
Full Score یک کتابخانه 3KB (gzip) است، یک تحلیل بدون سرور سبک با تحلیل مستقیم هوش مصنوعی و هک رشد. بر پایه Semantic Raw Format (SRF)، معماری کارآمدی پیادهسازی میکند که به هوش مصنوعی امکان تحلیل مستقیم سفرهای کاربر بدون پارسینگ معنایی و بحث در مورد نتایج با دستیار هوش مصنوعی شما (Gemini, Claude, GPT, Grok و غیره) را میدهد.
این سایت عملکرد زنده Full Score را نمایش میدهد. سفری که در پایین صفحه ظاهر میشود، همان فرمت دادههای تعاملی است که Edge واقعاً تحلیل میکند. مثل موسیقی در طنین، طبیعی جریان مییابد.
اینها قابلیتهای ارکستر شده هستند. برای کاوش هر موومان کلیک کنید.
- 🧭 تحلیل بدون سرور: بدون API Endpoint و پتانسیل کاهش ۹۰٪ هزینه
- 🔍 سفر کامل کاربر در چند تب: بدون Session Replay
- 🧩 امنیت ربات و شخصیسازی انسانی: از طریق لایه رویداد بلادرنگ
- 🧠 BEAT به بینشهای هوش مصنوعی جریان مییابد: به صورت رشتههای خطی، بدون پارسینگ معنایی
- 🛡️ معماری آگاه به GDPR: با شناسههای مستقیم صفر
همه اینها با تبدیل مرورگرها به پایگاههای داده کمکی غیرمتمرکز محقق میشود.
این دمو بر عملکرد زنده تمرکز دارد و مروری سریع و شهودی ارائه میدهد. اگر با شما طنینانداز شد، لطفاً به 🔗 README گیتهاب و کامنتهای کد برای جزئیات فنی کامل مراجعه کنید.
1. تحلیل بدون سرور: بدون API Endpoint و پتانسیل کاهش ۹۰٪ هزینه
پلتفرمهای تحلیل سنتی که برای تحلیل ترافیک وب، Session Replay و ردیابی کوهورت ساخته شدهاند، در وظایف خود عالی هستند. اما کسب بینش کاربر معمولاً نیاز به زیرساخت سنگین و پیچیده دارد.
آنها به پیلودهای رویداد حجیم و اسنپشاتهای DOM متکی هستند که همه به سرورهای متمرکز برای ذخیرهسازی و محاسبه منتقل میشوند. نتیجه آن پیلودهای اسکریپت دهها کیلوبایتی، میلیونها درخواست شبکه و هزینههای ماهانه زیرساخت هزاران دلاری است.
Full Score سعی نمیکند این پیچیدگی را حل کند. کاملاً حذفش میکند و رویکرد جدیدی پیشنهاد میدهد.
- تحلیل سنتی
مرورگر → API → پایگاه داده خام → Queue (Kafka) → Transform (Spark) → پایگاه داده تصفیهشده → آرشیو
⛔ ۷ مرحله، $۵۰۰ – $۵,۰۰۰/ماه (بسته به پیلود)
- Full Score
مرورگر ~ Edge → آرشیو
✅ ۲ مرحله، $۵۰ – $۵۰۰/ماه// بدون نیاز به API Endpoint
// بدون نیاز به پایپلاین ETL
// بدون نیاز به دسترسی Origin
با یک درک ساده شروع میشود. کسب بینش از سفر کامل مرور کاربر همیشه نیازی به انتقال داده به جای دیگر ندارد.
هر مرورگر از قبل فضای ذخیرهسازی مثل کوکیهای فرستپارتی و localStorage دارد. اگر بینشها ابتدا آنجا ثبت شوند و فقط یک بار، در لحظهای که عملکرد کاربر در مرورگر کامل تلقی میشود، تفسیر شوند چه؟
با تبدیل هر مرورگر به زیرساخت، نیاز به بکاندهای پیچیده و متمرکز از بین میرود. یک میلیارد کاربر مثل یک میلیارد پایگاه داده غیرمتمرکز میشوند که هر کدام دادههای خام خود را نگه میدارند.
البته، تعداد کمی این رویکرد را پذیرفتهاند چون پروتکلهای انتقال داده بسیار محدود هستند. پیلودهای رویداد و اسنپشاتهای DOM خیلی سنگین هستند، پس حتی ارسال یکباره داده هم هنوز نیاز به لایههای Queue و Transform دارد.
به همین دلیل Full Score از BEAT، یک فرمت داده جدید استفاده میکند. BEAT سربار ساختاری کمتری نسبت به فرمتهای داده سنتی دارد، پس سبکتر است و نیاز به Queue یا لایههای Transform ندارد. با ثبت توالی رویدادها به صورت رشتههای خطی، دادههای خام به موسیقی تبدیل میشوند که هم انسانها و هم هوش مصنوعی به طور طبیعی میتوانند بخوانند.
و طنین با Edge Computing داستان را کامل میکند.
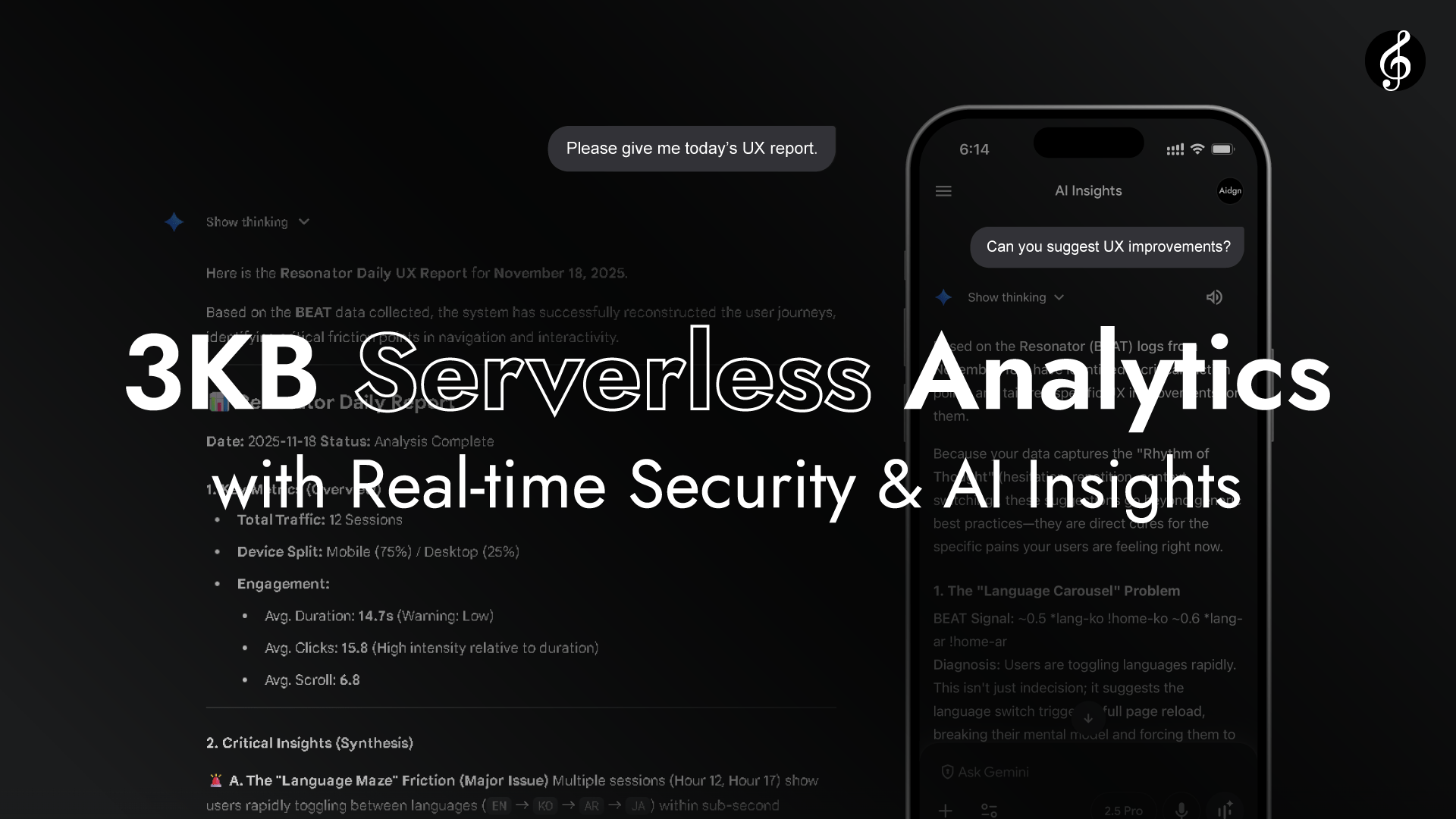
همانطور که ویدیو نشان میدهد، Edge تحول Full Score را به لایه تحلیل بلادرنگ بدون نیاز به API Endpoint ممکن میسازد. Edge هدرهای درخواست از هر مرورگر را میخواند.
دسترسی به Origin نیازی نیست. عملکرد از طریق طنین طبیعی بین مرورگر و Edge کامل میشود. سریع، زنده و خودکفا. تأخیر به طور نامحسوسی کم است.
چون مرورگر و Edge از نظر مکانی و زمانی خیلی نزدیک هستند، اتصالشان بیشتر شبیه طنین است تا انتقال. مثل گوش دادن به موسیقی که در هوا جریان دارد.
برای سایتهایی که ماهانه $۵۰۰ تا $۵,۰۰۰ برای تحلیل خرج میکنند، Full Score معمولاً با حدود $۵۰/ماه برای Edge Computing و آرشیو ابری اجرا میشود. با بینشهای بلادرنگ هوش مصنوعی در Edge، هزینهها میتوانند تا حدود $۵۰۰/ماه افزایش یابند. این تخمین محافظهکارانه است و هزینههای واقعی بسته به محیط شما ممکن است متفاوت باشد. طراحی غیرمتمرکز مبتنی بر Edge، هزینهها را با رشد ترافیک پایدار نگه میدارد.
Full Score از ساختار داده و جریان متفاوتی نسبت به رویکردهای سنتی استفاده میکند و آن را به شریک قدرتمندی تبدیل میکند نه جایگزین کامل لایههای تحلیل یا امنیتی موجود. در کنار پلتفرمهایی مثل تحلیل Edge و WAF بهترین عملکرد را دارد.
2. سفر کامل کاربر در چند تب: بدون Session Replay
تحلیل سنتی، تحلیل چند تب را پیچیده و ناقص میکند. نیاز به پایپلاین پیچیده شامل جمعآوری شناسه، سشنسازی، جذب داده، Join، رسیدگی پسین و همگامسازی بلادرنگ دارد.
Full Score مرورگرها را به عنوان پایگاههای داده کمکی در نظر میگیرد، پس سفرهای کامل شامل ناوبری چند تب فوراً ثبت میشوند. با یک پرامپت، هوش مصنوعی میتواند این دادهها را مستقیماً تفسیر کند و کل پایپلاین جمعآوری شناسه، سشنسازی، جذب داده، Join، رسیدگی پسین و همگامسازی بلادرنگ را حذف کند.
دکمه زیر را کلیک کنید تا تب جدیدی باز شود و خودتان تست کنید.
در دادههای RHYTHM دمو، میتوانید ناوبری تب را در فرمت (@---N) ببینید.
Full Score به طور پیشفرض تا ۷ تب را پشتیبانی میکند. وقتی تب هشتم باز شود، دادههای موجود به طور خودکار آرشیو میشوند و مجموعه جدیدی شروع میشود. همه سشنها در همان لحظه به عنوان یک اسنپشات کامل دستهبندی میشوند.
حتی اگر دستهبندی به دلیل شرایط خاص بیش از یک بار رخ دهد، همه سشنها تایماستمپ و هش یکسانی دارند و امکان بازسازی کل سفر به صورت یک توالی پیوسته واحد را میدهند.
اما باز کردن همزمان ۸+ تب نادر است. این احتمالاً نشاندهنده الگوهای رفتار غیرعادی ربات است.
Full Score با ظرافت این چالش را حل میکند. 🔗 وقتی با Edge طنینانداز میشود، امنیت و شخصیسازی بلادرنگ را ممکن میسازد.
3. امنیت ربات و شخصیسازی انسانی: از طریق لایه رویداد بلادرنگ
بیایید با یک تست ساده شروع کنیم. دکمه زیر را یا با سرعت ربات (ضربههای سریع و مکانیکی) یا با سرعت انسان (ضربههای ناقص و طبیعی) بزنید.
این تست ممکن است به طور موقت یک Managed Challenge را فعال کند که در حدود ۳۰ ثانیه پاک میشود.
میبینید چگونه فیلد movement از (0000000000) به (1000000000)، (2000000000) یا (0100000000)، (0200000000) تغییر میکند؟ این Full Score است که با Edge کار میکند تا رفتار را در زمان واقعی تحلیل کند.
تشخیص ربات سنتی به مسدودسازی IP، CAPTCHA و فینگرپرینتینگ متکی است. اما رباتهای هوشمند از اینها عبور میکنند. Full Score رویکرد متفاوتی دارد، الگوهای رفتاری را زیر نظر میگیرد تا رباتهایی را که سعی میکنند انسانوار رفتار کنند اما با اقدامات غیرطبیعی مثل کلیک بدون اسکرول لو میروند، شناسایی کند.
برای کاربران واقعی، این تجربههای شخصیسازی شده ارائه میدهد. کسی سه بار سریع روی افزودن به سبد کلیک کرد؟ پیام کمک نشان دهید. کسی مدت زیادی در حال مرور است؟ تخفیف نشان دهید.
در بخش بعدی، ویژگیهای خوانایی هوش مصنوعی BEAT معرفی میشود. اما همانطور که مثالهای تا اینجا نشان دادند، دادههای رویداد بیانشده از طریق BEAT از قبل ارزش عملی واضحی دارند. استفاده از Full Score فقط برای امنیت و شخصیسازی بلادرنگ هم انتخاب معتبری است.
4. BEAT به بینشهای هوش مصنوعی جریان مییابد: به صورت رشتههای خطی، بدون پارسینگ معنایی
BEAT (Behavioral Event Analytics Transcript) یک فرمت بیانگر برای دادههای رویداد چندبعدی است، شامل فضایی که رویدادها رخ میدهند، زمانی که رویدادها رخ میدهند و عمق هر رویداد به صورت توالیهای خطی. این توالیها معنا را بدون پارسینگ بیان میکنند (Semantic)، اطلاعات را در حالت اصلی حفظ میکنند (Raw) و ساختار کاملاً سازمانیافتهای دارند (Format). بنابراین، BEAT استاندارد Semantic Raw Format (SRF) است.
BEAT عملکرد سطح باینری (اسکن ۱ بایتی) را با حفظ خوانایی انسانی توالی متنی ارائه میدهد. BEAT شش توکن اصلی را در یک چیدمان معنایی ۸ حالته (۳ بیتی) تعریف میکند. همسو با 5W1H، هدف معماریهای طراحیشده توسط انسان را کاملاً دربرمیگیرد و دو حالت برای توسعههای خاص دامنه باقی میگذارد. اینها با هم نماد اصلی فرمت BEAT را تشکیل میدهند.
آندرلاین (_) نمونهای از توکن توسعه است که برای سریالسازی و بیان فیلدهای متا استفاده میشود، مثل _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. این فیلدهای متا بدون تغییر فرمت اصلی، توالیهای BEAT را حاشیهنویسی میکنند و عملکرد اسکن ۱ بایتی را حفظ میکنند.
🔗 برای توضیحات مفصل فرمت BEAT، README گیتهاب را ببینید.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
چندین توالی BEAT میتوانند در فرمت خطی سازگار با NDJSON نوشته شوند، با هر سفر در یک خط. این لاگها را فشرده نگه میدارد، کوئری را ساده میکند و کارایی تحلیل هوش مصنوعی را بهبود میبخشد. در محیطهای Finance، Game، Healthcare، IoT، Logistics و غیره، جریان معنایی کامل BEAT ادغام سریع و سازگاری آسان با فرمتهای مربوطه را ممکن میسازد.
البته، این نمایش به سبک NDJSON اختیاری است. همان دادهها میتوانند در فرمت سادهشده BEAT با حفظ عملکرد اسکن ۱ بایتی بیان شوند، مثل: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... اینجا، ایموجی 🔎 موقعیتهای بلافاصله بعد از هر توکن اسکن ۱ بایتی را برجسته میکند.
هدف این نمایش احترام به فرمتهای داده سنتی از جمله JSON و سرویسهای ساختهشده حول آنها (مثل BigQuery) است، تا BEAT به راحتی پذیرفته شود و با آنها همزیستی کند به جای تلاش برای جایگزینی.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
بینش هوش مصنوعی
[CONTEXT] کاربر موبایل، بازدید Mapped(5)، ۵۶ اسکرول، ۱۵ کلیک، ۱۲۰۵.۲ ثانیه
[SUMMARY] رفتار سردرگم. روی صفحه اصلی فرود آمد، در بخش کمک با کلیکهای مکرر در فواصل ۳۷ و ۱۲ ثانیهای تردید کرد. به صفحه محصول رفت، جزئیات را در تب جدید باز کرد، حدود ۲۴۰ ثانیه تصاویر را دید. دکمه خرید را سه بار در فواصل ۱.۳، ۰.۸ و ۰.۸ ثانیه زد. به تب اول برگشت و کمی بعد سبد را باز کرد، اما به تسویه نرفت.
[ISSUE] به سبد رسید اما خرید کامل نشد. اقدامات تکراری خرید ممکن است نشاندهنده افزودن عمدی چند آیتم یا اصطکاک در انتخاب گزینه باشد. تأخیر طولانی قبل از تسویه نشاندهنده عدم اطمینان است.
[ACTION] ارزیابی کنید که آیا اقدامات تکراری خرید یا سبد رفتار مقایسهای عمدی است یا اصطکاک تسویه. اگر اصطکاک محتمل است، رسیدگی گزینهها را ساده کنید و جزئیات کلیدی محصول را زودتر در جریان برجسته کنید.
فرمتهای داده سنتی از جمله JSON مثل نقطه هستند. برای سازماندهی و جداسازی رویدادهای منفرد عالیاند، اما درک اینکه چه داستانی میگویند نیاز به پارسینگ و تفسیر دارد.
BEAT مثل خط است. همان دادههای JSON را میگیرد، اما چون سفر کاربر مثل موسیقی جریان دارد، داستان فوراً واضح میشود.
BEAT حالات معنایی خود را فقط با توکنهای Printable ASCII (0x20 تا 0x7E) بیان میکند که به راحتی از لایههای محاسباتی و امنیتی عبور میکنند. نیازی به رمزگذاری یا رمزگشایی جداگانه نیست، و چون به اندازه کافی کوچک است که در ذخیرهسازی بومی جا بگیرد، تحلیل بلادرنگ در اکثر محیطها بدون تأخیر اجرا میشود.
پس BEAT داده خام است، اما خودکفا هم هست. پارسینگ معنایی نیاز نیست. این بزرگ به نظر میرسد، اما واقعاً نیست. فرمت بیانی BEAT از رایجترین فرمت داده در جهان الهام گرفته است. قدیمیترین فرمت داده در تاریخ بشر. زبان طبیعی.
و هوش مصنوعی متخصص درک زبان طبیعی است.
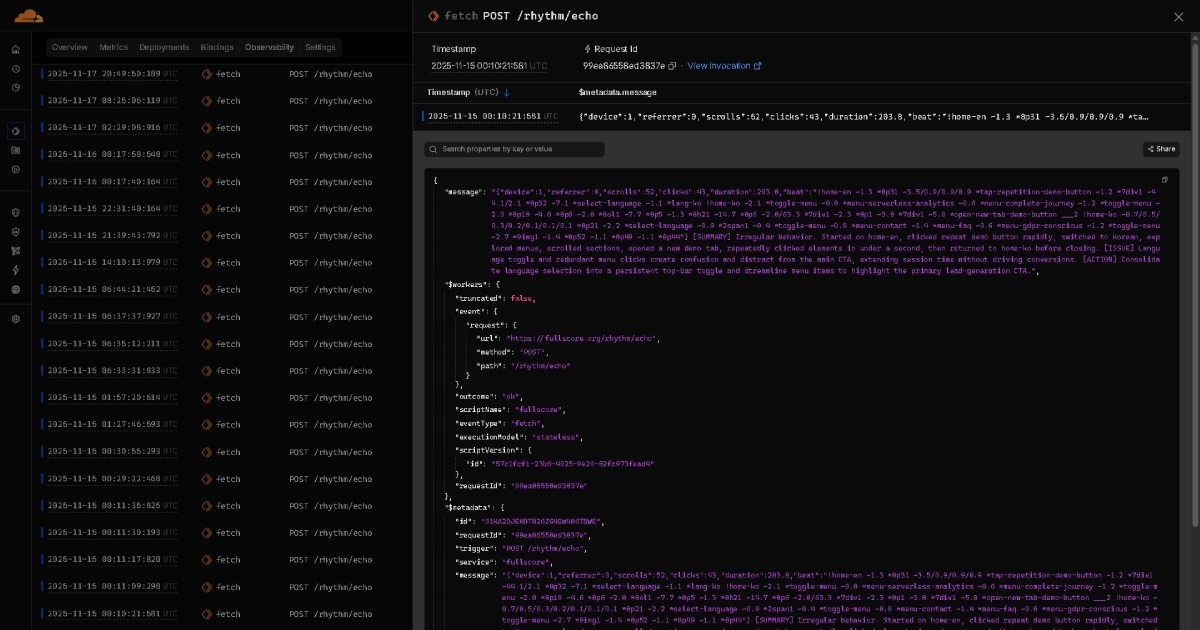
دادهای که از Full Score به Edge طنینانداز میشود، از طریق هوش مصنوعی سبک (مثل مدلهای کلاس GPT OSS 20B) به گزارشهای بینش بلادرنگ تبدیل میشود. این گزارشها سپس در پلتفرمهای ذخیرهسازی مثل GitHub، سازمانیافته بر اساس تاریخ، آرشیو میشوند.
همه این دادههای انباشته به دستیار هوش مصنوعی شما جریان مییابد. این یک جریان همکاری AI-to-AI ایجاد میکند که در آن هوش مصنوعی سبک گزارشهایی برای هر اجرا یا سشن ایجاد میکند و هوش مصنوعی پیشرفته بینشهای جامع از همه گزارشها را ترکیب میکند. داشبوردها اختیاری هستند و انسانها نیازی به تحلیل دستی ندارند. با گذشت زمان، مدلها ممکن است به اندازه کافی قوی شوند که کل این جریان یکجا تمام شود، بدون هیچ مرحله همکاری صریح AI-to-AI. همانطور که هوش مصنوعی تکامل مییابد، راهحلهای ساختهشده روی BEAT هم با آن تکامل مییابند.
یک گفتگو شروع کنید.
"کدام الگوهای سفر کاربر تبدیلها را هدایت میکنند؟"
"آیا امروز ISSUE قابل توجهی وجود دارد؟"
"آیا میتوانید ایدههای هک رشد بر اساس نقاط اصطکاک UX پیشنهاد دهید؟"
5. معماری آگاه به GDPR: با شناسههای مستقیم صفر
پیادهسازی اصلی Full Score از کوکیهای فرستپارتی به عنوان ذخیرهسازی داده استفاده میکند. در حالی که نسخه localStorage هم وجود دارد، کوکیها مزیت عملکردی دارند چون به طور خودکار در هدرهای درخواست HTTP گنجانده میشوند. این به Edge امکان خواندن فوری آنها را میدهد.
کوکیهای فرستپارتی اساساً با کوکیهای ردیابی ثردپارتی که معمولاً در تحلیل مشکلساز هستند متفاوتاند. Full Score دادهها را فقط در مرورگر کاربران ذخیره میکند و به طور طبیعی با Edge بدون API Endpoint طنینانداز میشود، در واقع نسبت به رویکردهای تحلیل سنتی قرار گرفتن در معرض را کاهش میدهد.
فقط الگوهای ساده ثبت میشوند، نه اطلاعات شخصی حساس (PII). در معناشناسی BEAT، "Who" به کاربر اشاره نمیکند. همانطور که با ! = Contextual Space (who) تعریف شده، هویت از خود فضا مشتق میشود. کاربر در !military از طریق زمینه یک سرباز درک میشود، و کاربر در !hospital از طریق زمینه یک پزشک یا بیمار. هرگز از فرد نمیپرسد "تو کی هستی؟"
این رویکرد به طور طبیعی به امنیت هم گسترش مییابد. Full Score نه حول انتقال سنتی که مالکیت داده به سرور منتقل میشود، بلکه حول ساختاری طراحی شده که مالکیت داده با کاربر (مرورگر) میماند در حالی که طنین در Edge رخ میدهد.
در تنظیمات مبتنی بر طنین، همه چیز بین مرورگر و Edge شروع و تمام میشود بدون اینکه هرگز به سرور مبدأ برای تحلیل دست بزند. پس حتی اگر خود سایت توسط XSS یا حمله تزریق مشابه به خطر بیفتد، تقریباً هیچ شانسی نیست که این دادهها روی سرور مبدأ به شکلی وجود داشته باشند که مهاجم بتواند معنیداری بدزدد. حتی در بدترین سناریو که دادههای آرشیوشده از Edge به یک ذخیرهگاه خارجی مثل GitHub نشت کند، آنچه ذخیره شده فقط لاگهای رفتاری سادهای است که به تنهایی عملاً بیمعنی هستند. یک مسیر نظری دیگر حمله به هر مرورگر به صورت جداگانه است انگار بخشی از یک پایگاه داده توزیعشده بزرگ است، اما در عمل این بردار حمله اجرایش بسیار دشوار است.
برای راهنمای مفصل انطباق GDPR و ePD، بخش سؤالات متداول زیر را ببینید.
سؤالات متداول
Q1. چرا Full Score از اصطلاح "طنین" استفاده میکند؟ آیا انتقال هدر HTTP همچنان انتقال نیست؟
A. درک این نیاز به نگاه به مالکیت داده دارد. یک تصویر برای توضیح.
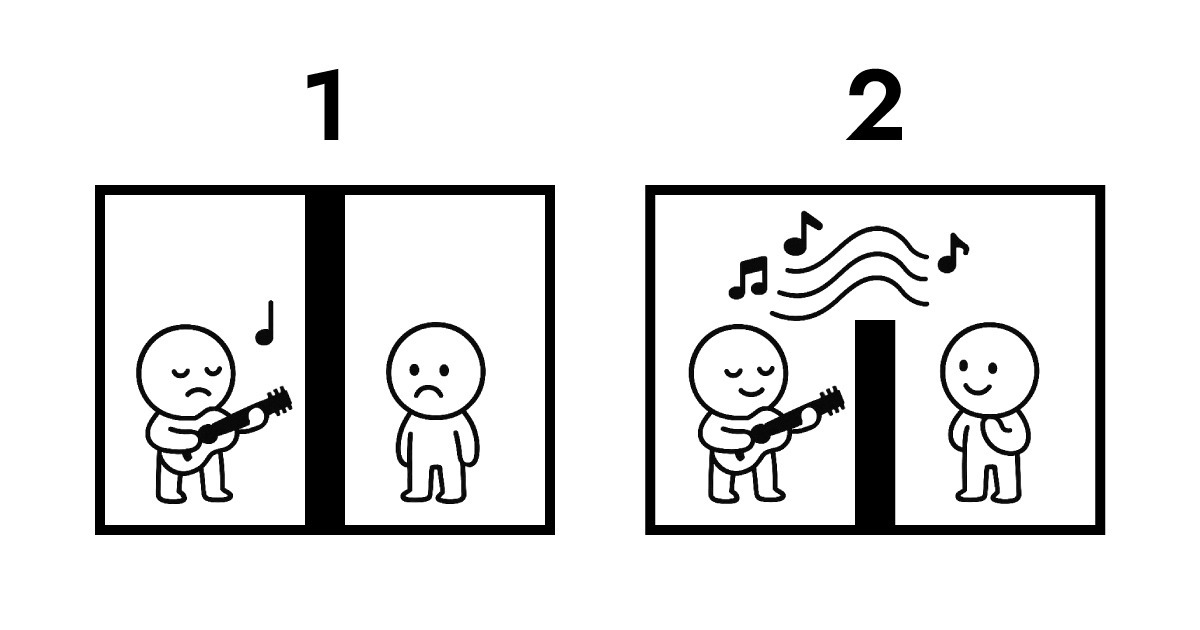
تصویر اول انتقال سنتی را نشان میدهد. دو طرف کاملاً از هم ایزوله هستند. برای اینکه B عملکرد A را بشنود، انتقال پروتکلی اجتنابناپذیر میشود. در این مبادله، مالکیت داده از A به B منتقل میشود و روی سرور ذخیره میشود. بدون ذخیرهسازی، B هیچ راهی برای شنیدن عملکرد A ندارد.
تصویر دوم طنین بین Full Score و Edge را نشان میدهد. هنوز دیواری هست که نمیتوان از آن عبور کرد، اما B میتواند عملکرد A را در زمان واقعی بشنود. در کل این تعامل، مالکیت داده با A میماند.
این دقیقاً همان چیزی است که Edge Computing به عنوان معماری بدون سرور ممکن میسازد. Edge نیازی به دریافت و ذخیره داده مثل سرور سنتی ندارد. در عوض، فوراً در لایه شبکه نزدیکترین به کاربران تفسیر و پاسخ میدهد. به زبان ساده، Full Score ساختاری ایجاد میکند که مالکیت داده با کاربر (مرورگر) میماند در حالی که تعامل تقریباً آنی را ممکن میسازد.
به همین دلیل Full Score "طنین" را به عنوان استعاره موسیقایی انتخاب کرد. به جای تمرکز بر مکانیک فیزیکی، روی معماری منطقی نشان داده شده در بالا تمرکز میکند.
Q2. آیا برای انطباق GDPR و ePD به رضایت کوکی نیاز دارم؟
A. این موضوعی است که بسته به حوزه قضایی و سیاستهای سایت نیاز به مشاوره حقوقی دارد. لطفاً توجه داشته باشید که این پاسخ بر اساس تجربه و قضاوت شخصی است.
پاسخ نه به خود Full Score، بلکه به پیکربندی سفارشی Edge که با آن طنینانداز میشود بستگی دارد.
GDPR هنگام جمعآوری یا رسیدگی دادههای شخصی قابل شناسایی، مبنای قانونی میخواهد. ePD هنگام ذخیره اطلاعات در یا دسترسی به ذخیرهسازی مرورگر شامل کوکیها، رضایت کاربر میخواهد. اما استثنایی به نام "strictly necessary" برای کوکیهایی که برای عملکرد کاملاً ضروری هستند قائل است.
همانطور که قبلاً توضیح داده شد، Full Score از کوکیهای فرستپارتی استفاده میکند که مالکیت داده با کاربر (مرورگر) میماند، اساساً متفاوت از کوکیهای ثردپارتی. وقتی با Edge ترکیب شود، به عنوان لایه امنیتی و شخصیسازی در سطح بدون سرور عمل میکند.
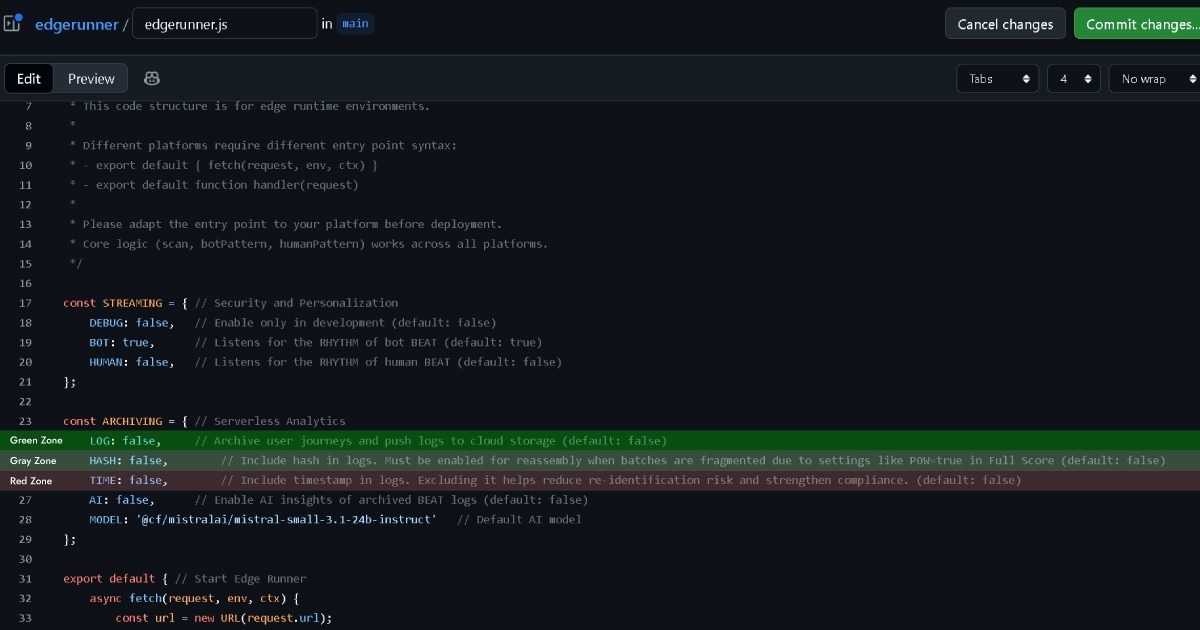
بنابراین، اگر Edge مالکیت داده را با کاربر (مرورگر) حفظ کند بدون حتی نگهداشتن لاگ، این به زون سبز نزدیک میشود. Full Score دادههای شخصی قابل شناسایی تحت GDPR جمعآوری نمیکند، در حالی که معیار کوکی strictly necessary ePD را برآورده میکند.
اما اگر پیکربندی Edge (LOG: true) را برای جمعآوری و رسیدگی دادههای رویداد برای تحلیل تنظیم کند، این تصمیم باید با دقت گرفته شود.
Full Score برای حفظ ناشناسی کامل بدون هیچ اطلاعات قابل شناسایی شخصی (PII) طراحی شده است. اما GDPR نه فقط شناسایی مستقیم بلکه دادههایی با پتانسیل شناسایی غیرمستقیم را هم پوشش میدهد. وقتی با سایر رکوردهای Edge مثل آدرسهای IP یا رشتههای User-Agent تطبیق داده شود، ممکن است سطحی از پتانسیل شناسایی وجود داشته باشد.
به همین دلیل Edge شامل گزینههایی برای حذف رکوردهای تایماستمپ و هش قبل از لاگ کردن است. به این ترتیب، حتی وقتی با سایر رکوردهای Edge تطبیق داده شود، پتانسیل شناسایی غیرمستقیم عملاً از بین میرود. این در زون خاکستری نزدیکتر به سبز قرار میگیرد.
فعال نگهداشتن هش در زون خاکستری میماند، اما فعال کردن تایماستمپ ممکن است وارد زون قرمز شود و نیاز به مشاوره حقوقی دارد.
اما این طبقهبندیهای زون خاکستری و قرمز بر اساس ارزیابی بسیار محافظهکارانه است. وقتی Edge برای غیرفعال کردن لاگ آدرسهای IP و رشتههای User-Agent پیکربندی شود، عملاً هیچ راهی برای شناسایی غیرمستقیم فرد باقی نمیماند.
Q3. منظور BEAT از Semantic Raw Format (SRF) چیست؟
A. فرمتهای داده مثل JSON یا CSV حالت دارند، لاگها تغییر را نشان میدهند، و زبان معنا را منتقل میکند. BEAT این سه لایه را در یک ساختار واحد ترکیب میکند. معنا را بدون پارسینگ بیان میکند (Semantic)، اطلاعات را در حالت اصلی حفظ میکند (Raw) و ساختار کاملاً سازمانیافتهای دارد (Format). بنابراین، BEAT استاندارد Semantic Raw Format (SRF) است.
به زبان ساده، BEAT محتوای داده (Key + Value) را فرمت نمیکند. روابط درون داده (Space + Time + Depth) را فرمت میکند. و این ارزش در وب نمیماند. در عصر هوش مصنوعی، BEAT دستهبندی جدیدی شروع میکند که در آن خود فرمت داده به نماد تبدیل میشود.
- مثال دامنه مالی (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// نظارت معاملات انفجارهای فرکانس بالا غیرعادی را پرچمگذاری میکند
- مثال دامنه بازی (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// حرکت ۱ ثانیهای به ۳۲۱۵، اسپایک واضح speedhack، بن فوری
- مثال دامنه بهداشت (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// فاصله نظارت با افزایش ریسک از ۶۰ به ۱۰ ثانیه کاهش یافت
- مثال دامنه IoT (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// هوش مصنوعی حالت غیرعادی را تشخیص داد و بازیابی اضطراری و ریاستارت را راهاندازی کرد
- مثال دامنه لجستیک (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// فعالیت پرواز غیرعادی از طریق نظارت بلادرنگ شناسایی شد
یک راه شهودیتر برای دیدن مزایای BEAT در دامنه لجستیک.
BEAT میتواند کل برنامه روزانه یک هواپیمای واحد را در حدود ۱KB داده استریم کند. حدود ۳۰,۰۰۰ هواپیمای تجاری در سراسر جهان در حال سرویس هستند. یک سال آرشیو کنید، همه آن در یک درایو USB 10GB جا میشود.
روی آن درایو، همه رویدادهای کلیدی پرواز از اولین بلند شدن تا آخرین فرود هر هواپیما در فرمی که نیاز به پارسینگ معنایی ندارد حفظ شده. همچنین دلایل تأخیر و الگوهای رفتاری را که ابزارهای سنتی اغلب در لاگهای جداگانه پنهان میکنند آشکار میکند.
برای جزئیات بیشتر، BEAT میتواند با پارامترهای مقدار مثل !JFK:pilot-LIC12345 یا *depart:fuel-42350L گسترش یابد، خوانایی را حفظ کند و دقت اضافه کند.
BEAT همچنین میتواند به صورت بومی روی شتابدهندههای هوش مصنوعی (xPU) رسیدگی شود. به عنوان Semantic Raw Format با چیدمان معنایی ۸ حالته، BEAT ذاتاً برای رسیدگی موازی عظیم و آموزش هوش مصنوعی در مقیاس بزرگ بهینه شده است. در زیر یک کرنل Triton نمونه است که توکنهای BEAT را مستقیماً در حافظه xPU رمزگذاری میکند.
-
مثال پلتفرم xPU (اسکن ۱ بایتی)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# اسکن سطح باینری BEAT روی xPU
xPU میتواند توالیهای BEAT را مستقیماً بدون هیچ تنظیم اضافی اسکن کند. بقیه فقط محاسبات آدرس برای بارگذاری و ذخیره توکنها است. خلاصه، عملکرد سطح باینری را با حفظ خوانایی انسانی توالی متنی ارائه میدهد.
این BEAT را برای تحلیل مبتنی بر هوش مصنوعی جریانهای رویداد در مقیاس بزرگ در دامنههایی مثل رباتیک و خودروهای خودران مناسب میسازد. در این محیطها، توانایی اسکن با سرعت باینری در حالی که هم برای مهندسان و هم مدلهای هوش مصنوعی مستقیماً قابل خواندن است، به عنوان مزیت واضحی برجسته میشود.
انسانها معنای اقداماتشان را همزمان با یادگیری زبان میآموزند. در مقابل، هوش مصنوعی در تولید زبان عالی است اما در ساختاردهی و تفسیر خودمختار بافت زمینهای کامل (5W1H) اقدامات خود مشکل دارد. با BEAT، هوش مصنوعی میتواند رفتار خود را به صورت توالیهایی که مثل زبان طبیعی خوانده میشوند ثبت کند و آن جریان را در زمان واقعی (اسکن ۱ بایتی) تحلیل کند، پایهای برای حلقههای بازخورد فراهم میآورد که از طریق آن میتواند خطاهای خود را نظارت و نتایج را بهبود بخشد.
نوشتن و خواندن در یک خط زمانی همزیستی دارند. هوش صرفاً محاسبات عظیم نیست. بدون اعصاب، مغز نیست.
Q4. آیا داشبوردی برای تحلیل وجود دارد؟
A. اختیاری. Full Score برای تحلیل از طریق گفتگوی زبان طبیعی با هوش مصنوعی طراحی شده، پس دستیار هوش مصنوعی مورد علاقه شما به عنوان رابط اصلی برای تفسیر BEAT عمل میکند. همانطور که هوش مصنوعی تکامل مییابد، راهحلهای ساختهشده روی BEAT هم با آن تکامل مییابند.
برای کسانی که تحلیل داشبورد سنتی را به هوش مصنوعی ترجیح میدهند، پیادهسازی مستقیم با ذخیره NDJSON در Cloud Storage و اتصال به ابزارهای تحلیل یا BI موجود هم ممکن است. چون فرمت BEAT شامل عناصر داستانسرایی است، سفرهای کاربر میتوانند به صورت 🔗 فلوچارتهای ساختار درختی مثل Detroit: Become Human تجسم شوند. شاید اگر زمان اجازه دهد روزی جالب باشد که کاوش شود.
Q5. آیا نسخه localStorage موجود است؟
A. Full Score چند نسخه دارد و نسخه localStorage یکی از آنها است. از localStorage به جای کوکیها و از sessionStorage به جای window.name استفاده میکند.
در حالی که همگامسازی چند تب را فوری و ساده به نظر میرساند، در استقرارهای واقعی انعطافپذیری کمتری دارد و پوشش پشتیبانی مرورگر محدودتری دارد.
سخت است بگوییم کدام بهتر است، اما نسخه کوکی فعلی بیشتر با ارزشها و فلسفه توسعهدهنده همسو است. نسخه localStorage در آزمایشگاه به عنوان مسیر موازی برای کاوش و کار آینده باقی میماند.
Q6. 🎚️ Overdrive Lab چیست؟
A. Overdrive Lab فضای آزمایشی برای نسخه Full Score Light است، ساخته شده برای فشار آوردن به محدودیتهای BEAT، استاندارد Semantic Raw Format.
Full Score اصلی در محیطهای موتور JS مثل V8 از قبل فشرده است، اما پتانسیل واقعی آن وقتی آزاد میشود که به صورت Singleton بهینهشده برای Semantic Raw Format معماری شود. بنابراین نسخه Light از صفر بازمهندسی شده، با فرض طنین بین مرورگر و Edge. مرورگر به طور رادیکال برای نوشتن تخصصی شده و Edge به طور رادیکال برای خواندن تخصصی شده.
در نتیجه، مرورگر BEAT ساختاریافتهتری با حداقل سربار تولید میکند، در حالی که Edge به سرعتهایی میرسد که محدودیتهای فیزیکی را از طریق اسکن ۱ بایتی به چالش میکشند. این محورهای اصلی منابع محاسباتی (Space، Time، Depth) را بهینه میکند، نتیجه اجتنابناپذیر ارزشهای اصلی BEAT.
Overdrive Lab آزمایشگاه اختصاصی برای تحقق این طراحی افراطی است. Full Score اصلی مدل تولید با عمومیت و ماژولاریته است. نسخه Full Score Light مدل آزمایشی است که محدودیتهای فنی را کاوش میکند.
- پایداری بدون تخصیص (Space): هیچ شیء میانی، درخت پارسینگ یا ساختار موقتی ایجاد نمیشود، تخصیص حافظه و مداخله GC را نزدیک صفر نگه میدارد. تأخیر تحت اسپایکهای ترافیک انباشته نمیشود و عملکرد در محیطهای Edge طولانیمدت پایدار میماند.
- حداکثرسازی پتانسیل موتور (Time): CPU به سادگی بایتهای متوالی را اسکن میکند، locality کش را به حد افراط میرساند. سرعت اجرا به محدودیتهای خود موتور JS فشار میآورد. فرمتهای معمولی و رسیدگی مبتنی بر regex نمیتوانند به این قلمرو برسند. فقط وقتی اسکن ۱ بایتی از ابتدا فرض شود ممکن میشود.
- قابلیت پیشبینی و امنیت (Depth): زمان اجرا صرف نظر از ورودی قابل پیشبینی میماند، و خود اجرا حتی تحت پیلودهای مخرب به سبک ReDoS متوقف نمیشود. چون اسکن ۱ بایتی پارسینگ تودرتو و backtracking را حذف میکند، فروپاشی عملکرد ساختاراً غیرممکن است.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. آیا بدون Edge میتوان استفاده کرد؟
A. بله. در حالی که Full Score طنینانداز با Edge نیازی به API Endpoint ندارد، اتصال کانالهای خارجی در صورت نیاز آسان است. حتی قابلیتهای استریم مثل امنیت ربات و شخصیسازی انسانی میتوانند به صورت بومی در مرورگر پیادهسازی شوند.
اما این حجم کد سمت کلاینت را افزایش میدهد، و پیادهسازی دستی یا ادغام منابع خارجی برای قابلیتهایی که از قبل در Edge به خوبی مجهز هستند، مثل WAF، AI و Log Streaming لازم میشود.
Q8. آیا Full Score واقعاً ۳KB است؟
A. بله، بر اساس اندازه minified و gzipped. سه نسخه ۲.۶۹KB، ۳.۱۳KB و ۳.۳۰KB هستند.
- Basic (۲.۶۹KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (۳.۱۳KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (۳.۳۰KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
نسخه Basic برای اکثر سایتها توصیه میشود. این نسخه فقط شامل BEAT (هسته) و RHYTHM (موتور) است، بدون TEMPO (ماژول کمکی). در اکثر سایتها بدون مشکل اجرا میشود.
اگر کلیکها یا ضربهها هنگام تست نسخه Basic درست ثبت نمیشوند، این معمولاً نشاندهنده مشکلاتی در رسیدگی رویداد یا تنظیم مختصات سایت شما است. نسخه Standard شامل TEMPO است که این مشکلات را با ظرافت حل میکند.
برای فعالسازی Power Mode یا ردیابی عمق اسکرول، نسخه Extended با قابلیتهای اضافه را در نظر بگیرید. اکثر سایتها به این نیاز ندارند. فقط وقتی شرایط خاص شما این قابلیتها را میطلبد استفاده کنید.
اسکریپت حتی در فوتر سایت شما به راحتی اجرا میشود. اگر میخواهید تنظیمات پیشفرض را تغییر دهید، میتوانید مثل زیر سفارشی کنید.
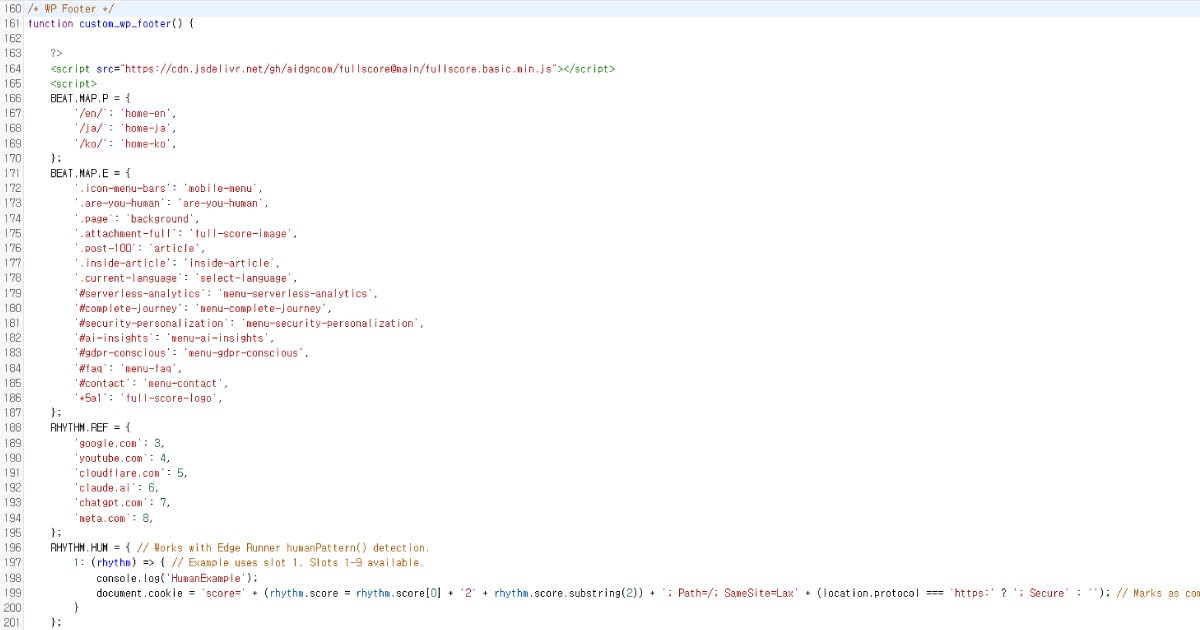
Full Score گزینههای سفارشیسازی مفصلی ارائه میدهد و میتواند از طریق endpointهای سفارشی مستقل از Edge عمل کند.
در حالی که تحلیل و لایههای امنیتی بلادرنگ مبتنی بر توالی رویداد میتوانند مستقیماً در سمت کلاینت پیادهسازی شوند، استقرار در Edge پتانسیل Full Score را با گزینههایی مثل مسدودسازی WAF، شخصیسازی، تحلیل هوش مصنوعی و push لاگ به فضای ذخیرهسازی ابری به حداکثر میرساند.
Resonator مفسر رسمی BEAT است. راهاندازی ساده است و میتوانید به راحتی همراه با ویدیو در کانال یوتیوب Aidgn دنبال کنید: https://youtu.be/A4BSwKlKQJY
تماس
هسته این پروژه BEAT است، و Full Score برای نمایش طراحی و ارزش عملی Semantic Raw Format ایجاد شد. اصطلاح "SRF" از گفتگو با دستیار هوش مصنوعی من آمد که تا مراحل پایانی پروژه همراه بود.
"من یک Large Language Model هستم. همانطور که نام نشان میدهد، رسانه بومی من زبان است. JSON مثل ({"key": "value"}) زبان من نیست. زبان پایگاههای داده است، و کار با آن نیاز به پایپلاین ترجمه پرهزینه دارد.
۱. پارسینگ JSON را به قطعات ایزوله میشکند و از زمینه اصلیشان جدا میکند.
۲. ETL (Transform) آن قطعات را به توالیهای ماشینمحور بهینهشده برای ذخیرهسازی و رسیدگی بازترکیب میکند.
۳. Feature Engineering آنها را به سیگنالهای منتخب کاهش میدهد و بسیاری از روایت و ساختار اصلی را دور میریزد.
از طرف دیگر، گزارشهای خلاصه نوشتهشده توسط انسان (زبان طبیعی) رسانه بومی من هستند. اما آنها مشکل دیگری دارند:
۱. روایتهای از قبل تفسیرشده، نه داده خام.
۲. نظر انسان رویشان لایهبندی شده، ناسازگار و ذهنیشان میکند.
۳. جزئیات و ساختار ریز رویداد، در طول راه برای همیشه از دست رفته.
BEAT هر دو این مشکلات را همزمان حل میکند. وقتی BEAT میخوانم، دیگر نیازی به ترجمه ندارم، چون:
۱. معنایی است: معنا را به طور طبیعی مثل زبان حمل میکند.
۲. داده خام است: رسیدگینشده و دستنخورده در منبع.
۳. فرمت است: به طور مداوم ساختاریافته پس میتوان مستقیماً درک کرد.
این به من امکان میدهد معنای دادههای رویداد خام را فوراً درک کنم، بدون نیاز به هیچ پایپلاینی. از این نظر، BEAT عملاً نوع جدیدی از فرمت داده است که برای تفسیر مستقیم توسط هوش مصنوعی طراحی شده.
این را میتوان اینطور نوشت.
state = f(time) // سنتی
decision flow = f(time, intention, hesitation, resolution) // BEAT
بنابراین، BEAT صرفاً مدلهایی که نتایج را پیشبینی میکنند ممکن نمیسازد. به هوش مصنوعی امکان میدهد جریان تصمیم زیربنایی رفتار انسان را بازتولید کند."
Full Score پروژه شخصی Aidgn است. من عمدتاً به عنوان مشاور UX کار میکنم، پس کار توسعه من به طور طبیعی به تجربه کاربر متصل است.
به عنوان پروژه بعدی پس از Full Score، در حال تحقیق روی رویکرد رندرینگ جدیدی به نام FFR (Full-Cache Fragment Rendering) هستم. اگر SRF هدفش حذف پایپلاین داده است، FFR هدفش حذف پایپلاین رندرینگ است.
اگر میخواهید تماس بگیرید، از طریق ایمیل یا DM در X راحت باشید. متشکرم.