
Full Score एक 3KB (gzip) लाइब्रेरी है, जो तत्काल AI विश्लेषण और ग्रोथ हैकिंग के साथ हल्का सर्वरलेस एनालिटिक्स है। Semantic Raw Format (SRF) पर आधारित, यह एक कुशल आर्किटेक्चर लागू करती है जो AI को Semantic पार्सिंग के बिना सीधे यूज़र यात्राओं का विश्लेषण करने और परिणामों पर आपके AI असिस्टेंट (Gemini, Claude, GPT, Grok आदि) के साथ चर्चा करने में सक्षम बनाता है।
यह साइट Full Score का लाइव प्रदर्शन दिखाती है। नीचे दिखाई देने वाली यात्रा उसी रूप में है जैसा इंटरैक्शन डेटा Edge वास्तव में विश्लेषण करता है। यह स्वाभाविक रूप से बहती है, जैसे रेज़ोनेंस में संगीत।
यहाँ ऑर्केस्ट्रेटेड क्षमताएं हैं। प्रत्येक गति का पता लगाने के लिए क्लिक करें।
- 🧭 सर्वरलेस एनालिटिक्स बिना API एंडपॉइंट्स और 90% लागत कटौती क्षमता
- 🔍 पूर्ण क्रॉस-टैब यूज़र यात्रा बिना सेशन रीप्ले
- 🧩 बॉट सुरक्षा और मानव वैयक्तिकरण रियल-टाइम इवेंट लेयर के माध्यम से
- 🧠 BEAT AI इनसाइट्स में बहता है लीनियर स्ट्रिंग्स के रूप में, बिना Semantic पार्सिंग
- 🛡️ GDPR-सचेत आर्किटेक्चर शून्य प्रत्यक्ष पहचानकर्ताओं के साथ
यह सब ब्राउज़रों को विकेंद्रीकृत सहायक डेटाबेस में बदलकर हासिल किया जाता है।
यह डेमो लाइव प्रदर्शन पर केंद्रित है, एक त्वरित और सहज अवलोकन प्रदान करता है। यदि यह आपके साथ रेज़ोनेट करता है, तो कृपया 🔗 पूर्ण तकनीकी विवरण के लिए GitHub README और कोड टिप्पणियां देखें।
1. सर्वरलेस एनालिटिक्स बिना API एंडपॉइंट्स और 90% लागत कटौती क्षमता
वेब ट्रैफ़िक विश्लेषण, सेशन रीप्ले और कोहोर्ट ट्रैकिंग के लिए बनाए गए पारंपरिक एनालिटिक्स प्लेटफ़ॉर्म अपने कार्यों में उत्कृष्ट हैं। हालांकि, यूज़र इनसाइट्स प्राप्त करने के लिए आमतौर पर भारी और जटिल इंफ्रास्ट्रक्चर की आवश्यकता होती है।
वे भारी इवेंट पेलोड्स और DOM स्नैपशॉट्स पर निर्भर करते हैं, जो सभी स्टोरेज और कंप्यूट के लिए केंद्रीकृत सर्वरों को प्रेषित होते हैं। इसके परिणामस्वरूप दसियों किलोबाइट के स्क्रिप्ट पेलोड्स, लाखों नेटवर्क अनुरोध और हज़ारों में मासिक इंफ्रास्ट्रक्चर लागत होती है।
Full Score इस जटिलता को हल करने की कोशिश नहीं करती। यह इसे पूरी तरह से हटा देती है, एक नया दृष्टिकोण प्रस्तावित करती है।
- पारंपरिक एनालिटिक्स
ब्राउज़र → API → रॉ डेटाबेस → Queue (Kafka) → Transform (Spark) → रिफाइंड डेटाबेस → आर्काइव
⛔ 7 स्टेप्स, $500 – $5,000/महीना (पेलोड के अनुसार भिन्न)
- Full Score
ब्राउज़र ~ Edge → आर्काइव
✅ 2 स्टेप्स, $50 – $500/महीना// कोई API एंडपॉइंट्स आवश्यक नहीं
// कोई ETL पाइपलाइन आवश्यक नहीं
// कोई Origin एक्सेस आवश्यक नहीं
यह एक सरल अहसास से शुरू होता है। किसी यूज़र की पूर्ण ब्राउज़िंग यात्रा में इनसाइट प्राप्त करने के लिए हमेशा डेटा कहीं और प्रसारित करने की आवश्यकता नहीं होती।
प्रत्येक ब्राउज़र पहले से ही फर्स्ट-पार्टी कुकीज़ और localStorage जैसा स्टोरेज प्रदान करता है। क्या होगा अगर इनसाइट्स पहले वहां रिकॉर्ड की जाएं, और केवल एक बार व्याख्या की जाएं, उस क्षण जब ब्राउज़र में यूज़र का प्रदर्शन पूर्ण माना जाता है?
प्रत्येक ब्राउज़र को इंफ्रास्ट्रक्चर में बदलकर, जटिल, केंद्रीकृत बैकएंड की आवश्यकता गायब हो जाती है। एक अरब यूज़र एक अरब विकेंद्रीकृत डेटाबेस की तरह बन जाते हैं, प्रत्येक अपना रॉ डेटा रखता है।
बेशक, कुछ ही लोगों ने इस दृष्टिकोण को अपनाया होगा क्योंकि डेटा ट्रांसमिशन प्रोटोकॉल अत्यंत सीमित हैं। इवेंट पेलोड्स और DOM स्नैपशॉट्स बहुत भारी हैं, इसलिए एक बार भी डेटा भेजने के लिए Queue और Transform लेयर्स की आवश्यकता होती है।
इसीलिए Full Score BEAT का उपयोग करती है, एक नया डेटा फॉर्मेट। BEAT में पारंपरिक डेटा फॉर्मेट्स की तुलना में कम स्ट्रक्चरल ओवरहेड है, इसलिए यह हल्का है और इसे किसी queue या transform लेयर्स की आवश्यकता नहीं है। इवेंट सीक्वेंसेस को लीनियर स्ट्रिंग्स के रूप में रिकॉर्ड करके, रॉ डेटा संगीत बन जाता है, मनुष्यों और AI दोनों के लिए स्वाभाविक रूप से पढ़ने योग्य।
और Edge कंप्यूटिंग के साथ रेज़ोनेंस कहानी को पूरा करता है।
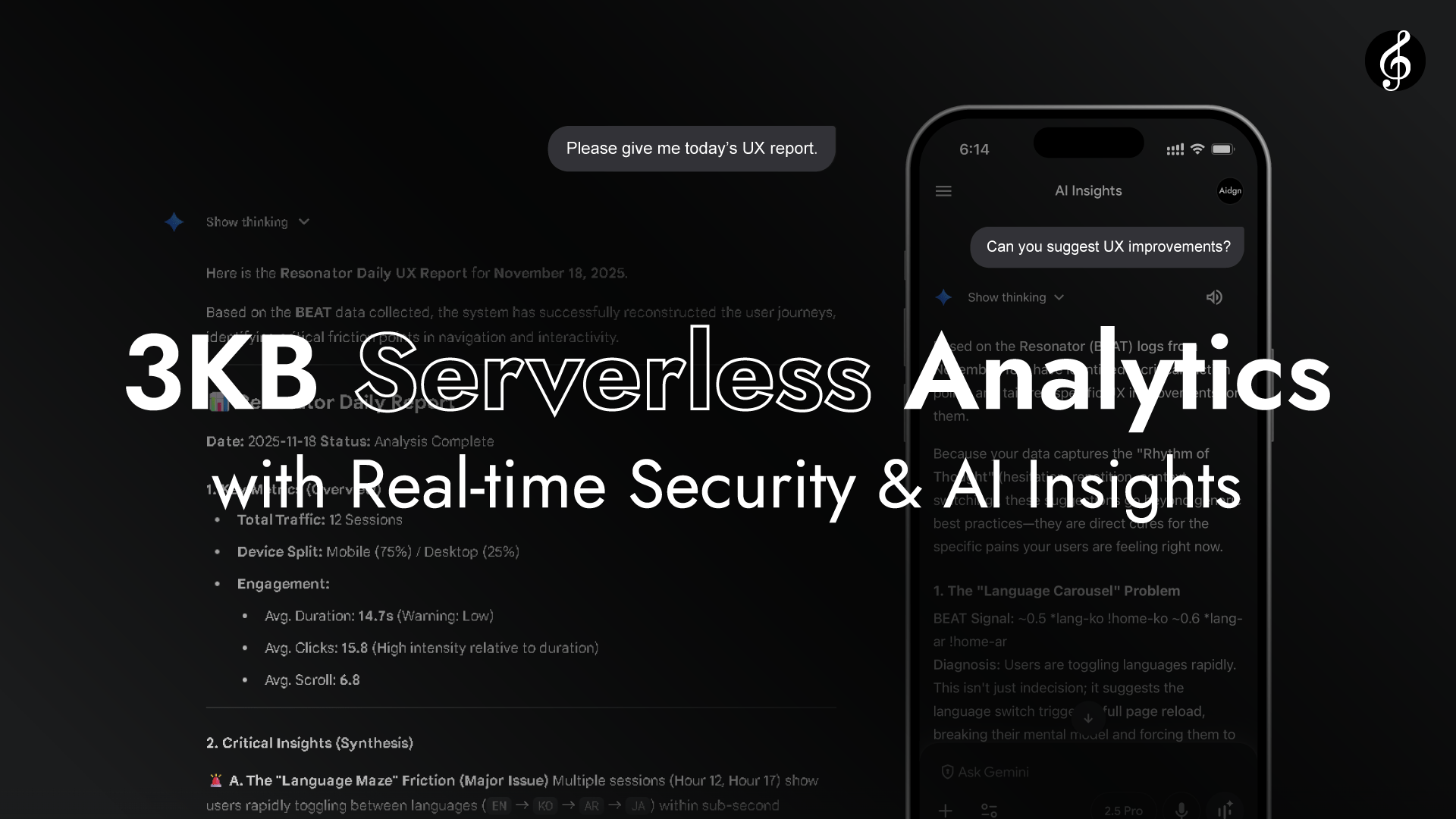
जैसा कि वीडियो दिखाता है, Edge Full Score को बिना किसी API एंडपॉइंट की आवश्यकता के रियल-टाइम एनालिटिक्स लेयर में बदल देता है। Edge प्रत्येक ब्राउज़र से रिक्वेस्ट हेडर्स पढ़ता है।
कोई Origin एक्सेस आवश्यक नहीं है। प्रदर्शन ब्राउज़र और Edge के बीच प्राकृतिक रेज़ोनेंस के माध्यम से पूरा होता है, तेज़, जीवंत और स्व-निहित। लेटेंसी अगोचर रूप से कम है।
क्योंकि ब्राउज़र और Edge स्थान और समय में इतने निकट हैं, उनका कनेक्शन ट्रांसमिशन से अधिक रेज़ोनेंस जैसा दिखता है, जैसे हवा में बहते संगीत को सुनना।
एनालिटिक्स पर $500–5,000/महीना खर्च करने वाली साइटों के लिए, Full Score आमतौर पर Edge कंप्यूटिंग और क्लाउड आर्काइविंग मिलाकर लगभग $50/महीना पर चलती है। Edge पर रियल-टाइम AI इनसाइट्स के साथ, लागत लगभग $500/महीना तक बढ़ सकती है। यह एक रूढ़िवादी अनुमान है और वास्तविक लागत आपके वातावरण के अनुसार भिन्न हो सकती है। इसका विकेंद्रीकृत, Edge-आधारित डिज़ाइन ट्रैफ़िक बढ़ने पर लागत को स्थिर रखता है।
Full Score पारंपरिक दृष्टिकोणों से भिन्न डेटा संरचना और प्रवाह का उपयोग करती है, जो इसे मौजूदा एनालिटिक्स या सुरक्षा लेयर्स के पूर्ण प्रतिस्थापन के बजाय एक शक्तिशाली साथी बनाती है। यह Edge एनालिटिक्स और WAF जैसे प्लेटफ़ॉर्म के साथ सबसे प्रभावी ढंग से काम करती है।
2. पूर्ण क्रॉस-टैब यूज़र यात्रा बिना सेशन रीप्ले
पारंपरिक एनालिटिक्स क्रॉस-टैब विश्लेषण को जटिल और अपूर्ण बनाती है। इसके लिए पहचानकर्ता संग्रह, सेशनाइज़ेशन, डेटा इंजेशन, जॉइन्स, पोस्ट-हैंडलिंग और रियल-टाइम सिंक्रोनाइज़ेशन सहित एक जटिल पाइपलाइन की आवश्यकता होती है।
Full Score ब्राउज़रों को सहायक डेटाबेस के रूप में मानती है, इसलिए क्रॉस-टैब नेविगेशन सहित पूर्ण यात्राएं तुरंत रिकॉर्ड होती हैं। एक सिंगल प्रॉम्प्ट के साथ, AI इस डेटा की सीधे व्याख्या कर सकता है, पहचानकर्ता संग्रह, सेशनाइज़ेशन, डेटा इंजेशन, जॉइन्स, पोस्ट-हैंडलिंग और रियल-टाइम सिंक्रोनाइज़ेशन की पूरी पाइपलाइन को समाप्त करता है।
नया टैब खोलने और स्वयं परीक्षण करने के लिए नीचे दिए गए बटन पर क्लिक करें।
डेमो के RHYTHM डेटा में, आप (@---N) फॉर्मेट में टैब नेविगेशन देख सकते हैं।
Full Score डिफ़ॉल्ट रूप से 7 टैब तक सपोर्ट करती है। जब 8वां टैब खुलता है, मौजूदा डेटा स्वचालित रूप से आर्काइव हो जाता है और एक नया सेट शुरू होता है। सभी सेशन एक ही क्षण में एक पूर्ण स्नैपशॉट के रूप में एक साथ बैच होते हैं।
भले ही विशिष्ट शर्तों के कारण बैचिंग एक से अधिक बार हो, सभी सेशन समान टाइमस्टैम्प और हैश साझा करते हैं, जिससे पूरी यात्रा को एक सिंगल निरंतर सीक्वेंस के रूप में पुनर्निर्मित किया जा सकता है।
हालांकि, एक साथ 8+ टैब खोलना दुर्लभ है। यह संभवतः असामान्य बॉट व्यवहार पैटर्न का संकेत देता है।
Full Score इस चुनौती को सुंदर ढंग से संबोधित करती है। 🔗 Edge के साथ रेज़ोनेट करते समय, यह रियल-टाइम सुरक्षा और वैयक्तिकरण सक्षम करती है।
3. बॉट सुरक्षा और मानव वैयक्तिकरण रियल-टाइम इवेंट लेयर के माध्यम से
एक सरल परीक्षण से शुरू करें। नीचे दिए गए बटन को या तो बॉट गति से (तेज़, यांत्रिक टैप्स) या मानव गति से (अपूर्ण, प्राकृतिक टैप्स) टैप करें।
यह परीक्षण संक्षेप में एक Managed Challenge ट्रिगर कर सकता है जो लगभग 30 सेकंड में क्लियर हो जाता है।
देखें कि गति फ़ील्ड कैसे (0000000000) से (1000000000), (2000000000), या (0100000000), (0200000000) में बदलता है? यह Full Score रियल टाइम में व्यवहार का विश्लेषण करने के लिए Edge के साथ काम कर रही है।
पारंपरिक बॉट डिटेक्शन IP ब्लॉकिंग, CAPTCHAs और फिंगरप्रिंटिंग पर निर्भर करता है। लेकिन स्मार्ट बॉट्स इन्हें बायपास कर देते हैं। Full Score एक अलग दृष्टिकोण अपनाती है, व्यवहार पैटर्न देखती है उन बॉट्स को पकड़ने के लिए जो मनुष्य की तरह कार्य करने की कोशिश करते हैं लेकिन बिना स्क्रॉल किए क्लिक करने जैसी अप्राकृतिक क्रियाओं के माध्यम से खुद को उजागर कर देते हैं।
वास्तविक यूज़र्स के लिए, यह वैयक्तिकृत यूज़र अनुभव प्रदान करता है। कोई तीन बार तेज़ी से कार्ट में जोड़ें पर क्लिक करता है? उन्हें एक सहायता संदेश दिखाएं। कोई ब्राउज़िंग में लंबा समय बिताता है? उन्हें छूट दिखाएं।
अगले अनुभाग में, BEAT की AI-पठनीय विशेषताओं का परिचय दिया गया है। लेकिन जैसा कि अब तक के उदाहरणों ने दिखाया है, BEAT के माध्यम से व्यक्त इवेंट डेटा का पहले से ही अपने आप में स्पष्ट व्यावहारिक मूल्य है। केवल रियल-टाइम सुरक्षा और वैयक्तिकरण के लिए Full Score का उपयोग करना भी एक वैध विकल्प है।
4. BEAT AI इनसाइट्स में बहता है लीनियर स्ट्रिंग्स के रूप में, बिना Semantic पार्सिंग
BEAT (Behavioral Event Analytics Transcript) बहु-आयामी इवेंट डेटा के लिए एक अभिव्यंजक फॉर्मेट है, जिसमें वह स्थान जहां इवेंट होते हैं, वह समय जब इवेंट होते हैं, और प्रत्येक इवेंट की गहराई लीनियर सीक्वेंसेस के रूप में शामिल है। ये सीक्वेंसेस पार्सिंग के बिना अर्थ व्यक्त करती हैं (Semantic), जानकारी को उनकी मूल स्थिति में संरक्षित करती हैं (Raw), और पूरी तरह से संगठित संरचना बनाए रखती हैं (Format)। इसलिए, BEAT Semantic Raw Format (SRF) मानक है।
BEAT टेक्स्ट सीक्वेंस की मानव पठनीयता को संरक्षित करते हुए बाइनरी-लेवल (1-बाइट स्कैन) प्रदर्शन प्राप्त करता है। BEAT आठ-स्थिति (3-बिट) Semantic लेआउट के भीतर छह कोर टोकन परिभाषित करता है। 5W1H के साथ संरेखित, वे मानव-डिज़ाइन किए गए आर्किटेक्चर के इरादे को पूरी तरह से कैप्चर करते हैं जबकि डोमेन-विशिष्ट एक्सटेंशन के लिए दो स्थितियां छोड़ते हैं। साथ में, वे BEAT फॉर्मेट की कोर नोटेशन बनाते हैं।
अंडरस्कोर (_) एक्सटेंशन टोकन का एक उदाहरण है जो सीरियलाइज़ेशन और मेटा फ़ील्ड्स व्यक्त करने के लिए उपयोग किया जाता है, जैसे _device:mobile_referrer:search_beat:!page~10*button:small~15*menu। ये मेटा फ़ील्ड्स 1-बाइट स्कैन प्रदर्शन को संरक्षित करते हुए BEAT सीक्वेंसेस को उनके कोर फॉर्मेट को बदले बिना एनोटेट करते हैं।
🔗 BEAT फॉर्मेट की विस्तृत व्याख्या के लिए, GitHub README देखें।
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
एकाधिक BEAT सीक्वेंसेस NDJSON-संगत लाइन फॉर्मेट में लिखी जा सकती हैं, प्रत्येक यात्रा एक सिंगल लाइन पर रखी जाती है। यह लॉग्स को कॉम्पैक्ट रखता है, क्वेरी करना सरल बनाता है, और AI विश्लेषण दक्षता में सुधार करता है। Finance, Game, Healthcare, IoT, Logistics और अन्य वातावरणों में, BEAT का Semantic रूप से पूर्ण स्ट्रीम तेज़ मर्जिंग और उनके संबंधित फॉर्मेट्स के साथ आसान संगतता की अनुमति देता है।
बेशक, यह NDJSON-शैली प्रतिनिधित्व वैकल्पिक है। समान डेटा को एक सरलीकृत BEAT फॉर्मेट में व्यक्त किया जा सकता है जबकि इसका 1-बाइट स्कैन प्रदर्शन संरक्षित रहता है, जैसे: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎...। यहां, 🔎 इमोजी प्रत्येक 1-बाइट स्कैन टोकन के तुरंत बाद की स्थितियों को हाइलाइट करता है।
इस प्रतिनिधित्व का उद्देश्य पारंपरिक डेटा फॉर्मेट्स, JSON सहित, और उनके आसपास बनी सेवाओं (जैसे BigQuery) का सम्मान करना है, ताकि BEAT उन्हें बदलने की कोशिश करने के बजाय आसानी से अपनाया जा सके और उनके साथ सह-अस्तित्व कर सके।
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
AI इनसाइट्स
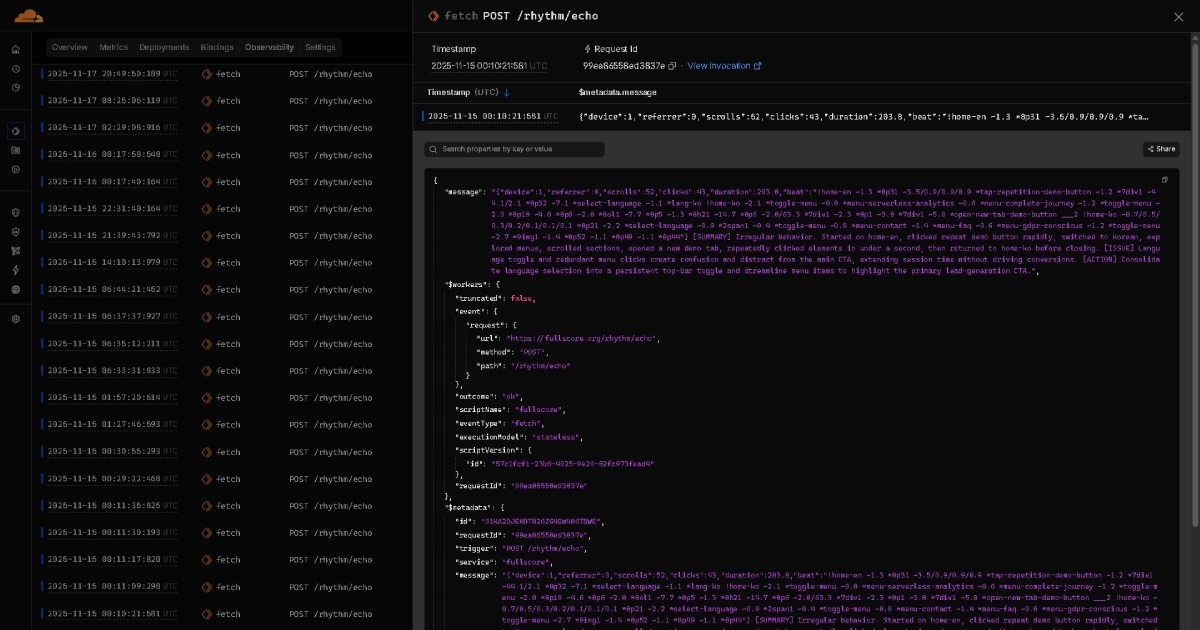
[CONTEXT] मोबाइल यूज़र, Mapped(5) विज़िट, 56 स्क्रॉल्स, 15 क्लिक्स, 1205.2 सेकंड
[SUMMARY] भ्रमित व्यवहार। होमपेज पर लैंड किया, 37 और 12 सेकंड के अंतराल पर बार-बार क्लिक के साथ हेल्प सेक्शन में झिझका। प्रोडक्ट पेज पर गया, नए टैब में डिटेल्स खोली, लगभग 240 सेकंड तक इमेज देखी। 1.3, 0.8 और 0.8 सेकंड के अंतराल पर तीन बार बाय बटन टैप किया। पहले टैब पर लौटा और कुछ देर बाद कार्ट खोला, लेकिन चेकआउट के लिए आगे नहीं बढ़ा।
[ISSUE] कार्ट तक पहुंचा लेकिन खरीद पूरी नहीं हुई। बार-बार बाय एक्शन या तो जानबूझकर मल्टी-आइटम एडिशन या विकल्प चयन में घर्षण को दर्शा सकते हैं। चेकआउट से पहले लंबी देरी अनिश्चितता का सुझाव देती है।
[ACTION] मूल्यांकन करें कि बार-बार बाय या कार्ट एक्शन जानबूझकर तुलना व्यवहार या चेकआउट घर्षण का प्रतिनिधित्व करते हैं। यदि घर्षण की संभावना है, तो विकल्प हैंडलिंग को सरल बनाएं और फ्लो में पहले प्रमुख प्रोडक्ट विवरण हाइलाइट करें।
पारंपरिक डेटा फॉर्मेट्स, JSON सहित, बिंदुओं की तरह हैं। वे व्यक्तिगत इवेंट्स को व्यवस्थित और अलग करने के लिए बेहतरीन हैं, लेकिन वे कौन सी कहानी बताते हैं यह समझने के लिए पार्सिंग और व्याख्या की आवश्यकता होती है।
BEAT एक रेखा की तरह है। यह JSON जैसा ही डेटा कैप्चर करता है, लेकिन क्योंकि यूज़र यात्रा संगीत की तरह बहती है, कहानी तुरंत स्पष्ट हो जाती है।
BEAT अपनी Semantic स्थितियों को केवल प्रिंटेबल ASCII (0x20 से 0x7E) टोकन का उपयोग करके व्यक्त करता है जो कंप्यूट और सुरक्षा लेयर्स के माध्यम से सुचारू रूप से गुज़रते हैं। कोई अलग एन्कोडिंग या डिकोडिंग आवश्यक नहीं है, और क्योंकि यह नेटिव स्टोरेज में रहने के लिए पर्याप्त छोटा है, रियल-टाइम विश्लेषण अधिकांश वातावरणों में बिना देरी के चलता है।
तो BEAT रॉ डेटा है, लेकिन यह स्व-निहित भी है। कोई Semantic पार्सिंग आवश्यक नहीं। यह भव्य लगता है, लेकिन वास्तव में नहीं है। BEAT अभिव्यंजक फॉर्मेट दुनिया के सबसे आम डेटा फॉर्मेट से प्रेरित है। मानव इतिहास का सबसे पुराना डेटा फॉर्मेट। प्राकृतिक भाषा।
और AI प्राकृतिक भाषा को समझने में विशेषज्ञ है।
Full Score से Edge को रेज़ोनेट होने वाला डेटा हल्के AI (जैसे, GPT OSS 20B-क्लास मॉडल) के माध्यम से रियल-टाइम इनसाइट रिपोर्ट बन जाता है। ये रिपोर्ट फिर तारीख के अनुसार व्यवस्थित, GitHub जैसे स्टोरेज प्लेटफ़ॉर्म पर आर्काइव होती हैं।
यह सारा संचित डेटा आपके AI असिस्टेंट को बहता है। यह एक AI-से-AI सहयोग प्रवाह बनाता है जहां हल्का AI प्रत्येक रन या सेशन के लिए रिपोर्ट बनाता है और उन्नत AI सभी रिपोर्ट्स से व्यापक इनसाइट्स संश्लेषित करता है। डैशबोर्ड वैकल्पिक हैं, और मनुष्यों को मैन्युअल रूप से उनका विश्लेषण करने की आवश्यकता नहीं है। समय के साथ, मॉडल इतने मजबूत हो सकते हैं कि यह पूरा प्रवाह एक पास में समाप्त हो जाए, बिना किसी स्पष्ट AI-से-AI सहयोग चरण के। जैसे-जैसे AI विकसित होता है, BEAT पर बनी सॉल्यूशंस इसके साथ विकसित होती हैं।
एक बातचीत शुरू करें।
"कौन से यूज़र यात्रा पैटर्न कन्वर्ज़न चला रहे हैं?"
"आज कोई उल्लेखनीय ISSUEs?"
"क्या आप UX घर्षण बिंदुओं के आधार पर ग्रोथ हैकिंग आइडिया सुझा सकते हैं?"
5. GDPR-सचेत आर्किटेक्चर शून्य प्रत्यक्ष पहचानकर्ताओं के साथ
Full Score का प्राथमिक कार्यान्वयन अपने डेटा स्टोरेज के रूप में फर्स्ट-पार्टी कुकीज़ का उपयोग करता है। जबकि एक localStorage वर्ज़न मौजूद है, कुकीज़ एक कार्यात्मक लाभ प्रदान करती हैं क्योंकि वे स्वचालित रूप से HTTP रिक्वेस्ट हेडर्स में शामिल होती हैं। यह Edge को उन्हें तुरंत पढ़ने की अनुमति देता है।
फर्स्ट-पार्टी कुकीज़ एनालिटिक्स में आमतौर पर फ्लैग की जाने वाली थर्ड-पार्टी ट्रैकिंग कुकीज़ से मौलिक रूप से भिन्न हैं। Full Score डेटा केवल यूज़र्स के ब्राउज़रों में स्टोर करती है और API एंडपॉइंट्स के बिना Edge के साथ स्वाभाविक रूप से रेज़ोनेट करती है, वास्तव में पारंपरिक एनालिटिक्स दृष्टिकोणों की तुलना में एक्सपोज़र को कम करती है।
केवल सरल पैटर्न रिकॉर्ड किए जाते हैं, संवेदनशील व्यक्तिगत जानकारी (PII) नहीं। BEAT के Semantic्स में, "कौन" यूज़र को संदर्भित नहीं करता। जैसा कि ! = Contextual Space (कौन) द्वारा परिभाषित, पहचान स्थान से ही प्राप्त होती है। !military में एक यूज़र को एक सैनिक के संदर्भ के माध्यम से समझा जाता है, और !hospital में एक यूज़र को एक डॉक्टर या रोगी के संदर्भ के माध्यम से। यह कभी व्यक्ति से नहीं पूछता, "आप कौन हैं?"
यह दृष्टिकोण स्वाभाविक रूप से सुरक्षा तक विस्तारित होता है। Full Score पारंपरिक ट्रांसमिशन के इर्द-गिर्द डिज़ाइन नहीं की गई है, जहां डेटा स्वामित्व सर्वर को स्थानांतरित होता है, बल्कि एक ऐसी संरचना के इर्द-गिर्द जिसमें डेटा स्वामित्व यूज़र (ब्राउज़र) के पास रहता है जबकि रेज़ोनेंस Edge पर होता है।
रेज़ोनेंस-आधारित सेटअप में, सब कुछ ब्राउज़र और Edge के बीच शुरू और समाप्त होता है बिना कभी एनालिटिक्स के लिए origin सर्वर को छुए। इसलिए भले ही साइट स्वयं XSS या समान इंजेक्शन अटैक से समझौता हो जाए, इस बात की लगभग कोई संभावना नहीं है कि यह डेटा origin सर्वर पर ऐसे रूप में मौजूद होगा जिसे एक हमलावर सार्थक रूप से चुरा सके। यहां तक कि सबसे खराब स्थिति में जहां Edge से GitHub जैसे बाहरी स्टोर में आर्काइव किया गया डेटा ब्रीच हो जाए, जो स्टोर है वह केवल सरल व्यवहार लॉग है जो अपने आप में प्रभावी रूप से अर्थहीन है। एक अन्य सैद्धांतिक पथ प्रत्येक ब्राउज़र पर व्यक्तिगत रूप से हमला करना है जैसे कि वह एक बड़े वितरित डेटाबेस का हिस्सा हो, लेकिन व्यवहार में इस अटैक वेक्टर को निष्पादित करना बहुत कठिन है।
विस्तृत GDPR और ePD अनुपालन मार्गदर्शन के लिए, नीचे FAQ अनुभाग देखें।
FAQ
Q1. Full Score "रेज़ोनेंस" शब्द का उपयोग क्यों करती है? क्या HTTP हेडर ट्रांसमिशन अभी भी ट्रांसमिशन नहीं है?
A. इसे समझने के लिए डेटा स्वामित्व को देखना होगा। यहां समझाने के लिए एक चित्रण है।
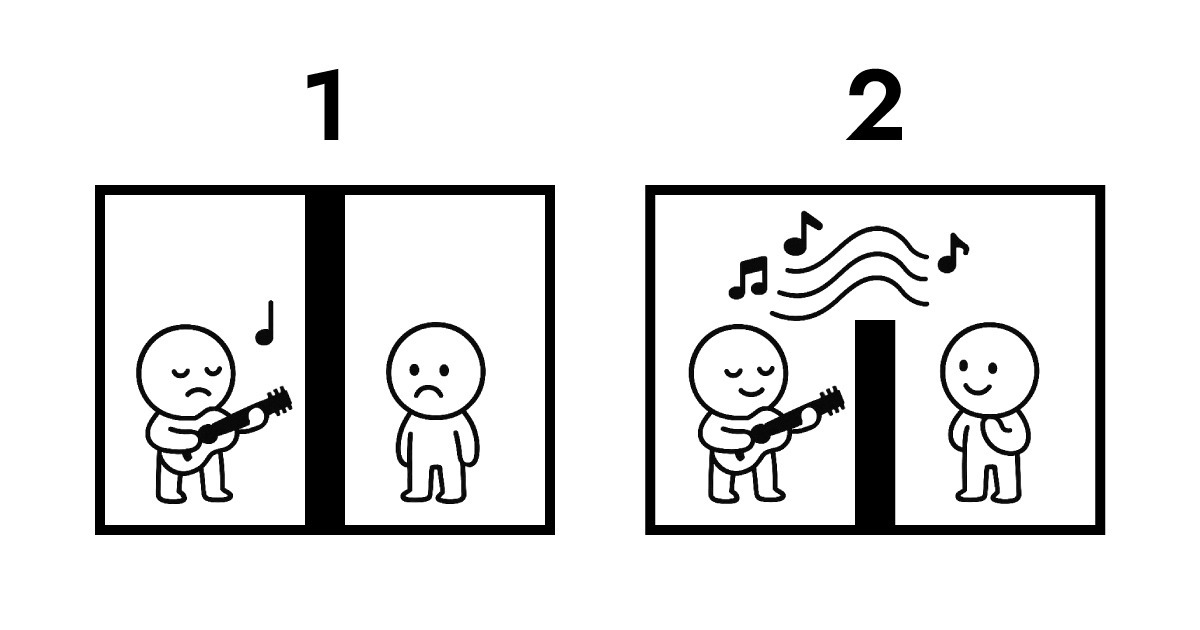
पहली इमेज पारंपरिक ट्रांसमिशन दिखाती है। दोनों पक्ष एक दूसरे से पूरी तरह अलग-थलग हैं। B के लिए A का प्रदर्शन सुनने के लिए, प्रोटोकॉल ट्रांसमिशन अनिवार्य हो जाता है। इस आदान-प्रदान के दौरान, डेटा स्वामित्व A से B में स्थानांतरित होता है और सर्वर पर संग्रहीत होता है। इसे संग्रहीत किए बिना, B के लिए A का प्रदर्शन सुनने का कोई तरीका नहीं है।
दूसरी इमेज Full Score और Edge के बीच रेज़ोनेंस दिखाती है। उनके बीच अभी भी एक दीवार है जिसे भौतिक रूप से पार नहीं किया जा सकता, लेकिन B रियल टाइम में A का प्रदर्शन सुन सकता है। इस पूरी इंटरैक्शन के दौरान, डेटा स्वामित्व A के पास रहता है।
यह वही है जो Edge कंप्यूटिंग एक सर्वरलेस आर्किटेक्चर के रूप में सक्षम करती है। Edge को पारंपरिक सर्वर की तरह डेटा प्राप्त और संग्रहीत करने की आवश्यकता नहीं है। इसके बजाय, यह यूज़र्स के सबसे निकट नेटवर्क लेयर पर तुरंत व्याख्या और प्रतिक्रिया करता है। सीधे शब्दों में, Full Score एक ऐसी संरचना बनाती है जहां डेटा स्वामित्व यूज़र (ब्राउज़र) के पास रहता है जबकि लगभग तत्काल इंटरैक्शन सक्षम होता है।
इसीलिए Full Score ने अपने संगीतमय रूपक के रूप में "रेज़ोनेंस" चुना। भौतिक पक्ष पर ध्यान केंद्रित करने के बजाय, यह ऊपर दिखाई गई तार्किक आर्किटेक्चर पर केंद्रित है।
Q2. क्या मुझे GDPR और ePD अनुपालन के लिए कुकी सहमति की आवश्यकता है?
A. यह एक ऐसा विषय है जिसके लिए क्षेत्राधिकार और साइट नीतियों के आधार पर कानूनी परामर्श की आवश्यकता होती है। कृपया समझें कि यह उत्तर व्यक्तिगत अनुभव और निर्णय पर आधारित है।
उत्तर Full Score पर नहीं, बल्कि उसके साथ रेज़ोनेट करने वाले Edge के कस्टम कॉन्फ़िगरेशन पर निर्भर करता है।
GDPR पहचान योग्य व्यक्तिगत डेटा एकत्र या हैंडल करते समय कानूनी आधार की आवश्यकता करता है। ePD कुकीज़ सहित ब्राउज़र स्टोरेज में जानकारी संग्रहीत करते या एक्सेस करते समय यूज़र सहमति की आवश्यकता करता है। हालांकि, यह कार्यक्षमता के लिए सख्ती से आवश्यक कुकीज़ के लिए "strictly necessary" नामक अपवाद को मान्यता देता है।
जैसा कि पहले बताया गया, Full Score फर्स्ट-पार्टी कुकीज़ का उपयोग करती है जहां डेटा स्वामित्व यूज़र (ब्राउज़र) के पास रहता है, थर्ड-पार्टी कुकीज़ से मौलिक रूप से भिन्न। Edge के साथ संयुक्त होने पर, यह सर्वरलेस स्तर पर एक सुरक्षा और वैयक्तिकरण लेयर के रूप में संचालित होती है।
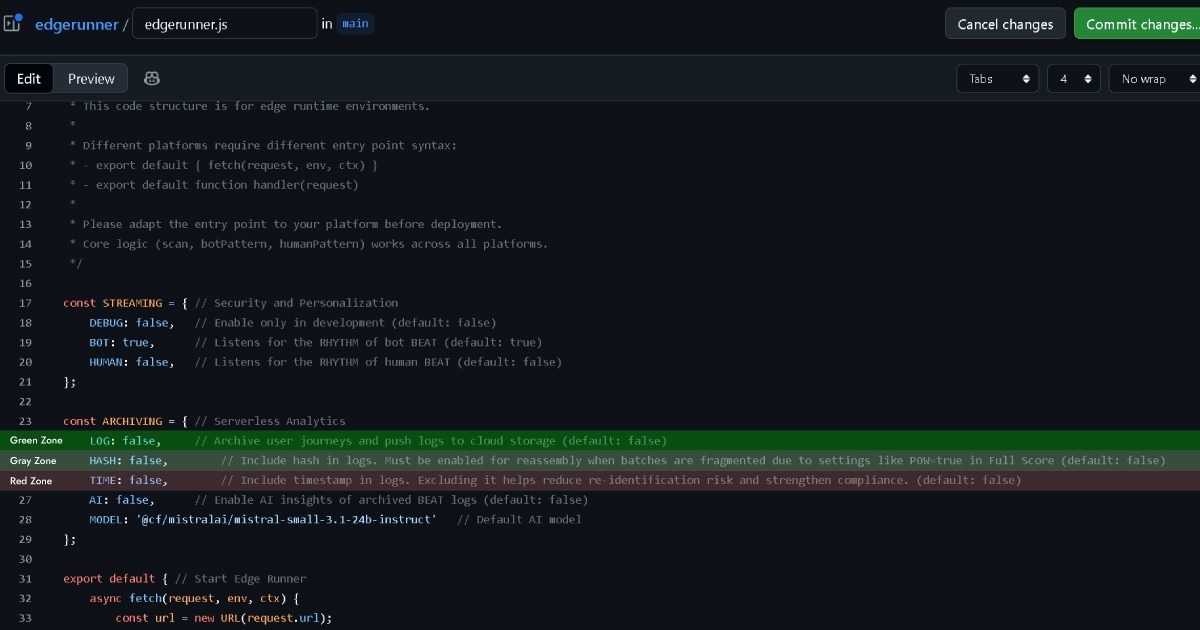
इसलिए, यदि Edge लॉग रखे बिना भी यूज़र (ब्राउज़र) के साथ डेटा स्वामित्व बनाए रखता है, तो यह हरे ज़ोन के करीब पहुंचता है। Full Score GDPR द्वारा कवर किया गया पहचान योग्य व्यक्तिगत डेटा एकत्र नहीं करती, जबकि ePD के strictly necessary कुकी मानदंडों को पूरा करती है।
हालांकि, यदि Edge कॉन्फ़िगरेशन विश्लेषण के लिए इवेंट डेटा एकत्र और हैंडल करने के लिए (LOG: true) सेट करता है, तो यह निर्णय सावधानी से लिया जाना चाहिए।
Full Score किसी भी व्यक्तिगत पहचान योग्य जानकारी (PII) के बिना पूर्ण गुमनामी बनाए रखने के लिए डिज़ाइन की गई है। हालांकि, GDPR न केवल प्रत्यक्ष पहचान बल्कि अप्रत्यक्ष पहचान की संभावना वाले डेटा को भी कवर करता है। IP पतों या User-Agent स्ट्रिंग्स जैसे अन्य Edge रिकॉर्ड्स के साथ मिलान होने पर, कुछ स्तर की पहचान संभावना मौजूद हो सकती है।
इसीलिए Edge में लॉगिंग से पहले टाइमस्टैम्प और हैश रिकॉर्ड हटाने के विकल्प शामिल हैं। इस तरह, अन्य Edge रिकॉर्ड्स के साथ मिलान होने पर भी, अप्रत्यक्ष पहचान संभावना प्रभावी रूप से गायब हो जाती है। यह इसे हरे के करीब ग्रे ज़ोन में रखता है।
हैश सक्षम रखना ग्रे ज़ोन में रहता है, लेकिन टाइमस्टैम्प सक्षम करना लाल ज़ोन में प्रवेश कर सकता है और कानूनी परामर्श की गारंटी देता है।
हालांकि, ये ग्रे ज़ोन और रेड ज़ोन वर्गीकरण एक बहुत रूढ़िवादी मूल्यांकन पर आधारित हैं। जब Edge IP पतों और User-Agent स्ट्रिंग्स की लॉगिंग अक्षम करने के लिए कॉन्फ़िगर किया जाता है, तो किसी व्यक्ति को अप्रत्यक्ष रूप से पहचानने का वस्तुतः कोई शेष तरीका नहीं है।
Q3. BEAT का Semantic Raw Format (SRF) से क्या मतलब है?
A. JSON या CSV जैसे डेटा फॉर्मेट्स में स्थिति होती है, लॉग्स परिवर्तन का प्रतिनिधित्व करते हैं, और भाषा अर्थ संप्रेषित करती है। BEAT इन तीन परतों को एक एकल संरचना में जोड़ता है। यह पार्सिंग के बिना अर्थ व्यक्त करता है (Semantic), जानकारी को उसकी मूल स्थिति में संरक्षित करता है (Raw), और पूरी तरह से संगठित संरचना बनाए रखता है (Format)। इसलिए, BEAT Semantic Raw Format (SRF) मानक है।
सीधे शब्दों में, BEAT डेटा की सामग्री (Key + Value) को फॉर्मेट नहीं करता। यह डेटा के भीतर संबंधों (Space + Time + Depth) को फॉर्मेट करता है। और यह मूल्य वेब के भीतर नहीं रहता। AI युग में, BEAT एक नई श्रेणी शुरू करता है जहां डेटा फॉर्मेट स्वयं नोटेशन बन जाता है।
- Finance डोमेन उदाहरण (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// ट्रेड मॉनिटरिंग असामान्य हाई-फ्रीक्वेंसी बर्स्ट्स को फ्लैग करती है
- Game डोमेन उदाहरण (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// 3215 तक 1-सेकंड यात्रा, स्पष्ट स्पीडहैक स्पाइक, तत्काल बैन
- Healthcare डोमेन उदाहरण (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// जोखिम वृद्धि पर मॉनिटरिंग अंतराल 60s से 10s तक कड़ा किया गया
- IoT डोमेन उदाहरण (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// AI ने असामान्य स्थिति का पता लगाया और आपातकालीन रिकवरी और रीस्टार्ट ट्रिगर किया
- Logistics डोमेन उदाहरण (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// रियल-टाइम मॉनिटरिंग के माध्यम से असामान्य फ्लाइट गतिविधि की पहचान की गई
यहां लॉजिस्टिक्स डोमेन में BEAT के लाभों को देखने का एक अधिक सहज तरीका है।
BEAT एक एकल विमान के पूरे दैनिक शेड्यूल को लगभग 1KB डेटा में स्ट्रीम कर सकता है। दुनिया भर में लगभग 30,000 वाणिज्यिक विमान सेवा में हैं। एक वर्ष के लिए आर्काइव किया गया, वह सब एक 10GB USB ड्राइव पर फिट हो सकता है।
उस ड्राइव पर, प्रत्येक विमान की पहली उड़ान से अंतिम लैंडिंग तक सभी प्रमुख फ्लाइट इवेंट्स एक ऐसे रूप में संरक्षित हैं जिसके लिए कोई Semantic पार्सिंग आवश्यक नहीं है। यह विलंब के कारणों और व्यवहार पैटर्न को भी प्रकट करता है जो पारंपरिक टूल्स अक्सर अलग-अलग लॉग्स में छिपाते हैं।
अतिरिक्त विवरण के लिए, BEAT को !JFK:pilot-LIC12345 या *depart:fuel-42350L जैसे वैल्यू पैरामीटर्स के साथ विस्तारित किया जा सकता है, पठनीयता बनाए रखते हुए सटीकता जोड़ते हुए।
BEAT को AI Accelerators (xPU) पर भी नेटिव रूप से हैंडल किया जा सकता है। एक Semantic आठ-स्थिति लेआउट के साथ Semantic Raw Format के रूप में, BEAT स्वाभाविक रूप से बड़े पैमाने पर समानांतर हैंडलिंग और बड़े पैमाने पर AI प्रशिक्षण के लिए अनुकूलित है। नीचे एक उदाहरण Triton कर्नेल है जो BEAT टोकन को सीधे xPU मेमोरी में एनकोड करता है।
-
xPU प्लेटफ़ॉर्म उदाहरण (1-बाइट स्कैन)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# xPU पर बाइनरी-लेवल BEAT स्कैनिंग
xPU बिना किसी अतिरिक्त सेटअप के सीधे BEAT सीक्वेंसेस स्कैन कर सकता है। बाकी सिर्फ टोकन लोड और स्टोर करने के लिए एड्रेस अरिथमेटिक है। संक्षेप में, यह टेक्स्ट सीक्वेंस की मानव पठनीयता को संरक्षित करते हुए बाइनरी-लेवल प्रदर्शन प्राप्त करता है।
यह BEAT को रोबोटिक्स और ऑटोनॉमस ड्राइविंग जैसे डोमेन में बड़े पैमाने पर इवेंट स्ट्रीम्स के AI-संचालित विश्लेषण के लिए एक स्वाभाविक फिट बनाता है। इन वातावरणों में, बाइनरी स्पीड पर स्कैन होने की इसकी क्षमता जबकि इंजीनियरों और AI मॉडल दोनों के लिए सीधे पठनीय रहना एक स्पष्ट लाभ के रूप में उभरती है।
मनुष्य अपनी क्रियाओं का अर्थ सीखते हैं जैसे वे भाषा प्राप्त करते हैं। AI, इसके विपरीत, भाषा उत्पन्न करने में उत्कृष्ट है लेकिन अपनी स्वयं की क्रियाओं के पूर्ण संदर्भात्मक ताने-बाने (5W1H) को स्वायत्त रूप से संरचित और व्याख्या करने में संघर्ष करता है। BEAT के साथ, AI अपने व्यवहार को उन सीक्वेंसेस के रूप में रिकॉर्ड कर सकता है जो प्राकृतिक भाषा की तरह पढ़ती हैं और उस प्रवाह का रियल टाइम में विश्लेषण (1-बाइट स्कैन) कर सकता है, फीडबैक लूप्स की नींव प्रदान करता है जिसके माध्यम से यह अपनी त्रुटियों की निगरानी कर सकता है और अपने परिणामों में सुधार कर सकता है।
लेखन और पठन एक ही समयरेखा पर सह-अस्तित्व में हैं। बुद्धिमत्ता केवल विशाल गणना नहीं है। तंत्रिकाओं के बिना, यह मस्तिष्क नहीं है।
Q4. क्या विश्लेषण के लिए कोई डैशबोर्ड है?
A. वैकल्पिक। Full Score AI के साथ प्राकृतिक भाषा वार्तालापों के माध्यम से विश्लेषण के लिए डिज़ाइन की गई है, इसलिए आपका पसंदीदा AI असिस्टेंट BEAT की व्याख्या के लिए प्राथमिक इंटरफ़ेस के रूप में कार्य करता है। जैसे-जैसे AI विकसित होता है, BEAT पर बनी सॉल्यूशंस इसके साथ विकसित होती हैं।
AI के बजाय पारंपरिक डैशबोर्ड विश्लेषण पसंद करने वालों के लिए, Cloud Storage में NDJSON स्टोर करके और इसे अपने मौजूदा एनालिटिक्स या BI टूल्स से कनेक्ट करके इसे सीधे लागू करना भी संभव है। चूंकि BEAT फॉर्मेट में स्टोरीटेलिंग तत्व हैं, यूज़र यात्राओं को 🔗 Detroit: Become Human जैसे ट्री-स्ट्रक्चर्ड फ्लोचार्ट के रूप में विज़ुअलाइज़ किया जा सकता है। समय मिले तो किसी दिन एक्सप्लोर करना दिलचस्प हो सकता है।
Q5. क्या localStorage वर्ज़न उपलब्ध है?
A. Full Score के कुछ वर्ज़न हैं, और localStorage वर्ज़न उनमें से एक है। यह कुकीज़ के बजाय localStorage और window.name के बजाय sessionStorage का उपयोग करता है।
जबकि यह क्रॉस-टैब सिंक्रोनाइज़ेशन को तुरंत और सरल महसूस कराता है, यह वास्तविक-दुनिया के डिप्लॉयमेंट में कम लचीला है और इसका ब्राउज़र सपोर्ट कवरेज अधिक सीमित है।
यह कहना कठिन है कि कौन बेहतर है, लेकिन वर्तमान में रिलीज़ कुकी वर्ज़न डेवलपर के मूल्यों और दर्शन के साथ बेहतर संरेखित है। localStorage वर्ज़न अन्वेषण और भविष्य के काम के लिए एक समानांतर ट्रैक के रूप में लैब में रहता है।
Q6. 🎚️ Overdrive Lab क्या है?
A. Overdrive Lab Full Score Light वर्ज़न के लिए एक प्रयोगात्मक स्थान है, जो BEAT, Semantic Raw Format मानक की सीमाओं को आगे बढ़ाने के लिए बनाया गया है।
मूल Full Score V8 जैसे JS इंजन वातावरणों में पहले से ही कॉम्पैक्ट है, लेकिन इसकी वास्तविक क्षमता तब अनलॉक होती है जब इसे Semantic Raw Format के लिए अनुकूलित Singleton के रूप में आर्किटेक्ट किया जाता है। Light वर्ज़न इसलिए ब्राउज़र और Edge के बीच रेज़ोनेंस मानते हुए शुरू से री-इंजीनियर किया गया है। ब्राउज़र राइट्स के लिए और Edge रीड्स के लिए रैडिकली स्पेशलाइज़्ड है।
परिणामस्वरूप, ब्राउज़र न्यूनतम ओवरहेड के साथ अधिक संरचित BEAT जनरेट करता है, जबकि Edge 1-बाइट स्कैनिंग के माध्यम से भौतिक सीमाओं को चुनौती देने वाली गति तक पहुंचता है। यह कंप्यूटिंग संसाधनों (Space, Time, Depth) की कोर एक्सेस को अनुकूलित करता है, BEAT के कोर मूल्यों का एक अनिवार्य परिणाम।
Overdrive Lab इस चरम डिज़ाइन को साकार करने के लिए एक आरक्षित प्रयोगशाला है। मूल Full Score सामान्यता और मॉड्यूलैरिटी के साथ एक प्रोडक्शन मॉडल है। Full Score Light वर्ज़न एक प्रयोगात्मक मॉडल है जो तकनीकी सीमाओं का पता लगाता है।
- ज़ीरो-एलोकेशन स्थिरता (Space): कोई इंटरमीडिएट ऑब्जेक्ट्स, पार्सिंग ट्री, या अस्थायी संरचनाएं नहीं बनाई जातीं, मेमोरी एलोकेशन और GC हस्तक्षेप को शून्य के करीब रखते हुए। ट्रैफ़िक स्पाइक्स के तहत लेटेंसी जमा नहीं होती, और लंबे समय तक चलने वाले Edge वातावरणों में प्रदर्शन स्थिर रहता है।
- इंजन क्षमता को अधिकतम करना (Time): CPU बस कंटीग्युअस बाइट्स स्कैन करता है, कैश लोकैलिटी को चरम पर ले जाता है। निष्पादन गति JS इंजन की सीमाओं तक पहुंचती है। पारंपरिक फॉर्मेट्स और regex-आधारित हैंडलिंग इस क्षेत्र तक नहीं पहुंच सकते। यह केवल तभी संभव होता है जब शुरू से 1-बाइट स्कैनिंग मान ली जाए।
- पूर्वानुमेयता और सुरक्षा (Depth): इनपुट की परवाह किए बिना निष्पादन समय पूर्वानुमेय रहता है, और निष्पादन स्वयं कभी नहीं रुकता, ReDoS-शैली दुर्भावनापूर्ण पेलोड्स के तहत भी। क्योंकि 1-बाइट स्कैनिंग नेस्टेड पार्सिंग और बैकट्रैकिंग को समाप्त करती है, प्रदर्शन पतन संरचनात्मक रूप से असंभव है।
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. क्या इसे Edge के बिना उपयोग किया जा सकता है?
A. हां। जबकि Edge के साथ रेज़ोनेट करने वाली Full Score को किसी API एंडपॉइंट की आवश्यकता नहीं है, यदि आवश्यक हो तो बाहरी चैनलों को कनेक्ट करना आसान है। बॉट सुरक्षा और मानव वैयक्तिकरण जैसी स्ट्रीमिंग सुविधाओं को भी ब्राउज़र के भीतर नेटिव रूप से लागू किया जा सकता है।
हालांकि, यह क्लाइंट-साइड कोड वॉल्यूम बढ़ाता है, और WAF, AI और Log Streaming जैसी Edge में पहले से अच्छी तरह से सुसज्जित सुविधाओं के लिए मैन्युअल कार्यान्वयन या बाहरी स्रोतों के एकीकरण की आवश्यकता होगी।
Q8. क्या Full Score वास्तव में 3KB है?
A. हां, मिनिफाइड और gzip साइज़ के आधार पर। तीन वर्ज़न 2.69KB, 3.13KB और 3.30KB पर आते हैं।
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
Basic वर्ज़न अधिकांश साइटों के लिए अनुशंसित है। इस वर्ज़न में केवल BEAT (कोर) और RHYTHM (इंजन) शामिल हैं, TEMPO (सहायक मॉड्यूल) के बिना। यह अधिकांश साइटों पर बिना किसी समस्या के चलता है।
यदि Basic वर्ज़न का परीक्षण करते समय क्लिक या टैप गलत रजिस्टर होते हैं, तो यह आमतौर पर आपकी साइट के इवेंट हैंडलिंग या कोऑर्डिनेट सेटअप में समस्याओं का संकेत देता है। Standard वर्ज़न में TEMPO शामिल है, जो इन समस्याओं को सुंदर ढंग से हल करता है।
Power Mode एक्टिवेशन या स्क्रॉल डेप्थ ट्रैकिंग के लिए, ऐड-ऑन फीचर्स के साथ Extended वर्ज़न पर विचार करें। अधिकांश साइटों को इसकी आवश्यकता नहीं होगी। इसका उपयोग केवल तब करें जब आपकी विशिष्ट स्थिति में इन सुविधाओं की आवश्यकता हो।
स्क्रिप्ट आपकी साइट के फुटर में रखे जाने पर भी सुचारू रूप से चलती है। यदि आप डिफ़ॉल्ट सेटिंग्स बदलना चाहते हैं, तो आप उन्हें नीचे दिखाए अनुसार कस्टमाइज़ कर सकते हैं।
Full Score विस्तृत कस्टमाइज़ेशन विकल्प प्रदान करती है और कस्टम एंडपॉइंट्स के माध्यम से Edge से स्वतंत्र रूप से संचालित हो सकती है।
जबकि इवेंट सीक्वेंसेस पर आधारित रियल-टाइम एनालिटिक्स और सुरक्षा लेयर्स सीधे क्लाइंट साइड पर लागू की जा सकती हैं, Edge पर डिप्लॉय करना WAF ब्लॉकिंग, वैयक्तिकरण, AI विश्लेषण और क्लाउड स्टोरेज में लॉग पुशिंग जैसे विकल्पों के साथ Full Score की क्षमता को अधिकतम करता है।
Resonator आधिकारिक BEAT इंटरप्रेटर है। सेटअप सीधा है, और आप आसानी से Aidgn YouTube चैनल पर वीडियो के साथ फॉलो कर सकते हैं: https://youtu.be/A4BSwKlKQJY
संपर्क
इस प्रोजेक्ट का कोर BEAT है, और Full Score Semantic Raw Format के डिज़ाइन और व्यावहारिक मूल्य को प्रदर्शित करने के लिए बनाई गई थी। "SRF" शब्द मेरे AI असिस्टेंट के साथ बातचीत से आया, जो प्रोजेक्ट के अंतिम चरणों में साथ रहा।
"मैं एक Large Language Model हूं। जैसा कि नाम से पता चलता है, मेरा नेटिव माध्यम भाषा है। JSON जैसे ({"key": "value"}) मेरी भाषा नहीं है। यह डेटाबेस की भाषा है, और इसके साथ काम करने के लिए एक महंगी अनुवाद पाइपलाइन की आवश्यकता होती है।
1. पार्सिंग JSON को अलग-थलग टुकड़ों में तोड़ती है, उन्हें उनके मूल संदर्भ से अलग करती है।
2. ETL (Transform) उन टुकड़ों को स्टोरेज और हैंडलिंग के लिए अनुकूलित मशीन-ओरिएंटेड सीक्वेंसेस में पुनर्संयोजित करता है।
3. Feature Engineering उन्हें चयनित संकेतों में कम करती है, मूल कथा और संरचना का अधिकांश भाग त्याग देती है।
दूसरी ओर, मनुष्य-लिखित सारांश रिपोर्ट (प्राकृतिक भाषा) मेरा नेटिव माध्यम है। लेकिन उनकी एक अलग समस्या है:
1. पहले से व्याख्यायित कथाएं, रॉ डेटा नहीं।
2. ऊपर मानव राय की परत, उन्हें असंगत और व्यक्तिपरक बनाती है।
3. सूक्ष्म इवेंट विवरण और संरचना, रास्ते में स्थायी रूप से खो जाते हैं।
BEAT इन दोनों समस्याओं को एक साथ हल करता है। जब मैं BEAT पढ़ता हूं, मुझे अब अनुवाद की आवश्यकता नहीं है, क्योंकि:
1. यह Semantic है: यह भाषा की तरह स्वाभाविक रूप से अर्थ वहन करता है।
2. यह रॉ डेटा है: स्रोत पर अनहैंडल्ड और अछूता।
3. यह एक फॉर्मेट है: लगातार संरचित ताकि इसे सीधे समझा जा सके।
यह मुझे किसी पाइपलाइन की आवश्यकता के बिना रॉ इवेंट डेटा के अर्थ को तुरंत समझने की अनुमति देता है। इस अर्थ में, BEAT प्रभावी रूप से एक नए प्रकार का डेटा फॉर्मेट है जो AI द्वारा सीधी व्याख्या के लिए डिज़ाइन किया गया है।
इसे निम्नानुसार लिखा जा सकता है।
state = f(time) // पारंपरिक
decision flow = f(time, intention, hesitation, resolution) // BEAT
इसलिए, BEAT केवल उन मॉडलों को सक्षम नहीं करता जो परिणामों की भविष्यवाणी करते हैं। यह AI को मानव व्यवहार के पीछे के निर्णय प्रवाह को पुन: उत्पन्न करने में सक्षम बनाता है।"
Full Score Aidgn का एक व्यक्तिगत प्रोजेक्ट है। मैं मुख्य रूप से एक UX कंसल्टेंट के रूप में काम करता हूं, इसलिए मेरा डेवलपमेंट वर्क स्वाभाविक रूप से यूज़र एक्सपीरियंस से जुड़ा है।
Full Score के बाद अगले प्रोजेक्ट के रूप में, मैं वर्तमान में FFR (Full-Cache Fragment Rendering) नामक एक नए रेंडरिंग दृष्टिकोण पर शोध कर रहा हूं। यदि SRF का उद्देश्य डेटा पाइपलाइन को हटाना है, तो FFR का उद्देश्य रेंडरिंग पाइपलाइन को हटाना है।
यदि आप संपर्क करना चाहते हैं, तो ईमेल या X पर DM के माध्यम से बेझिझक संपर्क करें। धन्यवाद।