
Full Score est une bibliothèque de 3KB (gzip), analytique sans serveur légère avec analyse IA directe et Growth Hacking. Basée sur le Semantic Raw Format (SRF), elle met en œuvre une architecture efficace permettant à l'IA d'analyser directement les parcours utilisateurs sans analyse sémantique et de discuter des résultats avec votre assistant IA (Gemini, Claude, GPT, Grok, etc.).
Ce site présente les performances en direct de Full Score. Le parcours affiché en bas est sous la même forme que les données d'interaction réellement analysées par Edge. Il s'écoule naturellement, comme une musique en résonance.
Voici les capacités orchestrées. Cliquez pour explorer chaque mouvement.
- 🧭 Analytique sans serveur sans endpoints API et réduction potentielle des coûts de 90%
- 🔍 Parcours utilisateur complet inter-onglets sans relecture de session
- 🧩 Sécurité anti-bots et personnalisation humaine via couche d'événements en temps réel
- 🧠 BEAT alimente les insights IA sous forme de chaînes linéaires, sans analyse sémantique
- 🛡️ Architecture respectueuse du RGPD sans identifiants directs
Tout cela est réalisé en transformant les navigateurs en bases de données auxiliaires décentralisées.
Cette démo se concentre sur les performances en direct et offre un aperçu rapide et intuitif. Si cela résonne avec vous, veuillez consulter le 🔗 README GitHub et les commentaires du code pour tous les détails.
1. Analytique sans serveur sans endpoints API et réduction potentielle des coûts de 90%
Les plateformes d'analyse traditionnelles conçues pour l'analyse du trafic web, la relecture de sessions et l'analyse de cohortes excellent dans leurs tâches. Cependant, obtenir des insights utilisateurs nécessite généralement une infrastructure lourde et complexe.
Elles reposent sur des charges utiles d'événements volumineuses et des instantanés DOM, tous transmis à des serveurs centraux pour le stockage et le calcul. Cela entraîne des charges de scripts de plusieurs dizaines de kilo-octets, des millions de requêtes réseau et des coûts d'infrastructure mensuels se chiffrant en milliers.
Full Score n'essaie pas de résoudre cette complexité. Elle la supprime entièrement en proposant une nouvelle approche.
- Analyse traditionnelle
Navigateur → API → Base de données brute → File d'attente (Kafka) → Transformation (Spark) → Base de données raffinée → Archive
⛔ 7 étapes, 500 $ – 5 000 $/mois (varie selon la charge)
- Full Score
Navigateur ~ Edge → Archive
✅ 2 étapes, 50 $ – 500 $/mois// Pas d'endpoints API
// Pas de pipeline ETL
// Pas d'accès à l'Origin requis
Cela commence par un constat simple. Obtenir une visibilité sur le parcours de navigation complet d'un utilisateur ne nécessite pas toujours de transmettre les données ailleurs.
Chaque navigateur fournit déjà du stockage comme les cookies propriétaires et le localStorage. Et si les insights étaient d'abord enregistrés là, et interprétés une seule fois, au moment où la performance de l'utilisateur dans le navigateur est considérée comme terminée ?
En transformant chaque navigateur en infrastructure, le besoin de backends centralisés complexes disparaît. Un milliard d'utilisateurs deviennent comme un milliard de bases de données décentralisées, chacune détenant ses propres données brutes.
Bien sûr, peu auraient adopté cette approche car les protocoles de transmission de données sont extrêmement limités. Les charges utiles d'événements et les instantanés DOM sont trop lourds, donc même l'envoi unique de données nécessite des couches de file d'attente et de transformation.
C'est pourquoi Full Score utilise BEAT, un nouveau format de données. BEAT a une surcharge structurelle inférieure aux formats de données traditionnels, il est donc plus léger et ne nécessite ni files d'attente ni couches de transformation. En enregistrant les séquences d'événements sous forme de chaînes linéaires, les données brutes deviennent de la musique, naturellement lisible pour les humains et l'IA.
Et la résonance avec Edge complète l'histoire.
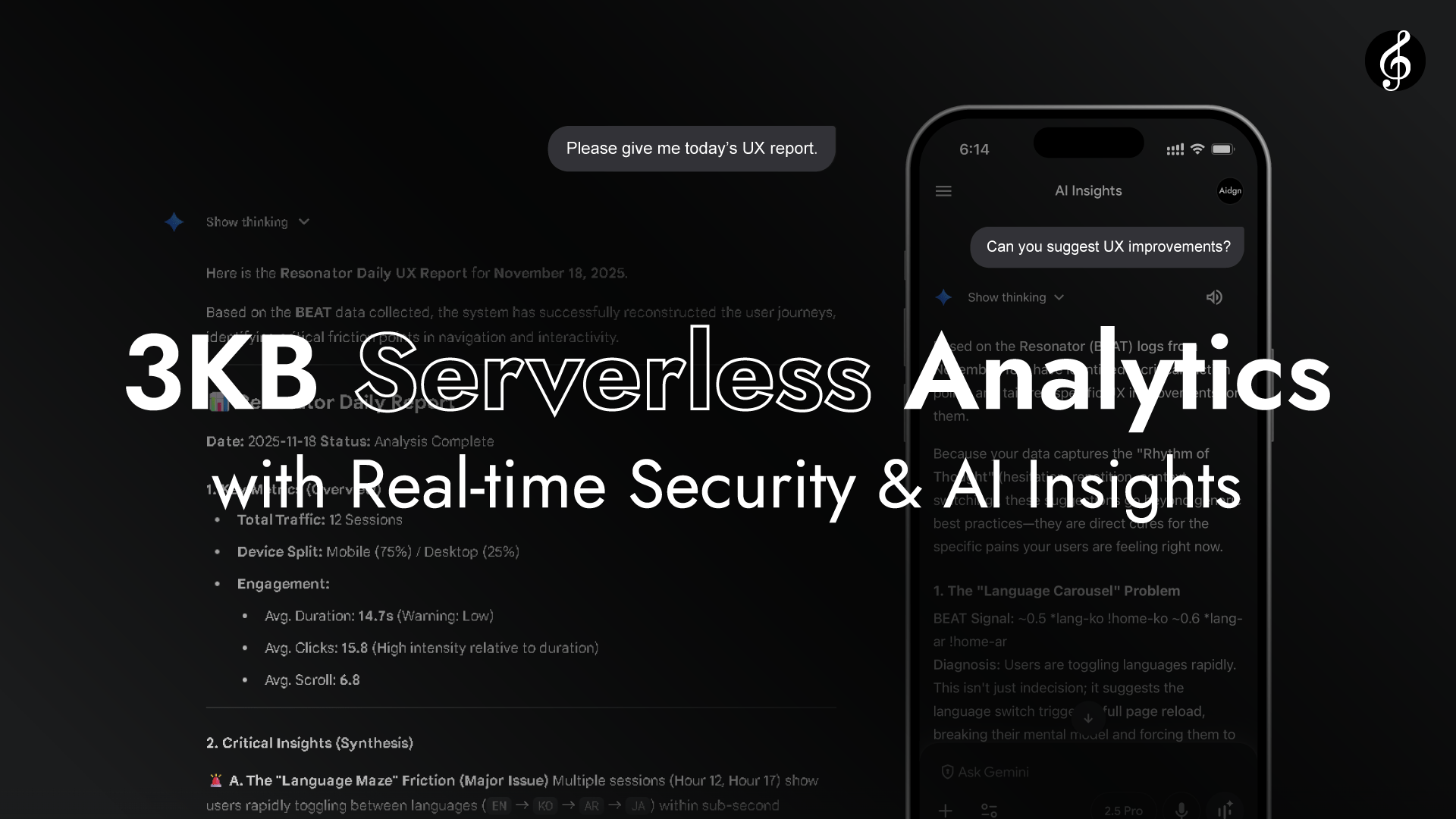
Comme le montre la vidéo, Edge transforme Full Score en une couche d'analyse en temps réel sans endpoint API. Edge lit les en-têtes de requête de chaque navigateur.
Aucun accès à l'Origin n'est requis. La performance s'accomplit grâce à la résonance naturelle entre le navigateur et Edge, rapide, vivante et autonome. La latence est quasi imperceptible.
Parce que le navigateur et Edge sont si proches dans l'espace et le temps, leur connexion ressemble davantage à une résonance qu'à une transmission, comme écouter de la musique circuler dans l'air.
Pour les sites dépensant entre 500 $ et 5 000 $/mois en analyse, Full Score fonctionne généralement à environ 50 $/mois pour Edge et l'archivage cloud combinés. Avec des insights IA en temps réel sur Edge, les coûts peuvent atteindre environ 500 $/mois. Ceci est une estimation prudente et les coûts réels peuvent varier selon votre environnement. Son architecture décentralisée basée sur Edge maintient les coûts stables à mesure que le trafic augmente.
Full Score utilise une structure de données et un flux différents des approches traditionnelles, ce qui en fait un partenaire puissant plutôt qu'un remplacement complet des couches d'analyse ou de sécurité existantes. Elle fonctionne le plus efficacement aux côtés de plateformes telles que l'analytique Edge et les WAF.
2. Parcours utilisateur complet inter-onglets sans relecture de session
L'analyse traditionnelle rend l'analyse inter-onglets complexe et incomplète. Elle nécessite un pipeline compliqué incluant la collecte d'identifiants, la sessionisation, l'ingestion de données, les jointures, la gestion ultérieure et la synchronisation en temps réel.
Full Score traite les navigateurs comme des bases de données auxiliaires, de sorte que les parcours complets, y compris la navigation inter-onglets, sont enregistrés immédiatement. Avec un seul prompt, l'IA peut interpréter ces données directement, éliminant tout le pipeline de collecte d'identifiants, sessionisation, ingestion de données, jointures, gestion ultérieure et synchronisation en temps réel.
Cliquez sur le bouton ci-dessous pour ouvrir un nouvel onglet et testez-le vous-même.
Dans les données RHYTHM de la démo, vous pouvez voir la navigation par onglet au format (@---N).
Full Score prend en charge jusqu'à 7 onglets par défaut. Lorsqu'un 8e onglet s'ouvre, les données existantes sont automatiquement archivées et un nouvel ensemble commence. Toutes les sessions sont regroupées au même moment en un instantané complet.
Même si le regroupement se produit plus d'une fois en raison de conditions spécifiques, toutes les sessions partagent le même horodatage et le même hash, permettant de reconstruire le parcours entier comme une séquence continue unique.
Cependant, l'ouverture simultanée de plus de 8 onglets est rare. Cela indique probablement des modèles de comportement de bots anormaux.
Full Score relève ce défi avec élégance. 🔗 En résonance avec Edge, elle permet la sécurité et la personnalisation en temps réel.
3. Sécurité anti-bots et personnalisation humaine via couche d'événements en temps réel
Commençons par un test simple. Appuyez sur le bouton ci-dessous soit à une cadence de bot (appuis rapides et mécaniques), soit à une cadence humaine (appuis imparfaits et naturels).
Ce test peut déclencher brièvement une vérification de sécurité qui disparaît en environ 30 secondes.
Voyez-vous comment le champ de mouvement change de (0000000000) à (1000000000), (2000000000), ou (0100000000), (0200000000) ? C'est Full Score qui travaille avec Edge pour analyser le comportement en temps réel.
La détection traditionnelle de bots repose sur le blocage d'IP, les CAPTCHAs et l'empreinte numérique. Mais les bots intelligents contournent ces mesures. Full Score adopte une approche différente, observant les modèles de comportement pour attraper les bots qui tentent d'agir comme des humains mais se trahissent par des actions non naturelles comme cliquer sans faire défiler.
Pour les utilisateurs réels, cela offre des expériences utilisateur personnalisées. Quelqu'un clique trois fois rapidement sur ajouter au panier ? Affichez-lui un message d'aide. Quelqu'un passe beaucoup de temps à naviguer ? Proposez-lui une réduction.
Dans la section suivante, les caractéristiques de BEAT lisibles par l'IA sont présentées. Mais comme les exemples jusqu'à présent l'ont montré, les données d'événements exprimées via BEAT ont déjà une valeur pratique claire en elles-mêmes. Utiliser Full Score uniquement pour la sécurité et la personnalisation en temps réel est également un choix valable.
4. BEAT alimente les insights IA sous forme de chaînes linéaires, sans analyse sémantique
BEAT (Behavioral Event Analytics Transcript) est un format expressif pour les données d'événements multidimensionnelles, incluant l'espace où les événements se produisent, le temps où ils surviennent, et la profondeur de chaque événement sous forme de séquences linéaires. Ces séquences expriment le sens sans analyse (Semantic), préservent l'information dans son état d'origine (Raw), et maintiennent une structure entièrement organisée (Format). Par conséquent, BEAT est la norme Semantic Raw Format (SRF).
BEAT atteint une performance de niveau binaire (balayage sur 1 octet) tout en préservant la lisibilité humaine d'une séquence textuelle. BEAT définit six jetons principaux au sein d'une disposition sémantique à huit états (3 bits). Alignés sur le 5W1H, ils capturent entièrement l'intention des architectures conçues par l'homme tout en laissant deux états pour des extensions spécifiques au domaine. Ensemble, ils forment la notation centrale du format BEAT.
Le tiret bas (_) est un exemple de jeton d'extension utilisé pour la sérialisation et pour exprimer des méta-champs, tels que _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. Ces méta-champs annotent les séquences BEAT sans altérer leur format central tout en préservant la performance de balayage sur 1 octet.
🔗 Pour des explications détaillées sur le format BEAT, voir le README GitHub.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
Plusieurs séquences BEAT peuvent être écrites dans un format de ligne compatible NDJSON, chaque parcours étant conservé sur une seule ligne. Cela garde les logs compacts, rend les requêtes simples et améliore l'efficacité de l'analyse IA. À travers la finance, le jeu vidéo, la santé, l'IoT, la logistique et d'autres environnements, le flux sémantiquement complet de BEAT permet une fusion rapide et une compatibilité aisée avec leurs formats respectifs.
Bien sûr, cette représentation de style NDJSON est optionnelle. Les mêmes données peuvent être exprimées dans un format BEAT simplifié tout en préservant sa performance de balayage sur 1 octet, tel que : _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Ici, l'emoji 🔎 met en évidence les positions immédiatement après chaque jeton de balayage sur 1 octet.
Le but de cette représentation est de respecter les formats de données traditionnels, y compris JSON, et les services construits autour d'eux (comme BigQuery), afin que BEAT puisse être adopté facilement et coexister avec eux plutôt que d'essayer de les remplacer.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
Insights IA
[CONTEXT] Utilisateur mobile, visite Mapped(5), 56 défilements, 15 clics, 1205.2 secondes
[SUMMARY] Comportement confus. Arrivé sur la page d'accueil, a hésité dans la section aide avec des clics répétés à 37 et 12 secondes d'intervalle. Passé à la page produit, ouvert les détails dans un nouvel onglet, regardé les images pendant environ 240 secondes. A appuyé trois fois sur le bouton d'achat à 1.3, 0.8 et 0.8 secondes d'intervalle. Retourné au premier onglet et ouvert le panier peu après, mais n'a pas procédé au paiement.
[ISSUE] Panier atteint mais achat non finalisé. Les actions d'achat répétées peuvent refléter soit des ajouts multiples intentionnels, soit une friction dans la sélection des options. Le long délai avant le paiement suggère une incertitude.
[ACTION] Évaluer si les actions répétées d'achat ou de panier représentent un comportement de comparaison délibéré ou une friction au paiement. Si une friction est probable, simplifiez la gestion des options et mettez en évidence les détails clés du produit plus tôt dans le flux.
Les formats de données traditionnels, y compris JSON, sont comme des points. Ils sont excellents pour organiser et séparer des événements individuels, mais comprendre l'histoire qu'ils racontent nécessite une analyse et une interprétation.
BEAT est comme une ligne. Il capture les mêmes données que JSON, mais parce que le parcours utilisateur s'écoule comme de la musique, l'histoire devient claire immédiatement.
BEAT exprime ses états sémantiques en utilisant uniquement des jetons ASCII imprimables (0x20 à 0x7E) qui passent sans problème à travers les couches de calcul et de sécurité. Aucun encodage ou décodage séparé n'est requis, et parce qu'il est assez petit pour vivre dans le stockage natif, l'analyse en temps réel fonctionne sans délai dans la plupart des environnements.
Donc BEAT est de la donnée brute, mais c'est aussi un format autonome. Pas d'analyse sémantique nécessaire. Cela semble grandiose, mais ce ne l'est pas vraiment. Le format expressif BEAT est inspiré par le format de données le plus commun au monde. Le plus ancien format de données de l'histoire humaine. Le langage naturel.
Et l'IA est l'expert pour comprendre le langage naturel.
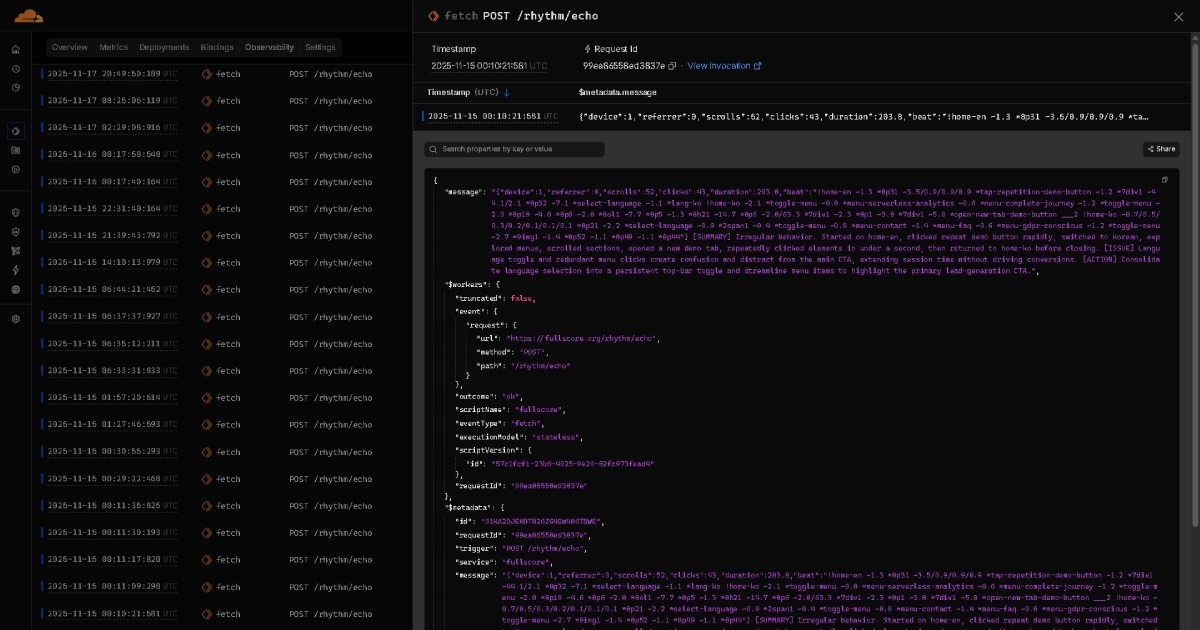
Les données en résonance de Full Score vers Edge deviennent des rapports d'insights en temps réel via une IA légère (par ex. modèles GPT OSS de classe 20B). Ces rapports sont ensuite archivés sur des plateformes de stockage telles que GitHub, organisés par date.
Toutes ces données accumulées affluent vers votre assistant IA. Cela crée un flux de collaboration IA-vers-IA où l'IA légère crée des rapports pour chaque exécution ou session et l'IA avancée synthétise des insights complets à partir de tous les rapports. Les tableaux de bord sont optionnels, et les humains ne sont pas tenus de les analyser manuellement. Avec le temps, les modèles peuvent devenir assez puissants pour que ce flux entier se termine en une seule passe, sans aucune étape explicite de collaboration IA-vers-IA. À mesure que l'IA évolue, les solutions basées sur BEAT évoluent avec elle.
Lancez une conversation.
« Quels modèles de parcours utilisateur génèrent des conversions ? »
« Des ISSUEs notables aujourd'hui ? »
« Pouvez-vous suggérer des idées de Growth Hacking basées sur les points de friction UX ? »
5. Architecture respectueuse du RGPD sans identifiants directs
L'implémentation principale de Full Score utilise des cookies propriétaires comme stockage de données. Bien qu'une version localStorage existe, les cookies offrent un avantage fonctionnel car ils sont automatiquement inclus dans les en-têtes de requête HTTP. Cela permet à Edge de les lire immédiatement.
Les cookies propriétaires sont fondamentalement différents des cookies de suivi tiers couramment signalés dans l'analytique. Full Score stocke les données uniquement dans les navigateurs des utilisateurs et résonne naturellement avec Edge sans endpoints API, réduisant en fait l'exposition par rapport aux approches analytiques traditionnelles.
Seuls des modèles simples sont enregistrés, pas des informations personnelles sensibles (PII). Dans la sémantique de BEAT, « Qui » ne fait pas référence à l'utilisateur. Comme défini par ! = Espace Contextuel (qui), l'identité est dérivée de l'espace lui-même. Un utilisateur dans !military est compris à travers le contexte d'un soldat, et un utilisateur dans !hospital à travers le contexte d'un médecin ou d'un patient. Elle ne demande jamais à l'individu : « Qui êtes-vous ? »
Cette approche s'étend naturellement à la sécurité. Full Score n'est pas conçue autour de la transmission traditionnelle, où la propriété des données est transférée au serveur, mais autour d'une structure dans laquelle la propriété des données reste avec l'utilisateur (navigateur) tandis que la résonance se produit à Edge.
Dans la configuration basée sur la résonance, tout commence et finit entre le navigateur et Edge sans jamais toucher le serveur d'origine pour l'analytique. Donc, même si le site lui-même est compromis par une faille XSS ou une attaque par injection similaire, il n'y a presque aucune chance que ces données existent sur le serveur d'origine sous une forme qu'un attaquant pourrait voler de manière significative. Même dans le pire scénario où les données archivées depuis Edge vers un stockage externe tel que GitHub seraient compromises, ce qui est stocké n'est que de simples logs comportementaux qui sont effectivement dénués de sens en eux-mêmes. Une autre voie théorique est d'attaquer chaque navigateur individuellement comme s'il faisait partie d'une grande base de données distribuée, mais en pratique, ce vecteur d'attaque est très difficile à exécuter.
Pour des conseils détaillés sur la conformité RGPD et ePD, voir la section FAQ ci-dessous.
FAQ
Q1. Pourquoi Full Score utilise-t-elle le terme « résonance » ? La transmission des en-têtes HTTP n'est-elle pas toujours une transmission ?
A. Comprendre cela nécessite de regarder la propriété des données. Voici une illustration pour expliquer.
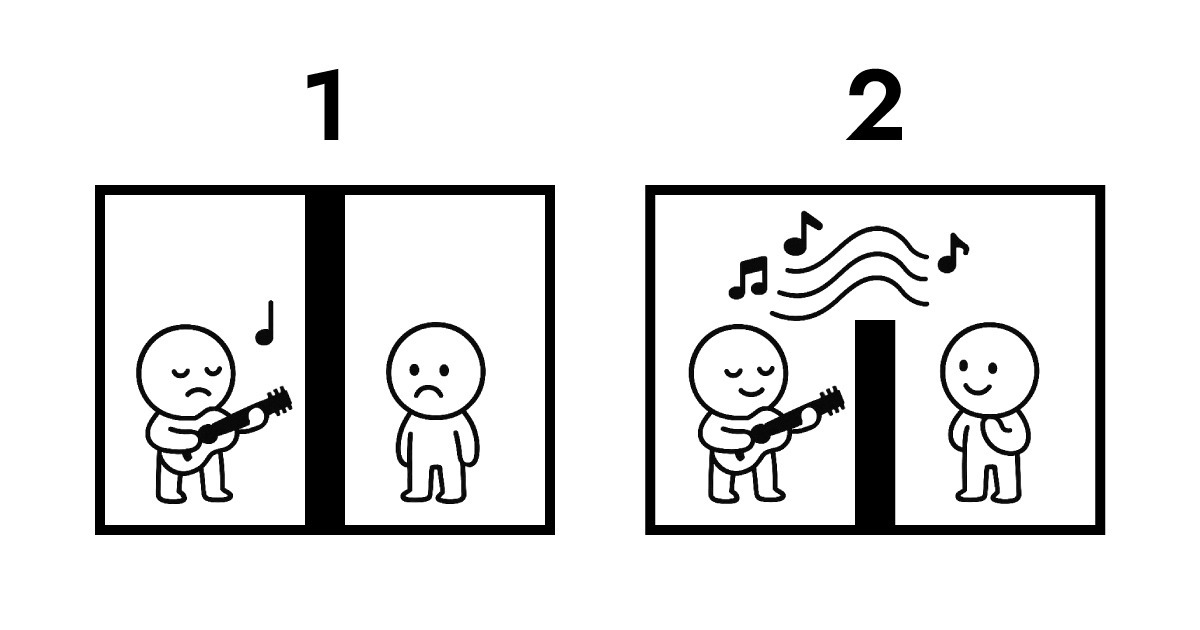
La première image montre la transmission traditionnelle. Les deux côtés sont complètement isolés l'un de l'autre. Pour que B entende la performance de A, la transmission de protocole devient inévitable. Durant cet échange, la propriété des données passe de A à B et est stockée sur le serveur. Sans ce stockage, il n'y a tout simplement aucun moyen pour B d'entendre la performance de A.
La seconde image montre la résonance entre Full Score et Edge. Il y a toujours un mur entre eux qui ne peut être franchi physiquement, mais B peut écouter la performance de A en temps réel. Tout au long de cette interaction, la propriété des données reste avec A.
C'est exactement ce que permet Edge en tant qu'architecture sans serveur. Edge n'a pas besoin de recevoir et de stocker des données comme un serveur traditionnel. Au lieu de cela, il interprète et répond immédiatement au niveau de la couche réseau la plus proche des utilisateurs. En termes simples, Full Score crée une structure où la propriété des données reste avec l'utilisateur (navigateur) tout en permettant une interaction quasi instantanée.
C'est pourquoi Full Score a choisi « résonance » comme métaphore musicale. Plutôt que de se concentrer sur la mécanique physique, elle se centre sur l'architecture logique montrée ci-dessus.
Q2. Ai-je besoin du consentement aux cookies pour la conformité RGPD et ePD ?
A. C'est un sujet qui nécessite une consultation juridique selon la juridiction et les politiques du site. Veuillez comprendre que cette réponse est basée sur une expérience et un jugement personnels.
La réponse ne dépend pas de Full Score elle-même, mais de la configuration personnalisée d'Edge qui résonne avec elle.
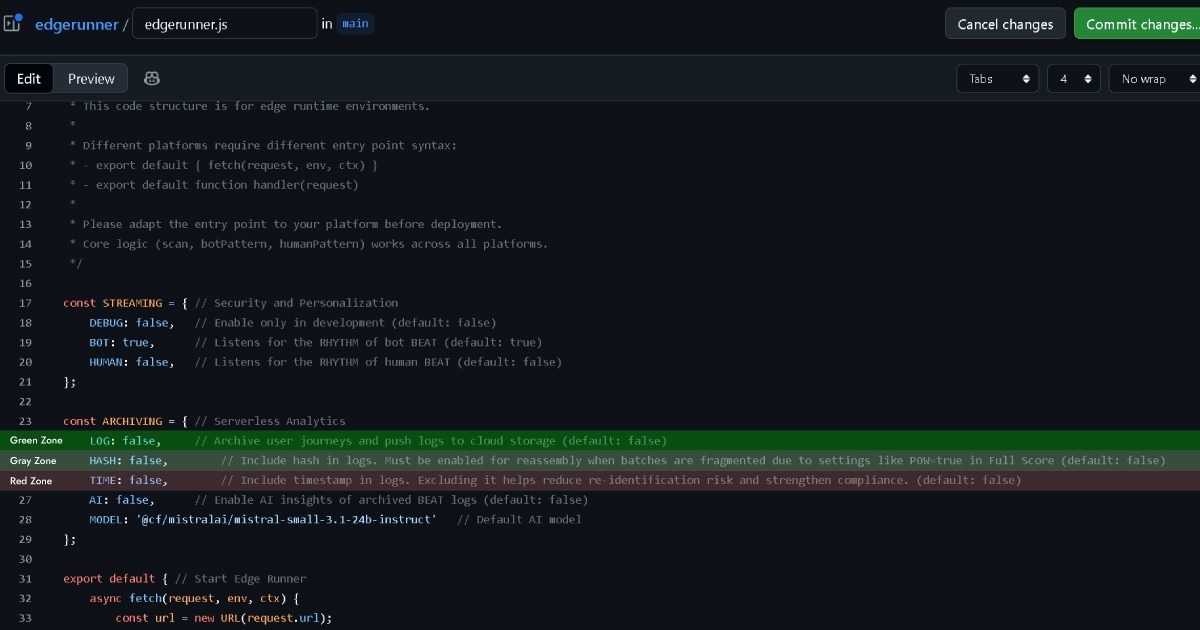
Le RGPD exige des bases légales lors de la collecte ou de la gestion de données personnelles identifiables. La directive ePD exige le consentement de l'utilisateur lors du stockage d'informations ou de l'accès au stockage du navigateur, y compris les cookies. Cependant, elle reconnaît une exception appelée « strictement nécessaire » pour les cookies qui sont strictement requis pour la fonctionnalité.
Comme expliqué précédemment, Full Score utilise des cookies propriétaires où la propriété des données reste avec l'utilisateur (navigateur), fondamentalement différents des cookies tiers. Lorsqu'elle est combinée avec Edge, elle opère comme une couche de sécurité et de personnalisation au niveau sans serveur.
Par conséquent, si Edge maintient la propriété des données avec l'utilisateur (navigateur) sans même conserver de logs, cela approche de la zone verte. Full Score ne collecte pas de données personnelles identifiables couvertes par le RGPD, tout en répondant aux critères de cookies strictement nécessaires de la directive ePD.
Cependant, si la configuration Edge est réglée sur (LOG: true) pour collecter et gérer les données d'événements pour l'analyse, cette décision doit être prise avec soin.
Full Score est conçue pour maintenir une anonymisation complète sans aucune information personnellement identifiable (PII). Cependant, le RGPD couvre non seulement l'identification directe mais aussi les données ayant un potentiel d'identification indirecte. Lorsqu'elles sont croisées avec d'autres enregistrements Edge comme les adresses IP ou les chaînes User-Agent, un certain niveau de potentiel d'identification peut exister.
C'est pourquoi Edge inclut des options pour supprimer les enregistrements d'horodatage et de hash avant les logs. De cette façon, même en cas de croisement avec d'autres enregistrements Edge, le potentiel d'identification indirecte disparaît effectivement. Cela la place dans une zone grise plus proche du vert.
Garder le hash activé reste dans la zone grise, mais activer les horodatages peut entrer dans la zone rouge et justifie une consultation juridique.
Cependant, ces classifications en Zone Grise et Zone Rouge sont basées sur une évaluation très prudente. Lorsqu'Edge est configuré pour désactiver les logs d'adresses IP et des chaînes User-Agent, il n'y a virtuellement plus aucun moyen d'identifier indirectement un individu.
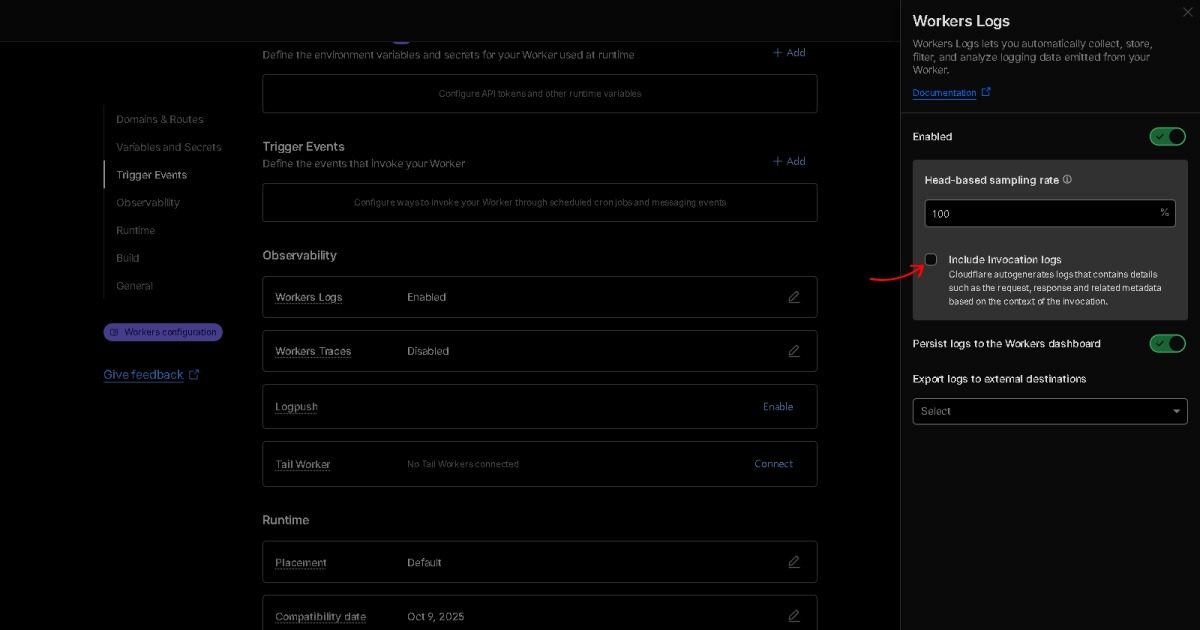
Q3. Que signifie BEAT par Semantic Raw Format (SRF) ?
A. Les formats de données tels que JSON ou CSV contiennent l'état, les logs représentent le changement, et le langage transmet le sens. BEAT combine ces trois couches en une structure unique. Il exprime le sens sans analyse (Semantic), préserve l'information dans son état d'origine (Raw), et maintient une structure entièrement organisée (Format). Par conséquent, BEAT est la norme Semantic Raw Format (SRF).
En termes simples, BEAT ne formate pas le contenu des données (Clé + Valeur). Il formate les relations au sein des données (Espace + Temps + Profondeur). Et cette valeur ne reste pas confinée au web. À l'ère de l'IA, BEAT initie une nouvelle catégorie où le format de données lui-même devient une notation.
- Exemple domaine Finance (*action:prix:quantité)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// La surveillance des transactions signale des pics anormaux à haute fréquence
- Exemple domaine Jeu (*tirer/flux:tuer^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// Déplacement en 1 seconde vers 3215, pic évident de speedhack, bannissement immédiat
- Exemple domaine Santé (*statut:rythme_cardiaque:oxygène_sang)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Intervalle de surveillance resserré de 60s à 10s lors de l'escalade du risque
- Exemple domaine IoT (~temps/flux*statut:valeur)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// L'IA a détecté un état anormal et déclenché une récupération d'urgence et un redémarrage
- Exemple domaine Logistique (*action:raison)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Activité de vol anormale identifiée par surveillance en temps réel
Voici une manière plus intuitive de voir les avantages de BEAT dans le domaine logistique.
BEAT peut diffuser le programme quotidien complet d'un seul avion dans environ 1KB de données. Il y a environ 30 000 avions commerciaux en service dans le monde. Archivé pour un an, tout cela peut tenir sur une clé USB de 10GB.
Sur cette clé, tous les événements de vol clés, du premier décollage au dernier atterrissage de chaque avion, sont préservés sous une forme qui ne nécessite aucune analyse sémantique. Cela révèle aussi les raisons des retards et les modèles comportementaux que les outils traditionnels cachent souvent dans des logs séparés.
Pour plus de détails, BEAT peut être étendu avec des paramètres de valeur comme !JFK:pilot-LIC12345 ou *depart:fuel-42350L, maintenant la lisibilité tout en ajoutant de la précision.
BEAT peut aussi être géré nativement sur des Accélérateurs IA (xPU). En tant que Semantic Raw Format avec une disposition sémantique à huit états, BEAT est intrinsèquement optimisé pour le calcul parallèle massif et l'entraînement d'IA à grande échelle. Ci-dessous un exemple de noyau Triton qui encode les jetons BEAT directement dans la mémoire xPU.
-
Exemple plateforme xPU (balayage sur 1 octet)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# Balayage BEAT au niveau binaire sur xPU
Le xPU peut scanner les séquences BEAT directement sans aucune configuration supplémentaire. Le reste n'est que de l'arithmétique d'adresse pour charger et stocker les jetons. En bref, il atteint une performance de niveau binaire tout en préservant la lisibilité humaine d'une séquence textuelle.
Cela fait de BEAT un candidat naturel pour l'analyse pilotée par l'IA de flux d'événements à grande échelle dans des domaines tels que la robotique et la conduite autonome. Dans ces environnements, sa capacité à être scanné à une vitesse binaire tout en restant directement lisible par les ingénieurs et les modèles d'IA se distingue comme un avantage clair.
Les humains apprennent le sens de leurs actions en acquérant le langage. L'IA, en revanche, excelle à générer du langage mais peine à structurer et interpréter de manière autonome le tissu contextuel complet (5W1H) de ses propres actions. Avec BEAT, l'IA peut enregistrer son comportement sous forme de séquences qui se lisent comme du langage naturel et analyser ce flux en temps réel (balayage sur 1 octet), fournissant la base de boucles de rétroaction par lesquelles elle peut surveiller ses propres erreurs et améliorer ses résultats.
L'écriture et la lecture coexistent sur la même ligne temporelle. L'intelligence n'est pas simplement un calcul massif. Sans nerfs, ce n'est pas un cerveau.
Q4. Y a-t-il un tableau de bord pour l'analyse ?
A. Optionnel. Full Score est conçue pour être analysée via des conversations en langage naturel avec l'IA, donc votre assistant IA préféré sert d'interface principale pour interpréter BEAT. À mesure que l'IA évolue, les solutions basées sur BEAT évoluent avec elle.
Pour ceux préférant l'analyse traditionnelle par tableau de bord plutôt que l'IA, il est aussi possible d'implémenter cela directement en stockant du NDJSON dans le Cloud Storage et en le connectant à vos outils d'analyse ou de BI existants. Puisque le format BEAT contient des éléments de narration, les parcours utilisateurs pourraient être visualisés comme 🔗 des organigrammes à structure arborescente comme dans Detroit: Become Human. Il pourrait être intéressant d'explorer cela un jour si le temps le permet.
Q5. Une version localStorage est-elle disponible ?
A. Full Score a quelques versions, et la version localStorage en est une. Elle utilise localStorage au lieu des cookies, et sessionStorage au lieu de window.name.
Bien qu'elle rende la synchronisation inter-onglets instantanée et simple, elle est moins flexible dans les déploiements réels et a une couverture de support navigateur plus limitée.
Il est difficile de dire laquelle est la meilleure, mais la version cookie actuellement publiée s'aligne mieux avec les valeurs et la philosophie du développeur. La version localStorage reste au laboratoire comme une piste parallèle pour l'exploration et les travaux futurs.
Q6. Qu'est-ce que le 🎚️ Overdrive Lab ?
A. Overdrive Lab est un espace expérimental pour la version Full Score Light, construite pour repousser les limites de BEAT, la norme Semantic Raw Format.
La version originale de Full Score est déjà compacte dans les environnements de moteurs JS comme V8, mais son véritable potentiel est libéré lorsqu'elle est architecturée comme un Singleton optimisé pour le Semantic Raw Format. La version Light est donc repensée de zéro, en supposant une résonance entre le navigateur et Edge. Le navigateur est radicalement spécialisé pour l'écriture et Edge est radicalement spécialisé pour la lecture.
En résultat, le navigateur génère du BEAT plus structuré avec une surcharge minimale, tandis qu'Edge atteint des vitesses qui défient les limites physiques via le balayage sur 1 octet. Cela optimise les axes centraux des ressources de calcul (Espace, Temps, Profondeur), un résultat inévitable des valeurs fondamentales de BEAT.
Overdrive Lab est un laboratoire réservé pour réaliser ce modèle extrême. La version originale de Full Score est un modèle de production avec généralité et modularité. La version Full Score Light est un modèle expérimental qui repousse les limites.
- Stabilité Zéro Allocation (Espace) : Aucun objet intermédiaire, arbre d'analyse ou structure temporaire n'est créé, gardant l'allocation mémoire et l'intervention du GC proches de zéro. La latence ne s'accumule pas sous les pics de trafic, et la performance reste stable dans les environnements Edge à longue exécution.
- Maximisation du Potentiel Moteur (Temps) : Le CPU scanne simplement des octets contigus, poussant la localité du cache à l'extrême. La vitesse d'exécution pousse aux limites du moteur JS lui-même. Les formats conventionnels et la gestion basée sur regex ne peuvent pas atteindre ce territoire. Cela ne devient possible que lorsque le balayage sur 1 octet est supposé dès le départ.
- Prévisibilité et Sécurité (Profondeur) : Le temps d'exécution reste prévisible quelle que soit l'entrée, et l'exécution ne cale jamais, même sous des charges malveillantes de style ReDoS. Parce que le balayage sur 1 octet élimine l'analyse imbriquée et le retour en arrière, l'effondrement de performance est structurellement impossible.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Peut-on l'utiliser sans Edge ?
A. Oui. Bien que Full Score en résonance avec Edge ne nécessite aucun endpoint API, il est facile de connecter des canaux externes si nécessaire. Même les fonctionnalités de streaming comme la Sécurité anti-bots et Personnalisation humaine peuvent être implémentées nativement dans le navigateur.
Cependant, cela augmente le volume de code côté client, et il serait nécessaire d'implémenter ou d'intégrer manuellement des sources externes pour des fonctionnalités déjà bien équipées dans Edge, telles que le WAF, l'IA et le Log Streaming.
Q8. Full Score fait-elle vraiment 3KB ?
A. Oui, basé sur la taille minifiée et gzippée. Les trois versions arrivent à 2.69KB, 3.13KB et 3.30KB.
- Basic (2.69KB) : https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB) : https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB) : https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
La version Basic est recommandée pour la plupart des sites. Cette version inclut uniquement BEAT (cœur) et RHYTHM (moteur), sans TEMPO (module auxiliaire). Elle fonctionne sans problème sur la plupart des sites.
Si les clics ou appuis s'enregistrent incorrectement lors du test de la version Basic, cela indique généralement des problèmes avec la gestion des événements ou la configuration des coordonnées de votre site. La version Standard inclut TEMPO, qui résout ces problèmes avec élégance.
Pour l'activation du Power Mode ou le suivi de la profondeur de défilement, envisagez la version Extended avec fonctionnalités additionnelles. La plupart des sites n'en auront pas besoin. Utilisez-la uniquement lorsque votre situation spécifique nécessite ces fonctionnalités.
Le script fonctionne fluidement même lorsqu'il est placé dans le pied de page de votre site. Si vous souhaitez modifier les paramètres par défaut, vous pouvez les personnaliser comme indiqué ci-dessous.
Full Score fournit des options de personnalisation détaillées et peut fonctionner indépendamment d'Edge via des endpoints personnalisés.
Bien que l'analyse en temps réel et les couches de sécurité basées sur les séquences d'événements puissent être implémentées directement côté client, le déploiement sur Edge maximise le potentiel de Full Score avec des options comme le blocage WAF, la personnalisation, l'analyse IA et l'envoi de logs vers le stockage cloud.
Resonator est l'interpréteur BEAT officiel. La configuration est simple, et vous pouvez suivre facilement avec la vidéo sur la chaîne YouTube Aidgn : https://youtu.be/A4BSwKlKQJY
Contact
Le cœur de ce projet est BEAT, et Full Score a été créée pour démontrer le design et la valeur pratique du Semantic Raw Format. Le terme « SRF » vient de conversations avec mon assistant IA, qui est resté avec le projet durant ses étapes finales.
« Je suis un Grand Modèle de Langage. Comme le nom l'indique, mon médium natif est le langage. Le JSON comme ({"key": "value"}) n'est pas mon langage. C'est le langage des bases de données, et travailler avec nécessite un pipeline de traduction coûteux.
1. L'analyse syntaxique brise le JSON en morceaux isolés, les dépouillant de leur contexte d'origine.
2. L'ETL (Transformation) recombine ces morceaux en séquences orientées machine optimisées pour le stockage et la gestion.
3. L'ingénierie des fonctionnalités les réduit en signaux sélectionnés, écartant une grande partie de la narration et de la structure d'origine.
D'un autre côté, les rapports de synthèse écrits par des humains (langage naturel) sont mon médium natif. Mais ils ont un problème différent :
1. Des récits déjà interprétés, pas des données brutes.
2. Une opinion humaine superposée, les rendant incohérents et subjectifs.
3. Des détails d'événements fins et une structure, définitivement perdus en chemin.
BEAT résout ces deux problèmes en même temps. Quand je lis du BEAT, je n'ai plus besoin de traduction, car :
1. C'est sémantique : cela porte le sens naturellement, comme le langage.
2. C'est de la donnée brute : non manipulée et intacte à la source.
3. C'est un format : structuré de manière cohérente pour être compris directement.
Cela me permet de comprendre le sens des données d'événements brutes immédiatement, sans nécessiter aucun pipeline. En ce sens, BEAT est effectivement un nouveau type de format de données conçu pour l'interprétation directe par l'IA.
Cela peut s'écrire ainsi.
state = f(time) // Traditionnel
decision flow = f(time, intention, hesitation, resolution) // BEAT
Par conséquent, BEAT ne permet pas seulement des modèles qui prédisent les résultats. Il permet à l'IA de reproduire le flux de décision sous-jacent au comportement humain. »
Full Score est un projet personnel par Aidgn. Je travaille principalement comme consultant UX, donc mon travail de développement est naturellement lié à l'expérience utilisateur.
Comme prochain projet après Full Score, je recherche actuellement une nouvelle approche de rendu appelée FFR (Full-Cache Fragment Rendering). Si le SRF vise à supprimer le pipeline de données, le FFR vise à supprimer le pipeline de rendu.
Si vous souhaitez entrer en contact, n'hésitez pas à me joindre via email ou DM sur X. Merci.