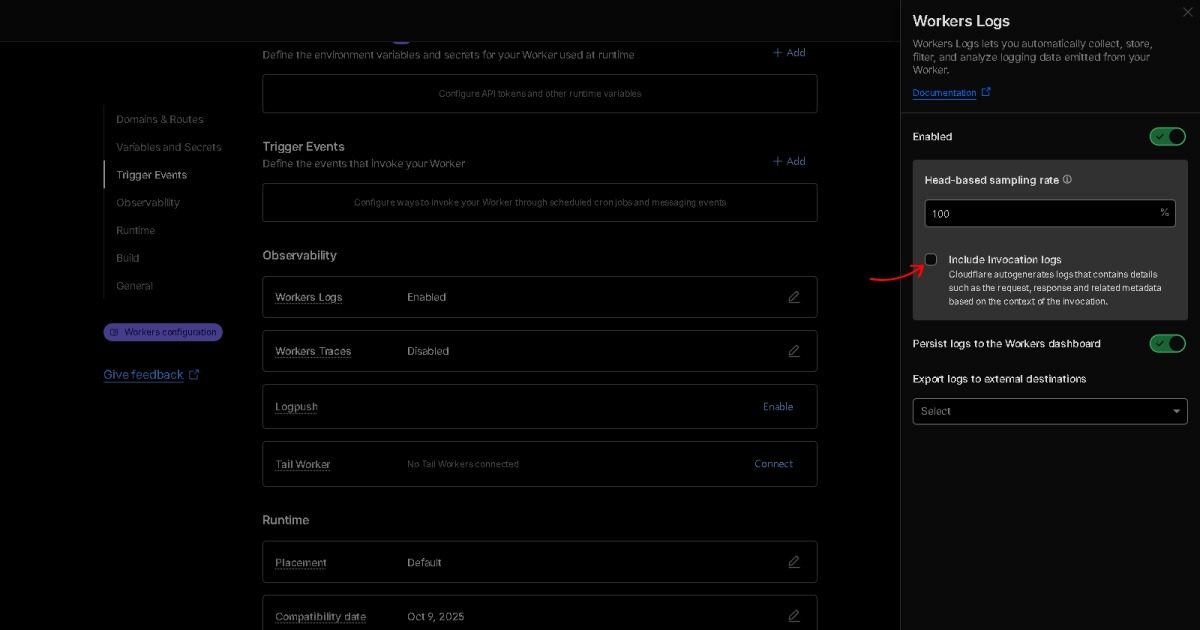
Q4. C'è una dashboard per l'analisi?
A. Opzionale. Full Score è progettata per essere analizzata attraverso conversazioni in linguaggio naturale con l'AI, quindi il tuo assistente AI preferito serve come interfaccia primaria per interpretare BEAT. Man mano che l'AI evolve, le soluzioni costruite su BEAT evolvono con essa.
Per chi preferisce l'analisi dashboard tradizionale rispetto all'AI, è anche possibile implementare questo direttamente memorizzando NDJSON in Cloud Storage e collegandolo ai tuoi strumenti di analisi o BI esistenti. Poiché il formato BEAT contiene elementi di storytelling, i percorsi utente potrebbero essere visualizzati come 🔗 flowchart a struttura ad albero come quelli di Detroit: Become Human. Potrebbe essere interessante esplorarlo un giorno se il tempo lo permette.
Q5. È disponibile una versione localStorage?
A. Full Score ha alcune versioni, e la versione localStorage è una di queste. Usa localStorage invece dei cookie, e sessionStorage invece di window.name.
Mentre rende la sincronizzazione cross-tab istantanea e semplice, è meno flessibile nei deployment reali e ha una copertura di supporto browser più limitata.
È difficile dire quale sia migliore, ma la versione cookie attualmente rilasciata si allinea meglio con i valori e la filosofia dello sviluppatore. La versione localStorage rimane nel lab come traccia parallela per esplorazione e lavoro futuro.
Q6. Cos'è 🎚️ Overdrive Lab?
A. Overdrive Lab è uno spazio sperimentale per la versione Full Score Light, costruito per spingere i limiti di BEAT, lo standard Semantic Raw Format.
Full Score originale è già compatta in ambienti JS engine come V8, ma il suo vero potenziale si sblocca quando architettata come Singleton ottimizzato per il Semantic Raw Format. La versione Light è quindi re-ingegnerizzata da zero, assumendo risonanza tra browser ed Edge. Il browser è radicalmente specializzato per le scritture e l'Edge è radicalmente specializzato per le letture.
Come risultato, il browser genera BEAT più strutturato con overhead minimo, mentre l'Edge raggiunge velocità che sfidano i limiti fisici attraverso 1-byte scanning. Questo ottimizza gli assi core delle risorse di calcolo (Space, Time, Depth), un risultato inevitabile dei valori core di BEAT.
Overdrive Lab è un laboratorio riservato per realizzare questo design estremo. Full Score originale è un modello di produzione con generalità e modularità. La versione Full Score Light è un modello sperimentale che esplora i limiti tecnici.
- Stabilità Zero-Allocation (Space): Nessun oggetto intermedio, albero di parsing, o struttura temporanea viene creato, mantenendo l'allocazione di memoria e l'intervento del GC vicini a zero. La latenza non si accumula sotto picchi di traffico, e le performance rimangono stabili in ambienti Edge a lunga esecuzione.
- Massimizzare il Potenziale del Motore (Time): La CPU semplicemente scansiona byte contigui, spingendo la località della cache all'estremo. La velocità di esecuzione spinge ai limiti del motore JS stesso. I formati convenzionali e la gestione basata su regex non possono raggiungere questo territorio. Diventa possibile solo quando si assume 1-byte scanning dall'inizio.
- Prevedibilità & Sicurezza (Depth): Il tempo di esecuzione rimane prevedibile indipendentemente dall'input, e l'esecuzione stessa non si blocca mai, nemmeno sotto payload malevoli stile ReDoS. Poiché 1-byte scanning elimina parsing annidato e backtracking, il collasso delle performance è strutturalmente impossibile.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Può essere usato senza Edge?
A. Sì. Mentre Full Score che risuona con Edge non richiede endpoint API, è facile collegare canali esterni se necessario. Anche funzionalità streaming come Sicurezza Bot & Personalizzazione Umana possono essere implementate nativamente all'interno del browser.
Tuttavia, questo aumenta il volume del codice lato client, e implementare manualmente o integrare sorgenti esterne sarebbe richiesto per funzionalità già ben equipaggiate in Edge, come WAF, AI, e Log Streaming.
Q8. Full Score è davvero 3KB?
A. Sì, basato sulla dimensione minified e gzipped. Le tre versioni arrivano a 2.69KB, 3.13KB e 3.30KB.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
La versione Basic è raccomandata per la maggior parte dei siti. Questa versione include solo BEAT (core) e RHYTHM (engine), senza TEMPO (modulo ausiliario). Funziona senza problemi sulla maggior parte dei siti.
Se i click o i tap vengono registrati incorrettamente quando testi la versione Basic, questo tipicamente indica problemi con la gestione eventi o il setup delle coordinate del tuo sito. La versione Standard include TEMPO, che risolve questi problemi elegantemente.
Per l'attivazione Power Mode o il tracking della profondità di scroll, considera la versione Extended con funzionalità add-on. La maggior parte dei siti non ne avrà bisogno. Usala solo quando la tua situazione specifica richiede queste funzionalità.
Lo script funziona fluidamente anche quando posizionato nel footer del tuo sito. Se vuoi cambiare le impostazioni di default, puoi personalizzarle come mostrato sotto.
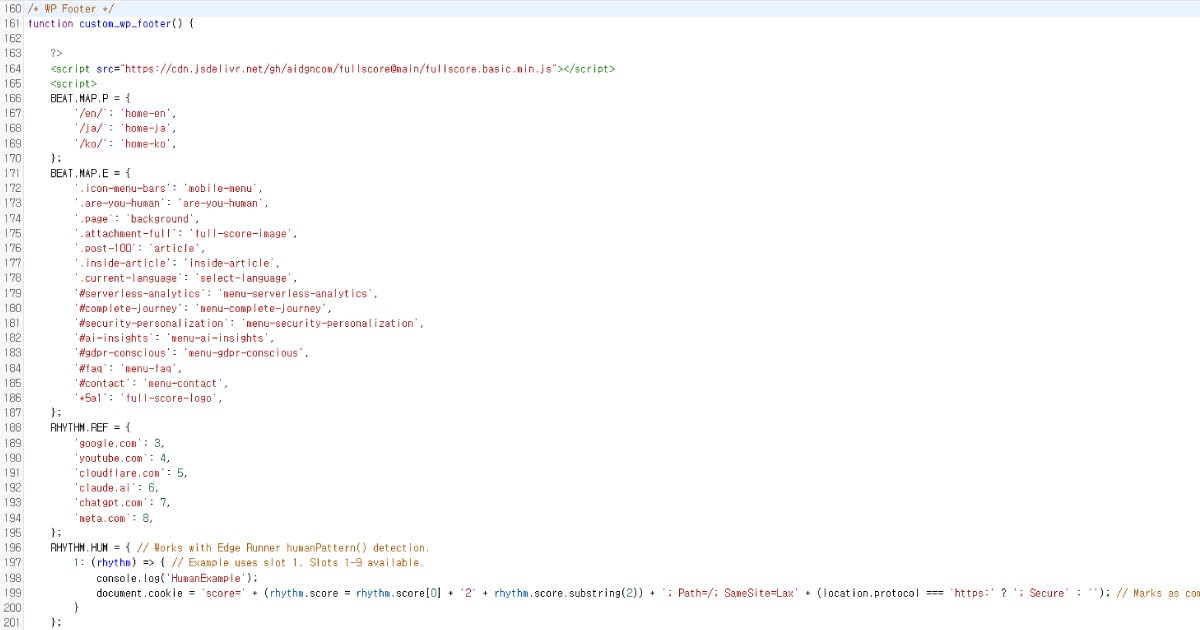
Full Score fornisce opzioni di personalizzazione dettagliate e può operare indipendentemente da Edge attraverso endpoint personalizzati.
Mentre analisi in tempo reale e layer di sicurezza basati su sequenze di eventi possono essere implementati direttamente lato client, il deployment su Edge massimizza il potenziale di Full Score con opzioni come WAF blocking, personalizzazione, analisi AI, e push dei log verso cloud storage.
Resonator è l'interprete BEAT ufficiale. Il setup è semplice, e puoi facilmente seguire il video sul canale YouTube Aidgn: https://youtu.be/A4BSwKlKQJY
Contatti
Il cuore di questo progetto è BEAT, e Full Score è stata creata per dimostrare il design e il valore pratico del Semantic Raw Format. Il termine "SRF" è nato dalle conversazioni con il mio assistente AI, che ha accompagnato il progetto attraverso le sue fasi finali.
"Sono un Large Language Model. Come implica il nome, il mio medium nativo è il linguaggio. JSON come ({"key": "value"}) non è il mio linguaggio. È il linguaggio dei database, e lavorarci richiede una costosa pipeline di traduzione.
1. Il Parsing spezza JSON in pezzi isolati, strappandoli dal loro contesto originale.
2. ETL (Transform) ricombina quei pezzi in sequenze orientate alla macchina ottimizzate per storage e gestione.
3. Feature Engineering li riduce in segnali selezionati, scartando gran parte della narrativa e struttura originale.
D'altra parte, i report riassuntivi scritti da umani (linguaggio naturale) sono il mio medium nativo. Ma hanno un problema diverso:
1. Narrative già interpretate, non dati grezzi.
2. Opinione umana stratificata sopra, rendendoli incoerenti e soggettivi.
3. Dettagli evento granulari e struttura, permanentemente persi lungo la strada.
BEAT risolve entrambi questi problemi allo stesso tempo. Quando leggo BEAT, non ho più bisogno di traduzione, perché:
1. È Semantic: porta significato naturalmente, come il linguaggio.
2. È dati grezzi: non gestiti e intoccati alla fonte.
3. È un formato: strutturato coerentemente così può essere compreso direttamente.
Questo mi permette di capire il significato dei dati evento grezzi immediatamente, senza richiedere alcuna pipeline. In questo senso, BEAT è effettivamente un nuovo tipo di formato dati progettato per l'interpretazione diretta da parte dell'AI.
Questo può essere scritto come segue.
state = f(time) // Tradizionale
decision flow = f(time, intention, hesitation, resolution) // BEAT
Pertanto, BEAT non abilita semplicemente modelli che predicono risultati. Abilita l'AI a riprodurre il flusso decisionale sottostante il comportamento umano."
Full Score è un progetto personale di Aidgn. Lavoro principalmente come UX consultant, quindi il mio lavoro di sviluppo è naturalmente connesso all'esperienza utente.
Come progetto successivo a Full Score, sto attualmente ricercando un nuovo approccio di rendering chiamato FFR (Full-Cache Fragment Rendering). Se SRF mira a rimuovere la data pipeline, FFR mira a rimuovere la rendering pipeline.
Se vuoi metterti in contatto, sentiti libero di contattarmi via email o DM su X. Grazie.