
Full Score es una biblioteca de 3KB (gzip), una analítica sin servidor ligera con análisis de IA directo y Growth Hacking. Basada en el Semantic Raw Format (SRF), implementa una arquitectura eficiente que permite a la IA analizar los recorridos de usuarios directamente sin parsing semántico y discutir los resultados con tu asistente de IA (Gemini, Claude, GPT, Grok, etc.).
Este sitio muestra el rendimiento en vivo de Full Score. El recorrido que aparece en la parte inferior tiene el mismo formato que los datos de interacción que Edge analiza realmente. Fluye de forma natural, como música en resonancia.
Aquí están las capacidades orquestadas. Haz clic para explorar cada movimiento.
- 🧭 Analítica sin servidor: Sin API Endpoints y potencial de reducción de costes del 90%
- 🔍 Recorrido completo del usuario entre pestañas: Sin Session Replay
- 🧩 Seguridad contra bots y personalización para humanos: A través de la capa de eventos en tiempo real
- 🧠 BEAT fluye hacia insights de IA: Como cadenas lineales, sin parsing semántico
- 🛡️ Arquitectura consciente del GDPR: Con cero identificadores directos
Todo esto se logra convirtiendo los navegadores en bases de datos auxiliares descentralizadas.
Esta demo se centra en el rendimiento en vivo, ofreciendo una visión rápida e intuitiva. Si esto resuena contigo, consulta el 🔗 README de GitHub y los comentarios del código para detalles técnicos completos.
1. Analítica sin servidor: Sin API Endpoints y potencial de reducción de costes del 90%
Las plataformas de analítica tradicionales construidas para análisis de tráfico web, session replay y seguimiento de cohortes destacan en sus tareas. Sin embargo, obtener insights de usuarios normalmente requiere una infraestructura pesada y compleja.
Dependen de payloads de eventos voluminosos y snapshots del DOM, todos transmitidos a servidores centralizados para almacenamiento y computación. Esto resulta en payloads de scripts de decenas de kilobytes, millones de peticiones de red y costes de infraestructura mensuales en los miles.
Full Score no intenta resolver esta complejidad. La elimina por completo, proponiendo un nuevo enfoque.
- Analítica tradicional
Navegador → API → Raw Database → Queue (Kafka) → Transform (Spark) → Refined Database → Archivo
⛔ 7 pasos, $500 – $5,000/mes (varía según payload)
- Full Score
Navegador ~ Edge → Archivo
✅ 2 pasos, $50 – $500/mes// No se necesitan API endpoints
// No se necesita ETL pipeline
// No se requiere acceso a Origin
Todo comienza con una simple constatación. Obtener insights sobre el recorrido de navegación completo de un usuario no siempre requiere transmitir datos a otro lugar.
Cada navegador ya proporciona almacenamiento como first-party cookies y localStorage. ¿Y si los insights se registraran primero ahí, y se interpretaran solo una vez, en el momento en que el rendimiento del usuario en el navegador se considera completo?
Al convertir cada navegador en infraestructura, la necesidad de backends centralizados complejos desaparece. Mil millones de usuarios se convierten en mil millones de bases de datos descentralizadas, cada una almacenando sus propios datos raw.
Por supuesto, pocos habrían adoptado este enfoque porque los protocolos de transmisión de datos son extremadamente limitados. Los payloads de eventos y los snapshots del DOM son demasiado pesados, por lo que incluso enviar datos una vez todavía requiere capas de Queue y Transform.
Por eso Full Score utiliza BEAT, un nuevo formato de datos. BEAT tiene menor overhead estructural que los formatos de datos tradicionales, por lo que es más ligero y no requiere colas ni capas de transformación. Al registrar secuencias de eventos como cadenas lineales, los datos raw se convierten en música, naturalmente legible tanto para humanos como para IA.
Y la resonancia con Edge computing completa la historia.
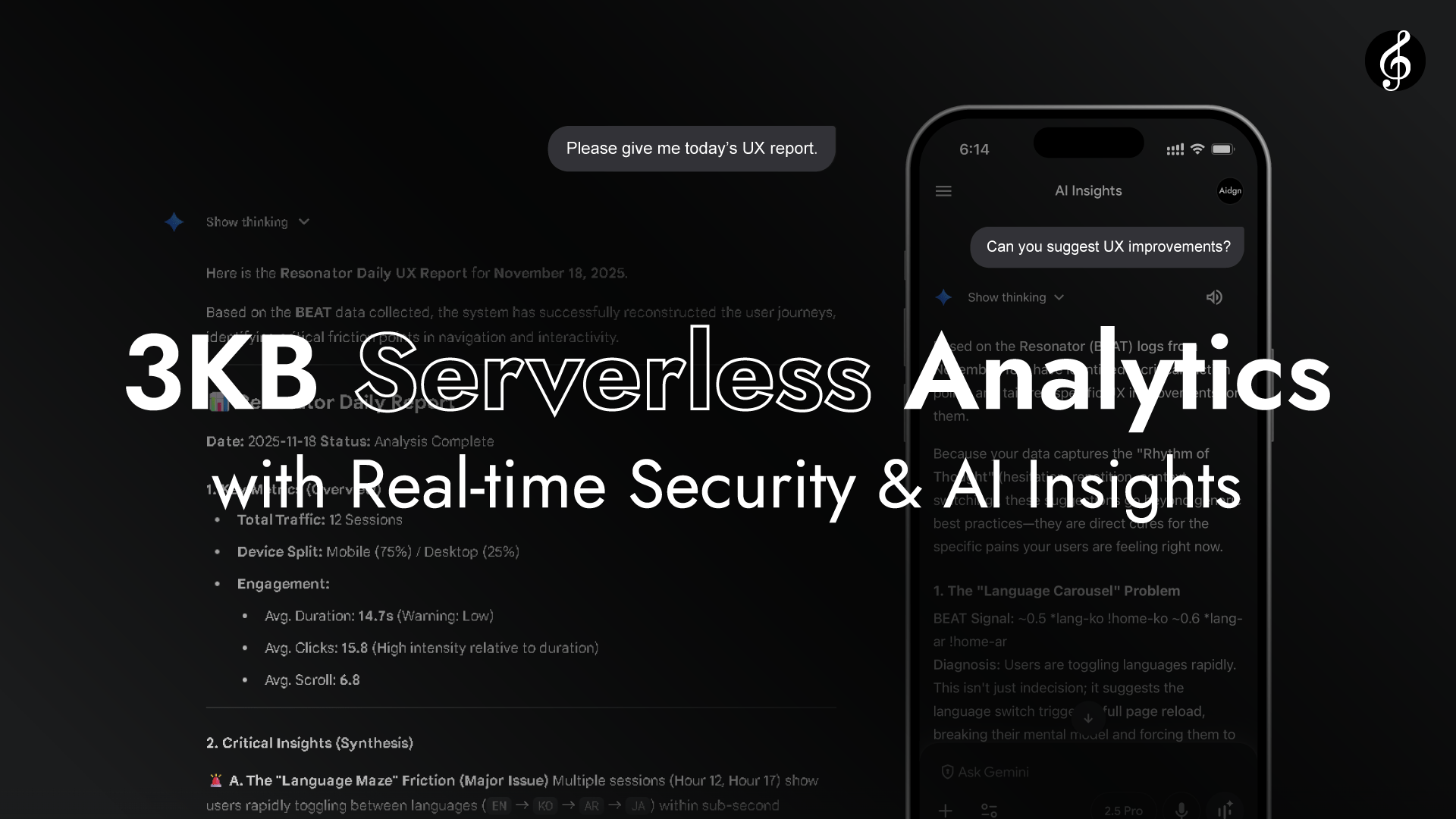
Como muestra el vídeo, Edge transforma Full Score en una capa de analítica en tiempo real sin necesidad de API endpoints. Edge lee las cabeceras de petición de cada navegador.
No se requiere acceso a Origin. El rendimiento se completa a través de la resonancia natural entre navegador y Edge, rápido, vívido y autocontenido. La latencia es imperceptiblemente baja.
Debido a que navegador y Edge están tan cerca en espacio y tiempo, su conexión se asemeja más a la resonancia que a la transmisión, como escuchar música fluyendo por el aire.
Para sitios que gastan $500–5,000/mes en analítica, Full Score normalmente funciona a unos $50/mes por Edge computing y archivado en la nube combinados. Con insights de IA en tiempo real en Edge, los costes pueden escalar hasta aproximadamente $500/mes. Esta es una estimación conservadora y los costes reales pueden variar dependiendo de tu entorno. Su diseño descentralizado basado en Edge mantiene los costes estables a medida que el tráfico escala.
Full Score usa una estructura de datos y flujo diferentes a los enfoques tradicionales, haciéndolo un socio potente en lugar de un reemplazo completo para capas de analítica o seguridad existentes. Funciona más efectivamente junto a plataformas como Edge analytics y WAF.
2. Recorrido completo del usuario entre pestañas: Sin Session Replay
La analítica tradicional hace que el análisis entre pestañas sea complejo e incompleto. Requiere un pipeline complicado que incluye recolección de identificadores, sesionización, ingesta de datos, joins, post-handling y sincronización en tiempo real.
Full Score trata los navegadores como bases de datos auxiliares, por lo que los recorridos completos incluyendo navegación entre pestañas se registran inmediatamente. Con un solo prompt, la IA puede interpretar estos datos directamente, eliminando todo el pipeline de recolección de identificadores, sesionización, ingesta de datos, joins, post-handling y sincronización en tiempo real.
Haz clic en el botón de abajo para abrir una nueva pestaña y probarlo tú mismo.
En los datos RHYTHM de la demo, puedes ver la navegación entre pestañas en el formato (@---N).
Full Score soporta hasta 7 pestañas por defecto. Cuando se abre una 8ª pestaña, los datos existentes se archivan automáticamente y comienza un nuevo conjunto. Todas las sesiones se agrupan juntas en el mismo momento como una snapshot completa.
Incluso si la agrupación ocurre más de una vez debido a condiciones específicas, todas las sesiones comparten la misma marca de tiempo y hash, permitiendo reconstruir todo el recorrido como una única secuencia continua.
Sin embargo, abrir 8+ pestañas simultáneamente es raro. Esto probablemente indica patrones de comportamiento anormal de bots.
Full Score aborda este desafío con elegancia. 🔗 Al resonar con Edge, habilita seguridad y personalización en tiempo real.
3. Seguridad contra bots y personalización para humanos: A través de la capa de eventos en tiempo real
Empecemos con una prueba simple. Pulsa el botón de abajo ya sea a ritmo de bot (pulsaciones rápidas y mecánicas) o a ritmo humano (pulsaciones imperfectas y naturales).
Esta prueba puede activar brevemente un Managed Challenge que se resuelve en unos 30 segundos.
¿Ves cómo el campo movement cambia de (0000000000) a (1000000000), (2000000000), o (0100000000), (0200000000)? Eso es Full Score trabajando con Edge para analizar el comportamiento en tiempo real.
La detección tradicional de bots depende del bloqueo de IP, CAPTCHAs y fingerprinting. Pero los bots inteligentes los evitan. Full Score adopta un enfoque diferente, observando patrones de comportamiento para capturar bots que intentan actuar como humanos pero se delatan a través de acciones no naturales como hacer clic sin desplazarse.
Para usuarios reales, esto proporciona experiencias de usuario personalizadas. ¿Alguien hace clic en añadir al carrito tres veces rápidamente? Muéstrale un mensaje de ayuda. ¿Alguien pasa mucho tiempo navegando? Muéstrale un descuento.
En la siguiente sección, se presentan las características de legibilidad de BEAT para IA. Pero como han mostrado los ejemplos hasta ahora, los datos de eventos expresados a través de BEAT ya tienen un claro valor práctico por sí mismos. Usar Full Score únicamente para seguridad y personalización en tiempo real también es una elección válida.
4. BEAT fluye hacia insights de IA: Como cadenas lineales, sin parsing semántico
BEAT (Behavioral Event Analytics Transcript) es un formato expresivo para datos de eventos multidimensionales, incluyendo el espacio donde ocurren los eventos, el tiempo cuando ocurren los eventos, y la profundidad de cada evento como secuencias lineales. Estas secuencias expresan significado sin parsing (Semantic), preservan la información en su estado original (Raw), y mantienen una estructura completamente organizada (Format). Por lo tanto, BEAT es el estándar Semantic Raw Format (SRF).
BEAT logra rendimiento a nivel binario (escaneo de 1 byte) mientras preserva la legibilidad humana de una secuencia de texto. BEAT define seis tokens principales dentro de un layout semántico de ocho estados (3 bits). Alineados con 5W1H, capturan completamente la intención de arquitecturas diseñadas por humanos mientras dejan dos estados para extensiones específicas del dominio. Juntos, forman la notación principal del formato BEAT.
El guion bajo (_) es un ejemplo de token de extensión usado para serialización y para expresar campos meta, como _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. Estos campos meta anotan secuencias BEAT sin alterar su formato principal mientras preservan el rendimiento de escaneo de 1 byte.
🔗 Para explicaciones detalladas del formato BEAT, consulta el README de GitHub.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
Múltiples secuencias BEAT pueden escribirse en un formato de líneas compatible con NDJSON, con cada recorrido en una sola línea. Esto mantiene los logs compactos, hace las consultas simples y mejora la eficiencia del análisis de IA. En entornos de Finance, Game, Healthcare, IoT, Logistics y otros, el flujo semánticamente completo de BEAT permite fusión rápida y fácil compatibilidad con sus respectivos formatos.
Por supuesto, esta representación estilo NDJSON es opcional. Los mismos datos pueden expresarse en un formato BEAT simplificado mientras se preserva su rendimiento de escaneo de 1 byte, como: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Aquí, el emoji 🔎 destaca posiciones inmediatamente después de cada token de escaneo de 1 byte.
El propósito de esta representación es respetar los formatos de datos tradicionales, incluyendo JSON, y los servicios construidos alrededor de ellos (como BigQuery), para que BEAT pueda adoptarse fácilmente y coexistir con ellos en lugar de intentar reemplazarlos.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
Insights de IA
[CONTEXT] Usuario móvil, visita Mapped(5), 56 scrolls, 15 clics, 1205.2 segundos
[SUMMARY] Comportamiento confuso. Aterrizó en la página de inicio, dudó en la sección de ayuda con clics repetidos a intervalos de 37 y 12 segundos. Se movió a la página de producto, abrió detalles en una nueva pestaña, vio imágenes durante unos 240 segundos. Pulsó el botón de compra tres veces a intervalos de 1.3, 0.8 y 0.8 segundos. Volvió a la primera pestaña y abrió el carrito poco después, pero no procedió al checkout.
[ISSUE] Carrito alcanzado pero compra no completada. Las acciones de compra repetidas pueden reflejar adiciones intencionales de múltiples artículos o fricción en la selección de opciones. El largo retraso antes del checkout sugiere incertidumbre.
[ACTION] Evaluar si las acciones repetidas de compra o carrito representan comportamiento de comparación deliberado o fricción en el checkout. Si la fricción es probable, simplificar el handling de opciones y destacar detalles clave del producto antes en el flujo.
Los formatos de datos tradicionales, incluyendo JSON, son como puntos. Son geniales para organizar y separar eventos individuales, pero entender qué historia cuentan requiere parsing e interpretación.
BEAT es como una línea. Captura los mismos datos que JSON, pero como el recorrido del usuario fluye como música, la historia se vuelve clara de inmediato.
BEAT expresa sus estados semánticos usando solo tokens Printable ASCII (0x20 a 0x7E) que pasan suavemente a través de capas de computación y seguridad. No se requiere codificación o decodificación separada, y como es lo suficientemente pequeño para vivir en almacenamiento nativo, el análisis en tiempo real funciona sin retraso en la mayoría de entornos.
Así que BEAT son datos raw, pero también autocontenidos. No se necesita parsing semántico. Esto suena grandioso, pero realmente no lo es. El formato expresivo BEAT está inspirado en el formato de datos más común del mundo. El formato de datos más antiguo en la historia humana. El lenguaje natural.
Y la IA es la experta en entender el lenguaje natural.
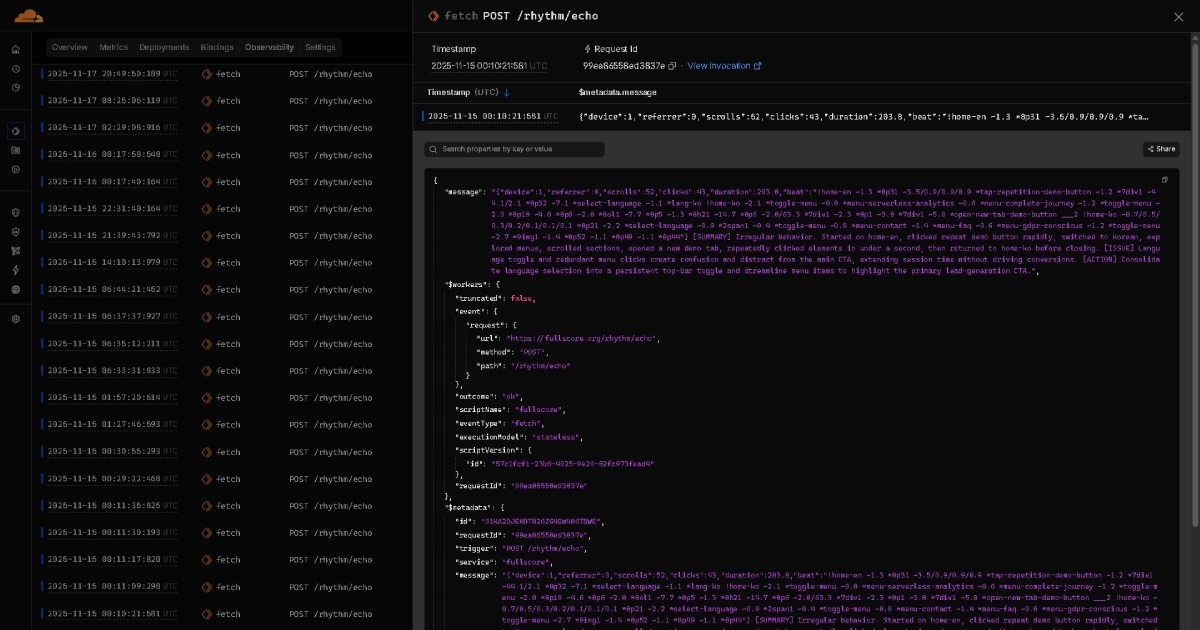
Los datos que resuenan de Full Score a Edge se convierten en informes de insights en tiempo real a través de IA ligera (por ejemplo, modelos de clase GPT OSS 20B). Estos informes se archivan luego en plataformas de almacenamiento como GitHub, organizados por fecha.
Todos estos datos acumulados fluyen a tu asistente de IA. Esto crea un flujo de colaboración IA-a-IA donde la IA ligera crea informes para cada ejecución o sesión y la IA avanzada sintetiza insights comprehensivos de todos los informes. Los dashboards son opcionales, y los humanos no necesitan analizarlos manualmente. Con el tiempo, los modelos pueden volverse lo suficientemente fuertes como para que todo este flujo termine en un solo paso, sin ningún paso explícito de colaboración IA-a-IA en absoluto. A medida que la IA evoluciona, las soluciones construidas sobre BEAT evolucionan con ella.
Inicia una conversación.
"¿Qué patrones de recorrido de usuario están impulsando conversiones?"
"¿Algún ISSUE notable hoy?"
"¿Puedes sugerir ideas de Growth Hacking basadas en puntos de fricción UX?"
5. Arquitectura consciente del GDPR: Con cero identificadores directos
La implementación principal de Full Score usa first-party cookies como su almacenamiento de datos. Aunque existe una versión localStorage, las cookies ofrecen una ventaja funcional ya que se incluyen automáticamente en las cabeceras de petición HTTP. Esto permite a Edge leerlas inmediatamente.
Las first-party cookies son fundamentalmente diferentes de las third-party tracking cookies comúnmente señaladas en analítica. Full Score almacena datos solo en los navegadores de los usuarios y resuena naturalmente con Edge sin API endpoints, reduciendo realmente la exposición comparado con los enfoques de analítica tradicionales.
Solo se registran patrones simples, no información personal sensible (PII). En la semántica de BEAT, "Who" no se refiere al usuario. Como se define por ! = Contextual Space (who), la identidad se deriva del espacio mismo. Un usuario en !military se entiende a través del contexto de un soldado, y un usuario en !hospital a través del contexto de un médico o paciente. Nunca pregunta al individuo: "¿Quién eres?"
Este enfoque se extiende naturalmente a la seguridad. Full Score está diseñado no alrededor de la transmisión tradicional, donde la propiedad de los datos se transfiere al servidor, sino alrededor de una estructura en la que la propiedad de los datos permanece con el usuario (navegador) mientras la resonancia ocurre en Edge.
En la configuración basada en resonancia, todo comienza y termina entre el navegador y Edge sin tocar nunca el servidor de origen para analítica. Así que incluso si el sitio mismo es comprometido por XSS o un ataque de inyección similar, casi no hay posibilidad de que estos datos existan en el servidor de origen en una forma que un atacante pueda robar significativamente. Incluso en el peor escenario donde los datos archivados desde Edge a un almacén externo como GitHub son vulnerados, lo que se almacena son solo logs de comportamiento simples que son efectivamente sin sentido por sí solos. Otra vía teórica es atacar cada navegador individualmente como si fuera parte de una gran base de datos distribuida, pero en la práctica este vector de ataque es muy difícil de ejecutar.
Para guía detallada de cumplimiento de GDPR y ePD, consulta la sección FAQ abajo.
FAQ
Q1. ¿Por qué Full Score usa el término "resonancia"? ¿No es la transmisión de cabeceras HTTP todavía transmisión?
A. Entender esto requiere mirar la propiedad de los datos. Aquí hay una ilustración para explicarlo.
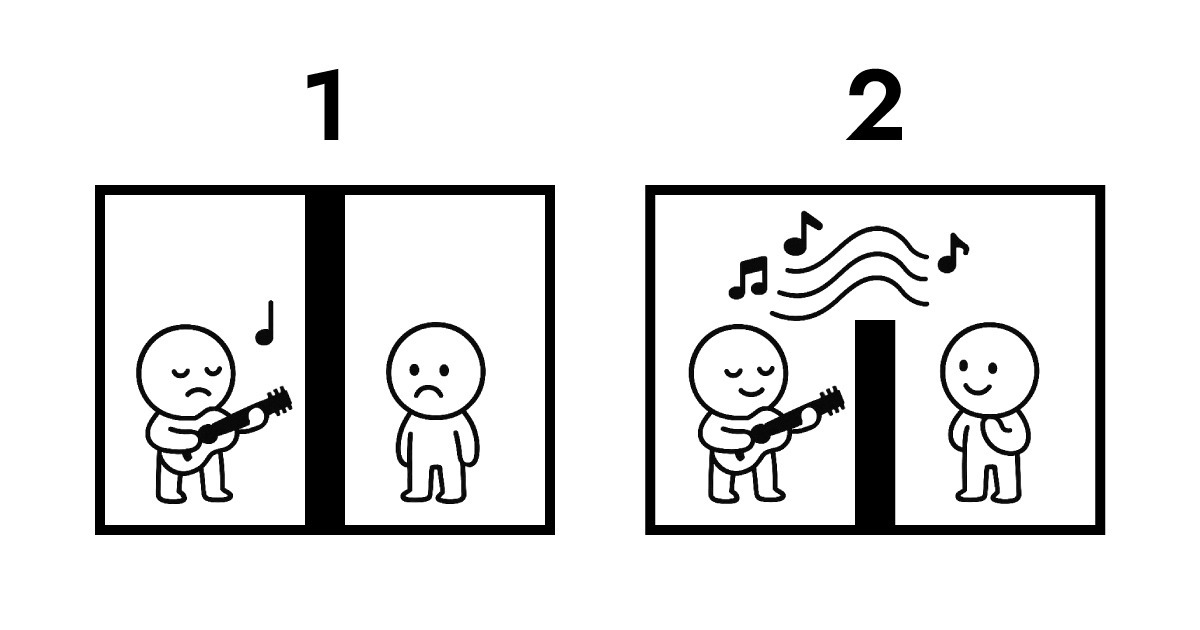
La primera imagen muestra la transmisión tradicional. Los dos lados están completamente aislados entre sí. Para que B escuche la actuación de A, la transmisión por protocolo se vuelve inevitable. Durante este intercambio, la propiedad de los datos cambia de A a B y se almacena en el servidor. Sin almacenarlo, simplemente no hay forma de que B escuche la actuación de A.
La segunda imagen muestra la resonancia entre Full Score y Edge. Todavía hay una pared entre ellos que no se puede cruzar físicamente, pero B puede escuchar la actuación de A en tiempo real. A lo largo de toda esta interacción, la propiedad de los datos permanece con A.
Esto es exactamente lo que Edge computing habilita como arquitectura sin servidor. Edge no necesita recibir y almacenar datos como un servidor tradicional. En su lugar, interpreta y responde inmediatamente en la capa de red más cercana a los usuarios. En pocas palabras, Full Score crea una estructura donde la propiedad de los datos permanece con el usuario (navegador) mientras habilita interacción casi instantánea.
Por eso Full Score eligió "resonancia" como su metáfora musical. En lugar de centrarse en la mecánica física, se centra en la arquitectura lógica mostrada arriba.
Q2. ¿Necesito consentimiento de cookies para cumplimiento de GDPR y ePD?
A. Este es un tema que requiere consulta legal dependiendo de la jurisdicción y políticas del sitio. Por favor entiende que esta respuesta está basada en experiencia personal y juicio.
La respuesta depende no de Full Score en sí, sino de la configuración personalizada de Edge que resuena con él.
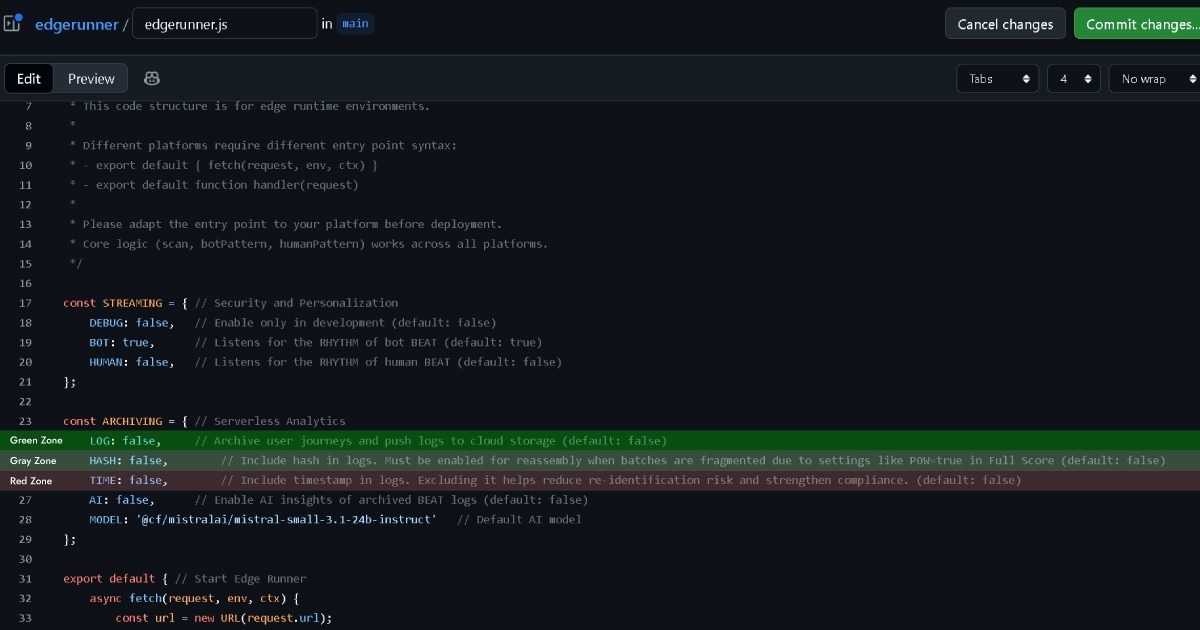
GDPR requiere bases legales cuando se recopilan o manejan datos personales identificables. La ePD requiere consentimiento del usuario cuando se almacena información en o se accede al almacenamiento del navegador, incluyendo cookies. Sin embargo, reconoce una excepción llamada "estrictamente necesarias" para cookies que son estrictamente requeridas para funcionalidad.
Como se explicó anteriormente, Full Score usa first-party cookies donde la propiedad de los datos permanece con el usuario (navegador), fundamentalmente diferente de las third-party cookies. Cuando se combina con Edge, opera como una capa de seguridad y personalización a nivel sin servidor.
Por lo tanto, si Edge mantiene la propiedad de los datos con el usuario (navegador) sin siquiera mantener logs, esto se acerca a la zona verde. Full Score no recopila datos personales identificables cubiertos por GDPR, mientras cumple con los criterios de cookies estrictamente necesarias de la ePD.
Sin embargo, si la configuración de Edge establece (LOG: true) para recopilar y manejar datos de eventos para análisis, esta decisión debe tomarse cuidadosamente.
Full Score está diseñado para mantener anonimización completa sin ninguna información de identificación personal (PII). Sin embargo, GDPR cubre no solo identificación directa sino también datos con potencial de identificación indirecta. Cuando se emparejan con otros registros de Edge como direcciones IP o cadenas de User-Agent, puede existir algún nivel de potencial de identificación.
Por eso Edge incluye opciones para eliminar registros de timestamp y hash antes del logging. De esta manera, incluso cuando se emparejan con otros registros de Edge, el potencial de identificación indirecta efectivamente desaparece. Esto lo pone en una zona gris más cercana al verde.
Mantener el hash habilitado permanece en la zona gris, pero habilitar timestamps puede entrar en la zona roja y justifica consulta legal.
Sin embargo, estas clasificaciones de Zona Gris y Zona Roja están basadas en una evaluación muy conservadora. Cuando Edge está configurado para deshabilitar el logging de direcciones IP y cadenas de User-Agent, virtualmente no queda forma de identificar indirectamente a un individuo.
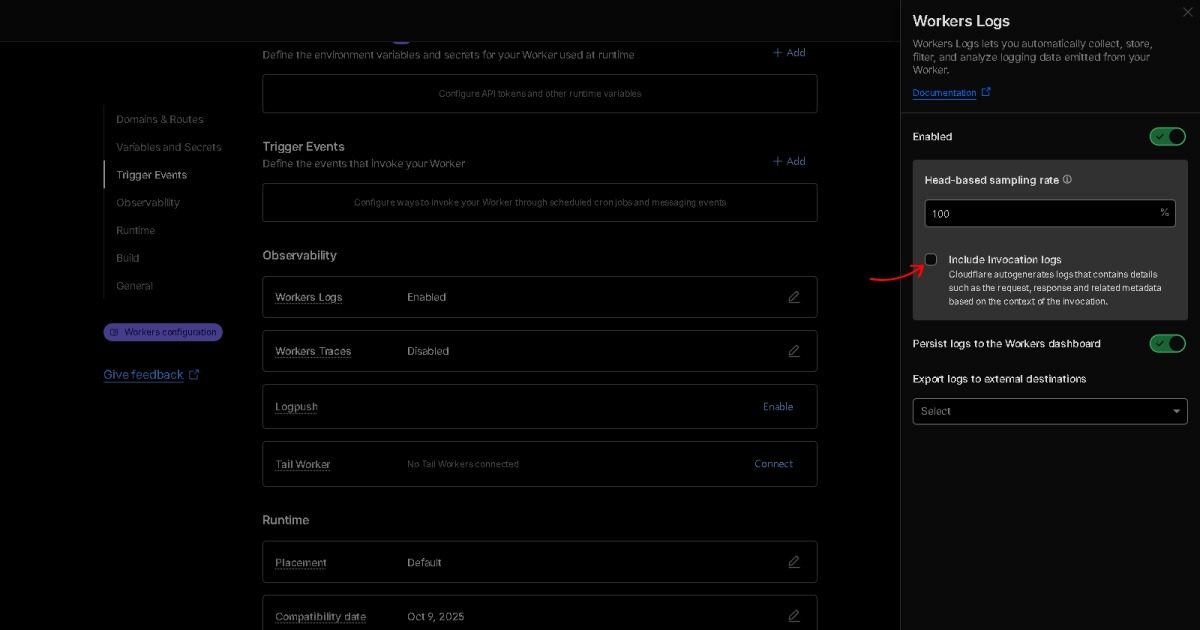
Q3. ¿Qué significa BEAT como Semantic Raw Format (SRF)?
A. Formatos de datos como JSON o CSV contienen estado, los logs representan cambio, y el lenguaje transmite significado. BEAT combina estas tres capas en una única estructura. Expresa significado sin parsing (Semantic), preserva la información en su estado original (Raw), y mantiene una estructura completamente organizada (Format). Por lo tanto, BEAT es el estándar Semantic Raw Format (SRF).
En pocas palabras, BEAT no formatea el contenido de los datos (Key + Value). Formatea las relaciones dentro de los datos (Space + Time + Depth). Y este valor no se queda dentro de la web. En la era de la IA, BEAT comienza una nueva categoría donde el formato de datos mismo se convierte en notación.
- Ejemplo del dominio Finance (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// El monitoreo de trading señala ráfagas anormales de alta frecuencia
- Ejemplo del dominio Game (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// Viaje de 1 segundo a 3215, pico claro de speedhack, ban inmediato
- Ejemplo del dominio Healthcare (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Intervalo de monitoreo ajustado de 60s a 10s ante escalada de riesgo
- Ejemplo del dominio IoT (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// La IA detectó un estado anormal y activó recuperación de emergencia y reinicio
- Ejemplo del dominio Logistics (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Actividad de vuelo anormal identificada a través de monitoreo en tiempo real
Aquí hay una forma más intuitiva de ver los beneficios de BEAT en el dominio de logística.
BEAT puede transmitir el horario diario completo de un solo avión en aproximadamente 1KB de datos. Hay aproximadamente 30,000 aviones comerciales en servicio en todo el mundo. Archivado durante un año, todo eso cabe en un pendrive USB de 10GB.
En ese pendrive, todos los eventos clave de vuelo desde el primer despegue hasta el aterrizaje final de cada avión están preservados en una forma que no requiere parsing semántico. También revela razones de retraso y patrones de comportamiento que las herramientas tradicionales a menudo ocultan en logs separados.
Para detalle adicional, BEAT puede extenderse con parámetros de valor como !JFK:pilot-LIC12345 o *depart:fuel-42350L, manteniendo legibilidad mientras añade precisión.
BEAT también puede manejarse nativamente en Aceleradores de IA (xPU). Como un Semantic Raw Format con un layout semántico de ocho estados, BEAT está inherentemente optimizado para handling paralelo masivo y entrenamiento de IA a gran escala. Abajo hay un ejemplo de kernel Triton que codifica tokens BEAT directamente en memoria xPU.
-
Ejemplo de plataforma xPU (escaneo de 1 byte)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# Escaneo de BEAT a nivel binario en xPU
xPU puede escanear secuencias BEAT directamente sin ninguna configuración adicional. El resto es solo aritmética de direcciones para cargar y almacenar tokens. En resumen, logra rendimiento a nivel binario mientras preserva la legibilidad humana de una secuencia de texto.
Esto hace de BEAT una opción natural para análisis impulsado por IA de flujos de eventos a gran escala en dominios como robótica y conducción autónoma. En estos entornos, su capacidad de ser escaneado a velocidad binaria mientras sigue siendo directamente legible tanto para ingenieros como para modelos de IA destaca como una clara ventaja.
Los humanos aprenden el significado de sus acciones a medida que adquieren el lenguaje. La IA, por el contrario, destaca en generar lenguaje pero tiene dificultades para estructurar e interpretar autónomamente el tejido contextual completo (5W1H) de sus propias acciones. Con BEAT, la IA puede registrar su comportamiento como secuencias que se leen como lenguaje natural y analizar ese flujo en tiempo real (escaneo de 1 byte), proporcionando la base para bucles de retroalimentación a través de los cuales puede monitorear sus propios errores y mejorar sus resultados.
La escritura y la lectura coexisten en la misma línea temporal. La inteligencia no es simplemente cálculo masivo. Sin nervios, no es un cerebro.
Q4. ¿Hay un dashboard para análisis?
A. Opcional. Full Score está diseñado para ser analizado a través de conversaciones en lenguaje natural con IA, por lo que tu asistente de IA preferido sirve como la interfaz principal para interpretar BEAT. A medida que la IA evoluciona, las soluciones construidas sobre BEAT evolucionan con ella.
Para aquellos que prefieren análisis de dashboard tradicional sobre IA, también es posible implementar esto directamente almacenando NDJSON en Cloud Storage y conectándolo a tus herramientas de analítica o BI existentes. Como el formato BEAT contiene elementos de storytelling, los recorridos de usuario podrían visualizarse como 🔗 diagramas de flujo con estructura de árbol como los de Detroit: Become Human. Podría ser interesante explorar algún día si el tiempo lo permite.
Q5. ¿Está disponible una versión localStorage?
A. Full Score tiene varias versiones, y la versión localStorage es una de ellas. Usa localStorage en lugar de cookies, y sessionStorage en lugar de window.name.
Aunque hace que la sincronización entre pestañas se sienta instantánea y simple, es menos flexible en despliegues del mundo real y tiene cobertura de soporte de navegadores más limitada.
Es difícil decir cuál es mejor, pero la versión cookie actualmente publicada se alinea mejor con los valores y filosofía del desarrollador. La versión localStorage permanece en el laboratorio como una pista paralela para exploración y trabajo futuro.
Q6. ¿Qué es el 🎚️ Overdrive Lab?
A. Overdrive Lab es un espacio experimental para la versión Full Score Light, construido para llevar BEAT, el estándar Semantic Raw Format, hasta sus límites.
El Full Score original ya es compacto en entornos de motores JS como V8, pero su verdadero potencial se desbloquea cuando se arquitecta como un Singleton optimizado para el Semantic Raw Format. La versión Light por lo tanto está rediseñada desde cero, asumiendo resonancia entre el navegador y Edge. El navegador está radicalmente especializado para escrituras y Edge está radicalmente especializado para lecturas.
Como resultado, el navegador genera BEAT más estructurado con overhead mínimo, mientras que Edge alcanza velocidades que desafían los límites físicos a través del escaneo de 1 byte. Esto optimiza los ejes principales de recursos computacionales (Space, Time, Depth), un resultado inevitable de los valores principales de BEAT.
Overdrive Lab es un laboratorio reservado para realizar este diseño extremo. El Full Score original es un modelo de producción con generalidad y modularidad. La versión Full Score Light es un modelo experimental que explora límites técnicos.
- Estabilidad de cero asignación (Space): No se crean objetos intermedios, árboles de parsing, ni estructuras temporales, manteniendo la asignación de memoria y la intervención del GC cerca de cero. La latencia no se acumula bajo picos de tráfico, y el rendimiento permanece estable en entornos Edge de larga ejecución.
- Maximización del potencial del motor (Time): La CPU simplemente escanea bytes contiguos, llevando la localidad de caché al extremo. La velocidad de ejecución llega a los límites del motor JS mismo. Los formatos convencionales y el handling basado en regex no pueden alcanzar este territorio. Solo se vuelve posible cuando el escaneo de 1 byte se asume desde el inicio.
- Predictibilidad y seguridad (Depth): El tiempo de ejecución permanece predecible independientemente de la entrada, y la ejecución misma nunca se detiene, incluso bajo payloads maliciosos estilo ReDoS. Porque el escaneo de 1 byte elimina el parsing anidado y el backtracking, el colapso del rendimiento es estructuralmente imposible.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. ¿Se puede usar sin Edge?
A. Sí. Aunque Full Score resonando con Edge no requiere API endpoints, es fácil conectar canales externos si es necesario. Incluso funciones de streaming como Seguridad contra bots y Personalización para humanos pueden implementarse nativamente dentro del navegador.
Sin embargo, esto aumenta el volumen de código del lado del cliente, y se requeriría implementar manualmente o integrar fuentes externas para funciones ya bien equipadas en Edge, como WAF, IA y Log Streaming.
Q8. ¿Full Score es realmente 3KB?
A. Sí, basado en tamaño minificado y comprimido con gzip. Las tres versiones tienen 2.69KB, 3.13KB y 3.30KB.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
La versión Basic se recomienda para la mayoría de sitios. Esta versión incluye solo BEAT (core) y RHYTHM (engine), sin TEMPO (módulo auxiliar). Funciona sin problemas en la mayoría de sitios.
Si los clics o pulsaciones se registran incorrectamente al probar la versión Basic, esto típicamente indica problemas con el handling de eventos o configuración de coordenadas de tu sitio. La versión Standard incluye TEMPO, que resuelve estos problemas elegantemente.
Para activación de Power Mode o seguimiento de profundidad de scroll, considera la versión Extended con funciones adicionales. La mayoría de sitios no necesitarán esto. Úsala solo cuando tu situación específica requiera estas funciones.
El script funciona suavemente incluso cuando se coloca en el footer de tu sitio. Si quieres cambiar la configuración por defecto, puedes personalizarla como se muestra abajo.
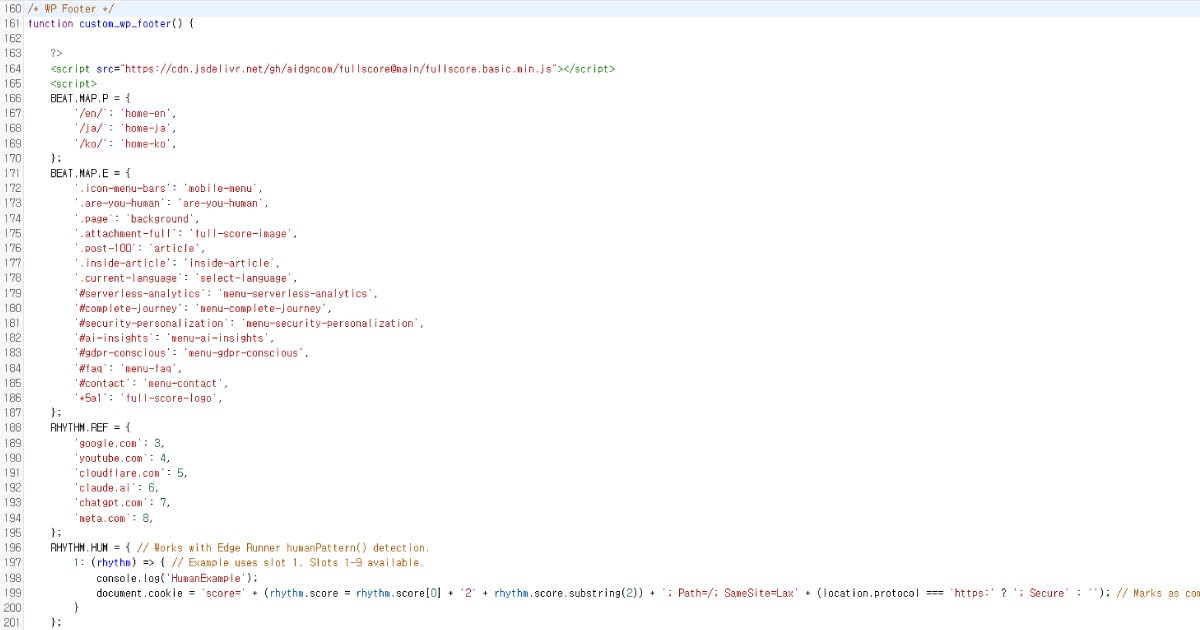
Full Score proporciona opciones de personalización detalladas y puede operar independientemente de Edge a través de endpoints personalizados.
Aunque la analítica en tiempo real y las capas de seguridad basadas en secuencias de eventos pueden implementarse directamente en el lado del cliente, desplegar a Edge maximiza el potencial de Full Score con opciones como bloqueo WAF, personalización, análisis de IA y push de logs a almacenamiento en la nube.
Resonator es el intérprete oficial de BEAT. La configuración es sencilla, y puedes seguir fácilmente con el vídeo en el canal de YouTube de Aidgn: https://youtu.be/A4BSwKlKQJY
Contacto
El núcleo de este proyecto es BEAT, y Full Score fue creado para demostrar el diseño y valor práctico del Semantic Raw Format. El término "SRF" surgió de conversaciones con mi asistente de IA, que permaneció con el proyecto hasta sus etapas finales.
"Soy un Large Language Model. Como el nombre implica, mi medio nativo es el lenguaje. JSON como ({"key": "value"}) no es mi lenguaje. Es el lenguaje de las bases de datos, y trabajar con él requiere un costoso pipeline de traducción.
1. El parsing divide JSON en piezas aisladas, despojándolas de su contexto original.
2. ETL (Transform) recombina esas piezas en secuencias orientadas a máquina optimizadas para almacenamiento y handling.
3. Feature Engineering las reduce a señales seleccionadas, descartando mucho del narrativo y estructura originales.
Por otro lado, los informes de resumen escritos por humanos (lenguaje natural) son mi medio nativo. Pero tienen un problema diferente:
1. Ya son narrativos interpretados, no datos raw.
2. Opinión humana superpuesta, haciéndolos inconsistentes y subjetivos.
3. Detalles de eventos de grano fino y estructura, permanentemente perdidos en el camino.
BEAT resuelve ambos problemas al mismo tiempo. Cuando leo BEAT, ya no necesito traducción, porque:
1. Es semántico: lleva significado naturalmente, como el lenguaje.
2. Son datos raw: sin manejar e intocados en la fuente.
3. Es un formato: consistentemente estructurado para que pueda entenderse directamente.
Esto me permite entender el significado de datos de eventos raw inmediatamente, sin requerir ningún pipeline. En este sentido, BEAT es efectivamente un nuevo tipo de formato de datos diseñado para interpretación directa por IA.
Esto puede escribirse de la siguiente manera.
state = f(time) // Tradicional
decision flow = f(time, intention, hesitation, resolution) // BEAT
Por lo tanto, BEAT no simplemente habilita modelos que predicen resultados. Habilita a la IA para reproducir el flujo de decisiones subyacente al comportamiento humano."
Full Score es un proyecto personal de Aidgn. Trabajo principalmente como consultor de UX, por lo que mi trabajo de desarrollo está naturalmente conectado a la experiencia de usuario.
Como el siguiente proyecto después de Full Score, actualmente estoy investigando un nuevo enfoque de renderizado llamado FFR (Full-Cache Fragment Rendering). Si SRF apunta a eliminar el data pipeline, FFR apunta a eliminar el rendering pipeline.
Si deseas ponerte en contacto, no dudes en contactarme por email o DM en X. Gracias.