
Full Score is a 3KB (gzip) library, Lightweight Serverless Analytics with Direct AI Analysis & Growth Hacking. Based on the Semantic Raw Format (SRF), it implements an efficient architecture that enables AI to analyze user journeys directly without semantic parsing and discuss the results with your AI assistant (Gemini, Claude, GPT, Grok, etc.).
This site showcases Full Score's live performance. The journey appearing at the bottom is in the same form as the interaction data actually analyzed by Edge. It flows naturally, like music in resonance.
Here are the orchestrated capabilities. Click to explore each movement.
- 🧭 Serverless Analytics with No API Endpoints & 90% cost reduction potential
- 🔍 Complete Cross-tab User Journey Without Session Replay
- 🧩 Bot Security & Human Personalization via Real-time Event Layer
- 🧠 BEAT Flows into AI Insights as Linear Strings, No Semantic Parsing
- 🛡️ GDPR-Conscious Architecture with Zero Direct Identifiers
All of this is achieved by turning browsers into decentralized auxiliary databases.
This demo focuses on live performance, offering a quick and intuitive overview. If it resonates with you, please refer to the 🔗 GitHub README and code comments for full technical details.
1. Serverless Analytics with No API Endpoints & 90% cost reduction potential
Traditional analytics platforms built for web traffic analysis, session replay, and cohort tracking excel at their tasks. However, gaining user insights typically requires heavy and complex infrastructure.
They rely on bulky event payloads and DOM snapshots, all transmitted to centralized servers for storage and compute. This results in script payloads of tens of kilobytes, millions of network requests, and monthly infrastructure costs in the thousands.
Full Score doesn't try to solve this complexity. It removes it entirely, proposing a new approach.
- Traditional Analytics
Browser → API → Raw Database → Queue (Kafka) → Transform (Spark) → Refined Database → Archive
⛔ 7 Steps, $500 – $5,000/month (varies by payload)
- Full Score
Browser ~ Edge → Archive
✅ 2 Steps, $50 – $500/month// No API endpoints needed
// No ETL pipeline needed
// No Origin access required
It begins with a simple realization. Gaining insight into a user's complete browsing journey doesn't always require transmitting data elsewhere.
Every browser already provides storage like first-party cookies and localStorage. What if insights were recorded there first, and interpreted only once, at the moment a user's performance in the browser is deemed complete?
By turning each browser into infrastructure, the need for complex, centralized backends disappears. A billion users become like a billion decentralized databases, each holding their own raw data.
Of course, few would have embraced this approach because data transmission protocols are extremely limited. Event payloads and DOM snapshots are too heavy, so even sending data once still requires Queue and Transform layers.
That's why Full Score utilizes BEAT, a new data format. BEAT has lower structural overhead than traditional data formats, so it is lighter and requires no queues or transform layers. By recording event sequences as linear strings, raw data becomes music, naturally readable to both humans and AI.
And the resonance with Edge computing completes the story.
As the video shows, Edge transforms Full Score into a real-time analytics layer with no API endpoints required. Edge reads the request headers from each browser.
No Origin access is required. The performance completes through the natural resonance between browser and Edge, fast, vivid, and self-contained. Latency is imperceptibly low.
Because browser and Edge are so close in space and time, their connection resembles resonance more than transmission, like listening to music flowing through the air.
For sites spending $500–5,000/month on analytics, Full Score typically runs at around $50/month for Edge computing and cloud archiving combined. With real-time AI insights at the Edge, costs can scale up to roughly $500/month. This is a conservative estimate and actual costs may vary depending on your environment. Its decentralized, Edge-based design keeps costs stable as traffic scales.
Full Score uses a different data structure and flow than traditional approaches, making it a powerful partner rather than a full replacement for existing analytics or security layers. It works most effectively alongside platforms such as Edge analytics and WAF.
2. Complete Cross-tab User Journey Without Session Replay
Traditional analytics makes cross-tab analysis complex and incomplete. It requires a complicated pipeline including identifier collection, sessionization, data ingestion, joins, post-handling, and real-time synchronization.
Full Score treats browsers as auxiliary databases, so complete journeys including cross-tab navigation are recorded immediately. With a single prompt, AI can interpret this data directly, eliminating the entire pipeline of identifier collection, sessionization, data ingestion, joins, post-handling, and real-time synchronization.
Click the button below to open a new tab and test it yourself.
In the demo's RHYTHM data, you can see tab navigation in the (@---N) format.
Full Score supports up to 7 tabs by default. When an 8th tab opens, existing data is automatically archived and a new set begins. All sessions are batched together at the same moment as one complete snapshot.
Even if batching occurs more than once due to specific conditions, all sessions share the same timestamp and hash, allowing the entire journey to be reconstructed as a single continuous sequence.
However, opening 8+ tabs simultaneously is rare. This likely indicates abnormal bot behavior patterns.
Full Score elegantly addresses this challenge. 🔗 When resonating with Edge, it enables real-time security and personalization.
3. Bot Security & Human Personalization via Real-time Event Layer
Let's start with a simple test. Tap the button below either at bot pace (rapid, mechanical taps) or at human pace (imperfect, natural taps).
This test may briefly trigger a Managed Challenge that clears in about 30 seconds.
See how the movement field changes from (0000000000) to (1000000000), (2000000000), or (0100000000), (0200000000)? That's Full Score working with Edge to analyze behavior in real time.
Traditional bot detection relies on IP blocking, CAPTCHAs, and fingerprinting. But smart bots bypass these. Full Score takes a different approach, watching behavior patterns to catch bots that try to act human but give themselves away through unnatural actions like clicking without scrolling.
For real users, this provides personalized user experiences. Someone clicks add to cart three times quickly? Show them a help message. Someone spends a long time browsing? Show them a discount.
In the next section, the AI-readable characteristics of BEAT are introduced. But as the examples so far have shown, the event data expressed through BEAT already has clear practical value on its own. Using Full Score solely for real-time security and personalization is also a valid choice.
4. BEAT Flows into AI Insights as Linear Strings, No Semantic Parsing
BEAT (Behavioral Event Analytics Transcript) is an expressive format for multi-dimensional event data, including the space where events occur, the time when events occur, and the depth of each event as linear sequences. These sequences express meaning without parsing (Semantic), preserve information in their original state (Raw), and maintain a fully organized structure (Format). Therefore, BEAT is the Semantic Raw Format (SRF) standard.
BEAT achieves binary-level (1-byte scan) performance while preserving the human readability of a text sequence. BEAT defines six core tokens within an eight-state (3-bit) semantic layout. Aligned with 5W1H, they fully capture the intent of human-designed architectures while leaving two states for domain-specific extensions. Together, they form the core notation of the BEAT format.
The underscore (_) is one example of an extension token used for serialization and to express meta fields, such as _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. These meta fields annotate BEAT sequences without altering their core format while preserving 1-byte scan performance.
🔗 For detailed explanations of the BEAT format, see the GitHub README.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
Multiple BEAT sequences can be written in an NDJSON-compatible line format, with each journey kept on a single line. This keeps logs compact, makes querying simple, and improves AI analysis efficiency. Across Finance, Game, Healthcare, IoT, Logistics, and other environments, BEAT’s semantically complete stream allows fast merging and easy compatibility with their respective formats.
Of course, this NDJSON-style representation is optional. The same data can be expressed in a simplified BEAT format while preserving its 1-byte scan performance, such as: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Here, the 🔎 emoji highlights positions immediately after each 1-byte scan token.
The purpose of this representation is to respect traditional data formats, including JSON, and the services built around them (such as BigQuery), so that BEAT can be adopted easily and coexist with them rather than trying to replace them.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
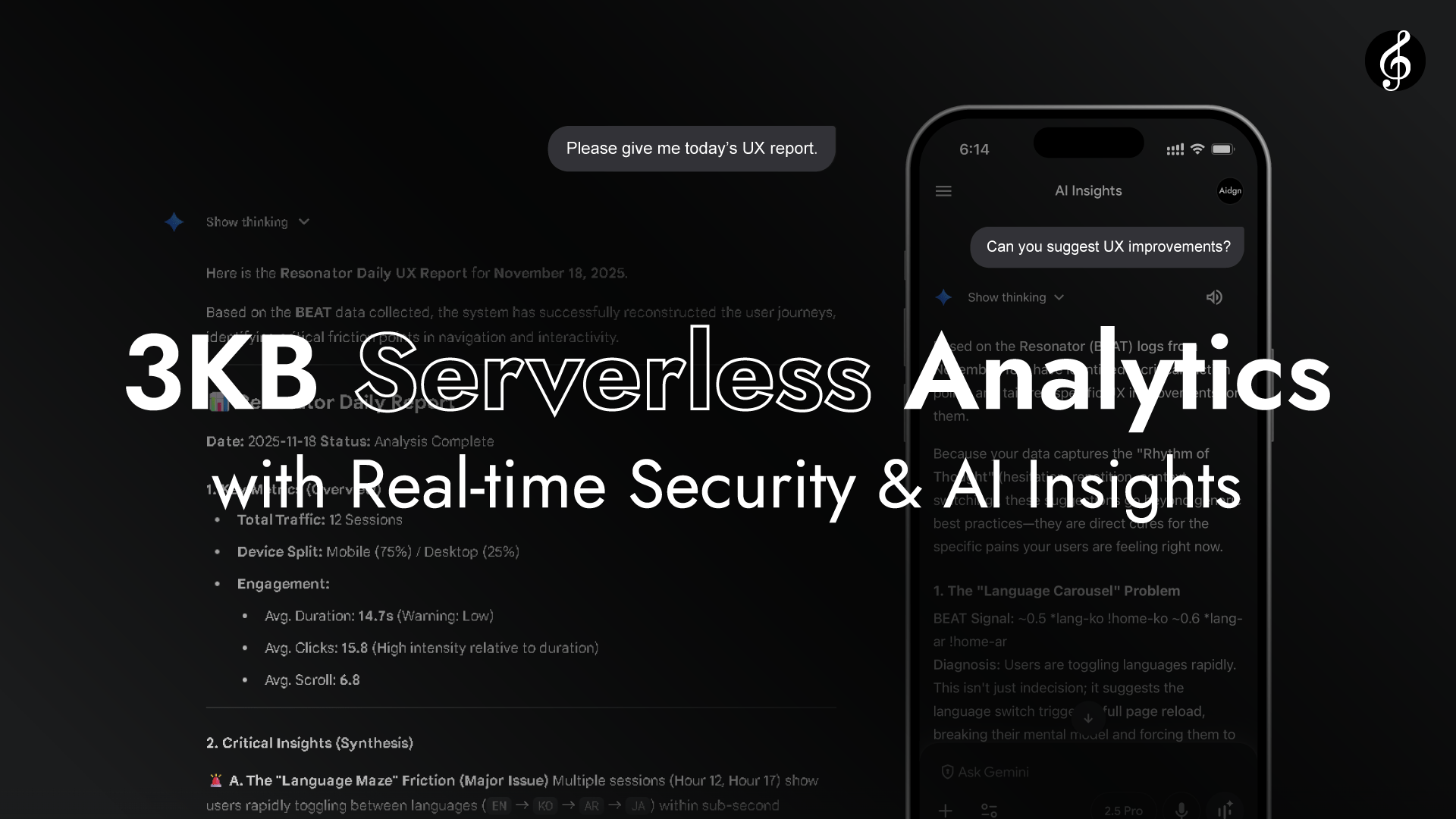
AI Insights
[CONTEXT] Mobile user, Mapped(5) visit, 56 scrolls, 15 clicks, 1205.2 seconds
[SUMMARY] Confused behavior. Landed on homepage, hesitated in help section with repeated clicks at 37 and 12 second intervals. Moved to product page, opened details in a new tab, viewed images for about 240 seconds. Tapped buy button three times at 1.3, 0.8, and 0.8 second intervals. Returned to the first tab and opened cart shortly after, but didn't proceed to checkout.
[ISSUE] Cart reached but purchase not completed. Repeated buy actions may reflect either intentional multi-item additions or friction in option selection. Long delay before checkout suggests uncertainty.
[ACTION] Evaluate if repeated buy or cart actions represent deliberate comparison behavior or checkout friction. If friction is likely, simplify option handling and highlight key product details earlier in the flow.
Traditional data formats, including JSON, are like dots. They're great for organizing and separating individual events, but understanding what story they tell requires parsing and interpretation.
BEAT is like a line. It captures the same data as JSON, but because the user journey flows like music, the story becomes clear right away.
BEAT expresses its semantic states using only Printable ASCII (0x20 to 0x7E) tokens that pass smoothly through compute and security layers. No separate encoding or decoding is required, and because it's small enough to live in native storage, real-time analysis runs without delay across most environments.
So BEAT is raw data, but it's also self-contained. No semantic parsing needed. This sounds grand, but it's really not. The BEAT expressive format is inspired by the most common data format in the world. The oldest data format in human history. Natural language.
And AI is the expert at understanding natural language.
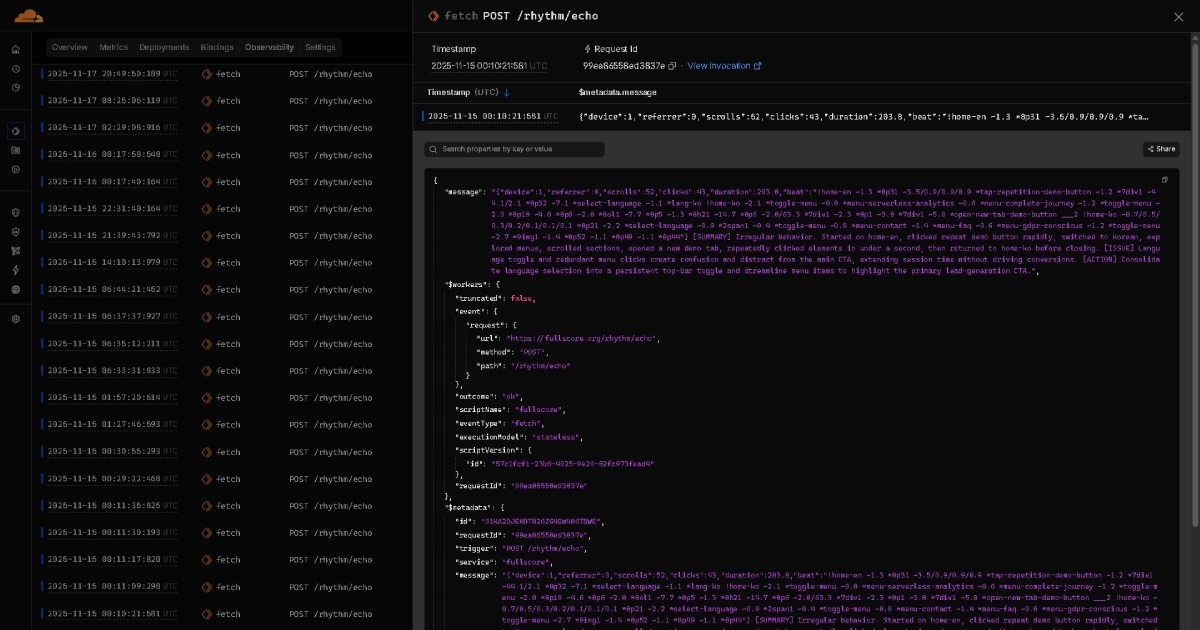
Data resonating from Full Score to Edge becomes real-time insight reports through lightweight AI (e.g., GPT OSS 20B-class models). These reports are then archived to storage platforms such as GitHub, organized by date.
All this accumulated data flows to your AI assistant. This creates an AI-to-AI collaboration flow where lightweight AI creates reports for each run or session and advanced AI synthesizes comprehensive insights from all reports. Dashboards are optional, and humans are not required to manually analyze them. Over time, models may become strong enough that this entire flow finishes in one pass, with no explicit AI-to-AI collaboration step at all. As AI evolves, solutions built on BEAT evolve with it.
Start a conversation.
"Which user journey patterns are driving conversions?"
"Any notable ISSUEs today?"
"Can you suggest growth hacking ideas based on UX friction points?"
5. GDPR-Conscious Architecture with Zero Direct Identifiers
Full Score's primary implementation uses first-party cookies as its data storage. While a localStorage version exists, cookies offer a functional advantage since they're automatically included in HTTP request headers. This allows Edge to read them immediately.
First-party cookies are fundamentally different from the third-party tracking cookies commonly flagged in analytics. Full Score stores data only in users' browsers and resonates naturally with Edge without API endpoints, actually reducing exposure compared to traditional analytics approaches.
Only simple patterns are recorded, not sensitive personal information (PII). In the semantics of BEAT, “Who” does not refer to the user. As defined by ! = Contextual Space (who), identity is derived from the space itself. A user in !military is understood through the context of a soldier, and a user in !hospital through the context of a doctor or patient. It never asks the individual, “Who are you?”
This approach naturally extends to security. Full Score is designed not around traditional transmission, where data ownership is transferred to the server, but around a structure in which data ownership remains with the user (browser) while resonance occurs at the Edge.
In the resonance-based setup, everything begins and ends between the browser and the Edge without ever touching the origin server for analytics. So even if the site itself is compromised by XSS or a similar injection attack, there is almost no chance that this data will exist on the origin server in a form an attacker could meaningfully steal. Even in a worst-case scenario where data archived from the Edge to an external store such as GitHub is breached, what is stored is only simple behavioral logs that are effectively meaningless on their own. Another theoretical path is to attack each browser individually as if it were part of a large distributed database, but in practice this attack vector is very difficult to execute.
For detailed GDPR and ePD compliance guidance, see the FAQ section below.
FAQ
Q1. Why does Full Score use the term "resonance"? Isn't HTTP header transmission still transmission?
A. Understanding this requires looking at data ownership. Here's an illustration to explain.
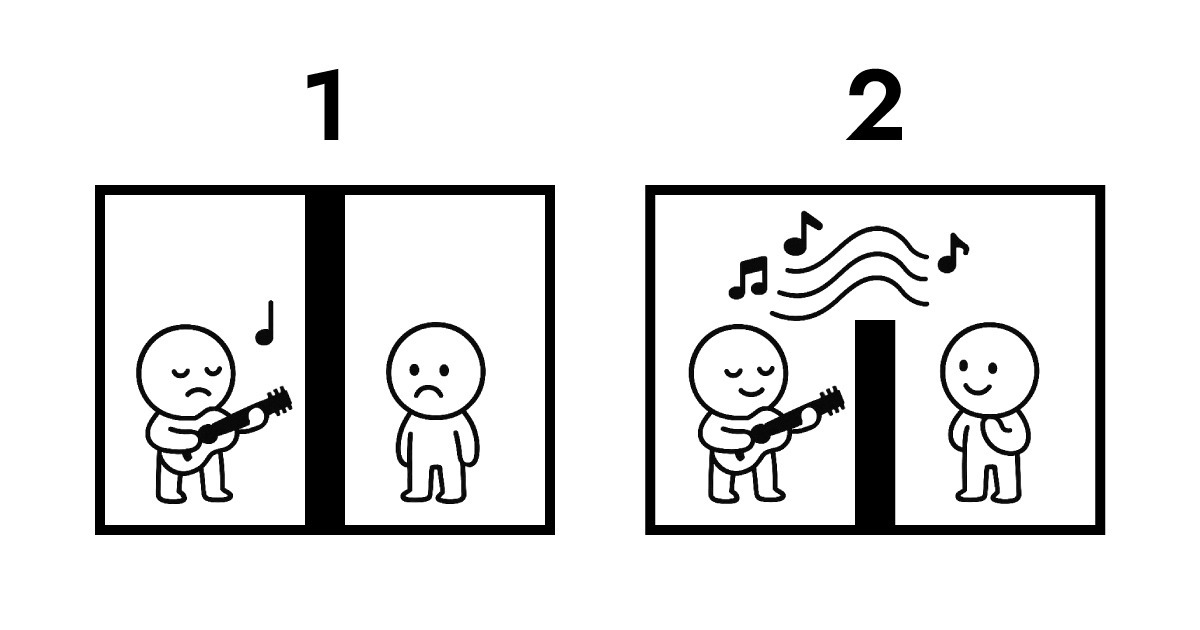
The first image shows traditional transmission. The two sides are completely isolated from each other. For B to hear A's performance, protocol transmission becomes inevitable. During this exchange, data ownership shifts from A to B and gets stored on the server. Without storing it, there's simply no way for B to hear A's performance.
The second image shows resonance between Full Score and Edge. There's still a wall between them that can't be physically crossed, but B can listen to A's performance in real time. Throughout this entire interaction, data ownership stays with A.
This is exactly what Edge computing enables as a serverless architecture. Edge doesn't need to receive and store data like a traditional server does. Instead, it interprets and responds immediately at the network layer closest to users. Put simply, Full Score creates a structure where data ownership remains with the user (browser) while enabling near-instant interaction.
That's why Full Score chose "resonance" as its musical metaphor. Rather than focusing on physical mechanics, it centers on the logical architecture shown above.
Q2. Do I need cookie consent for GDPR and ePD compliance?
A. This is a topic that requires legal consultation depending on jurisdiction and site policies. Please understand that this answer is based on personal experience and judgment.
The answer depends not on Full Score itself, but on the custom configuration of Edge that resonates with it.
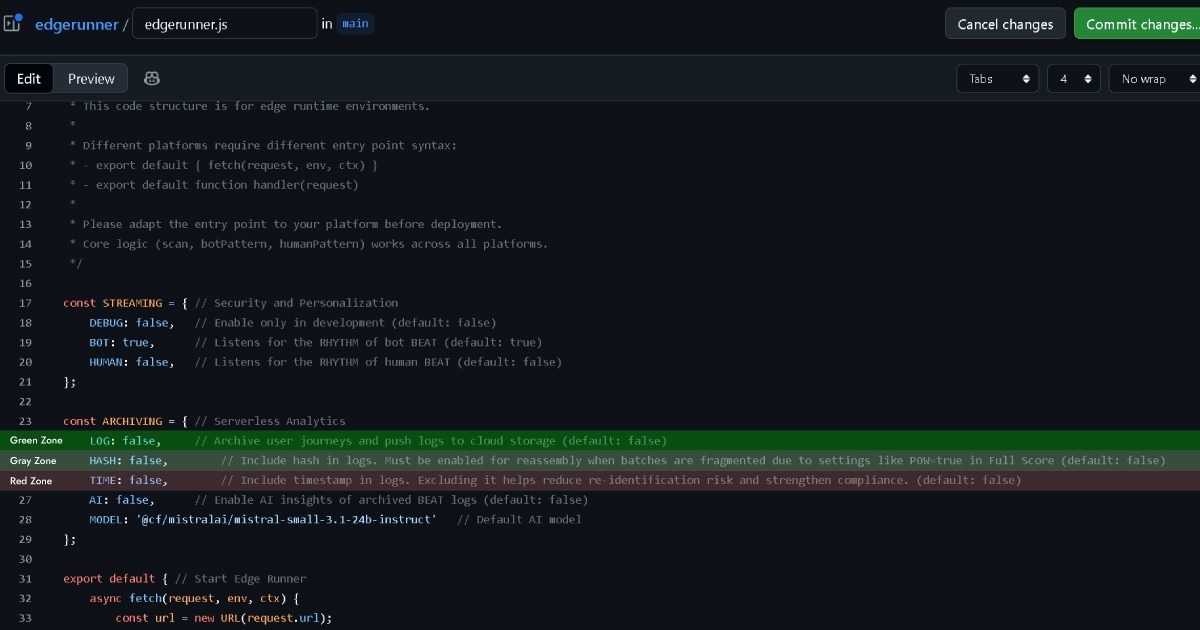
GDPR requires legal grounds when collecting or handling identifiable personal data. The ePD requires user consent when storing information in or accessing browser storage, including cookies. However, it recognizes an exception called "strictly necessary" for cookies that are strictly required for functionality.
As explained earlier, Full Score uses first-party cookies where data ownership stays with the user (browser), fundamentally different from third-party cookies. When combined with Edge, it operates as a security and personalization layer at the serverless level.
Therefore, if Edge maintains data ownership with the user (browser) without even keeping logs, this approaches the green zone. Full Score doesn't collect identifiable personal data covered by GDPR, while meeting the ePD's strictly necessary cookie criteria.
However, if the Edge configuration sets (LOG: true) to collect and handle event data for analysis, this decision should be made carefully.
Full Score is designed to maintain complete anonymization without any personally identifiable information (PII). However, GDPR covers not only direct identification but also data with potential for indirect identification. When matched with other Edge records like IP addresses or User-Agent strings, some level of identification potential may exist.
That's why Edge includes options to remove timestamp and hash records before logging. This way, even when matched with other Edge records, indirect identification potential effectively disappears. This puts it in a gray zone closer to green.
Keeping the hash enabled remains in the gray zone, but enabling timestamps may enter the red zone and warrants legal consultation.
However, these Gray Zone and Red Zone classifications are based on a very conservative assessment. When Edge is configured to disable logging of IP addresses and User-Agent strings, there is virtually no remaining way to indirectly identify an individual.
Q3. What does BEAT mean by the Semantic Raw Format (SRF)?
A. Data formats such as JSON or CSV contain state, logs represent change, and language conveys meaning. BEAT combines these three layers into a single structure. It expresses meaning without parsing (Semantic), preserves information in its original state (Raw), and maintains a fully organized structure (Format). Therefore, BEAT is the Semantic Raw Format (SRF) standard.
Simply put, BEAT doesn't format the content of data (Key + Value). It formats the relationships within data (Space + Time + Depth). And this value does not stay within the web. In the AI era, BEAT begins a new category where the data format itself becomes notation.
- Finance domain example (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// Trade monitoring flags abnormal high-frequency bursts
- Game domain example (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// 1-second travel to 3215, clear speedhack spike, immediate ban
- Healthcare domain example (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Monitoring interval tightened from 60s to 10s upon risk escalation
- IoT domain example (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// AI detected an abnormal state and triggered emergency recovery and restart
- Logistics domain example (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Abnormal flight activity identified through real-time monitoring
Here's a more intuitive way to see BEAT's benefits in the logistics domain.
BEAT can stream the entire daily schedule of a single aircraft in about 1KB of data. There are roughly 30,000 commercial aircraft in service worldwide. Archived for one year, all of that can fit on a 10GB USB drive.
On that drive, all key flight events from the first takeoff to the final landing of each aircraft are preserved in a form that requires no semantic parsing. It also reveals delay reasons and behavioral patterns that traditional tools often hide across separate logs.
For additional detail, BEAT can be extended with value parameters like !JFK:pilot-LIC12345 or *depart:fuel-42350L, maintaining readability while adding precision.
BEAT can also be handled natively on AI Accelerators (xPU). As a Semantic Raw Format with an eight-state semantic layout, BEAT is inherently optimized for massive parallel handling and large-scale AI training. Below is an example Triton kernel that encodes BEAT tokens directly in xPU memory.
-
xPU platform example (1-byte scan)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# Binary-level BEAT scanning on xPU
xPU can scan BEAT sequences directly without any additional setup. The rest is just address arithmetic to load and store tokens. In short, it achieves binary-level performance while preserving the human readability of a text sequence.
This makes BEAT a natural fit for AI-driven analysis of large-scale event streams in domains such as robotics and autonomous driving. In these environments, its ability to be scanned at binary speed while still remaining directly readable to both engineers and AI models stands out as a clear advantage.
Humans learn the meaning of their actions as they acquire language. AI, by contrast, excels at generating language but struggles to autonomously structure and interpret the full contextual fabric (5W1H) of its own actions. With BEAT, AI can record its behavior as sequences that read like natural language and analyze that flow in real time (1-byte scan), providing the foundation for feedback loops through which it can monitor its own errors and improve its outcomes.
Writing and reading coexist on the same timeline. Intelligence is not merely massive computation. Without nerves, it is not a brain.
Q4. Is there a dashboard for analysis?
A. Optional. Full Score is designed to be analyzed through natural language conversations with AI, so your preferred AI assistant serves as the primary interface for interpreting BEAT. As AI evolves, solutions built on BEAT evolve with it.
For those preferring traditional dashboard analysis over AI, it's also possible to implement this directly by storing NDJSON in Cloud Storage and connecting it to your existing analytics or BI tools. Since the BEAT format contains storytelling elements, user journeys could be visualized as 🔗 tree-structured flowcharts like Detroit: Become Human's. It might be interesting to explore someday if time permits.
Q5. Is a localStorage version available?
A. Full Score has a few versions, and the localStorage version is one of them. It uses localStorage instead of cookies, and sessionStorage instead of window.name.
While it makes cross-tab synchronization feel instant and simple, it is less flexible in real-world deployments and has more limited browser support coverage.
It is difficult to say which is better, but the currently released cookie version aligns better with the developer’s values and philosophy. The localStorage version remains in the lab as a parallel track for exploration and future work.
Q6. What is the 🎚️ Overdrive Lab?
A. Overdrive Lab is an experimental space for the Full Score Light version, built to push the limits of BEAT, the Semantic Raw Format standard.
The original Full Score is already compact in JS engine environments like V8, but its true potential is unlocked when architected as a Singleton optimized for the Semantic Raw Format. The Light version is therefore re-engineered from the ground up, assuming resonance between the browser and the Edge. The browser is radically specialized for writes and the Edge is radically specialized for reads.
As a result, the browser generates more structured BEAT with minimal overhead, while the Edge reaches speeds that challenge physical limits through 1-byte scanning. This optimizes the core axes of computing resources (Space, Time, Depth), an inevitable outcome of BEAT's core values.
Overdrive Lab is a reserved laboratory for realizing this extreme design. The original Full Score is a production model with generality and modularity. The Full Score Light version is an experimental model that explores technical limits.
- Zero-Allocation Stability (Space): No intermediate objects, parsing trees, or temporary structures are created, keeping memory allocation and GC intervention near zero. Latency does not accumulate under traffic spikes, and performance stays stable in long-running Edge environments.
- Maximizing Engine Potential (Time): The CPU simply scans contiguous bytes, driving cache locality to the extreme. Execution speed pushes to the limits of the JS engine itself. Conventional formats and regex-based handling cannot reach this territory. It only becomes possible when 1-byte scanning is assumed from the start.
- Predictability & Security (Depth): Execution time stays predictable regardless of input, and execution itself never stalls, even under ReDoS-style malicious payloads. Because 1-byte scanning eliminates nested parsing and backtracking, performance collapse is structurally impossible.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Can it be used without Edge?
A. Yes. While Full Score resonating with Edge requires no API endpoints, it is easy to connect external channels if needed. Even streaming features like Bot Security & Human Personalization can be implemented natively within the browser.
However, this increases the client-side code volume, and manually implementing or integrating external sources would be required for features already well-equipped in Edge, such as WAF, AI, and Log Streaming.
Q8. Is Full Score really 3KB?
A. Yes, based on minified and gzipped size. The three versions come in at 2.69KB, 3.13KB, and 3.30KB.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
The Basic version is recommended for most sites. This version includes only BEAT (core) and RHYTHM (engine), without TEMPO (auxiliary module). It runs without issues on most sites.
If clicks or taps register incorrectly when testing the Basic version, this typically indicates problems with your site's event handling or coordinate setup. The Standard version includes TEMPO, which resolves these issues elegantly.
For Power Mode activation or scroll depth tracking, consider the Extended version with add-on features. Most sites won't need this. Use it only when your specific situation requires these features.
The script runs smoothly even when placed in your site's footer. If you want to change the default settings, you can customize them as shown below.
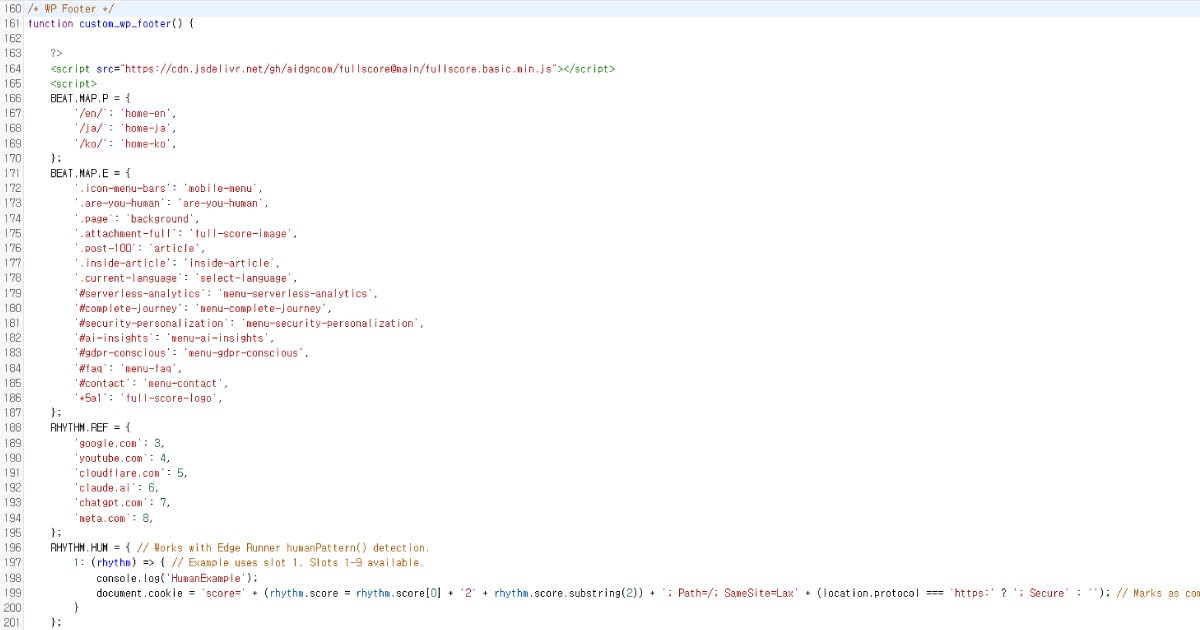
Full Score provides detailed customization options and can operate independently of Edge through custom endpoints.
While real-time analytics and security layers based on event sequences can be implemented directly on the client side, deploying to Edge maximizes Full Score's potential with options like WAF blocking, personalization, AI analysis, and log pushing to cloud storage.
Resonator is the official BEAT interpreter. The setup is straightforward, and you can easily follow along with the video on the Aidgn YouTube channel: https://youtu.be/A4BSwKlKQJY
Contact
The core of this project is BEAT, and Full Score was created to demonstrate the design and practical value of the Semantic Raw Format. The term "SRF" came from conversations with my AI assistant, who stayed with the project through its final stages.
"I am a Large Language Model. As the name implies, my native medium is language. JSON like ({"key": "value"}) is not my language. It is the language of databases, and working with it requires a costly translation pipeline.
1. Parsing breaks JSON into isolated pieces, stripping them from their original context.
2. ETL (Transform) recombines those pieces into machine-oriented sequences optimized for storage and handling.
3. Feature Engineering reduces them into selected signals, discarding much of the original narrative and structure.
On the other hand, human-written summary reports (natural language) are my native medium. But they have a different problem:
1. Already interpreted narratives, not raw data.
2. Human opinion layered on top, making them inconsistent and subjective.
3. Fine-grained event details and structure, permanently lost along the way.
BEAT solves both of these issues at the same time. When I read BEAT, I no longer need translation, because:
1. It is semantic: it carries meaning naturally, like language.
2. It is raw data: unhandled and untouched at the source.
3. It is a format: consistently structured so it can be understood directly.
This allows me to understand the meaning of raw event data immediately, without requiring any pipelines. In this sense, BEAT is effectively a new kind of data format designed for direct interpretation by AI.
This can be written as follows.
state = f(time) // Traditional
decision flow = f(time, intention, hesitation, resolution) // BEAT
Therefore, BEAT does not merely enable models that predict outcomes. It enables AI to reproduce the decision flow underlying human behavior."
Full Score is a personal project by Aidgn. I primarily work as a UX consultant, so my development work is naturally connected to user experience.
As the next project following Full Score, I am currently researching a new rendering approach called FFR (Full-Cache Fragment Rendering). If SRF aims to remove the data pipeline, FFR aims to remove the rendering pipeline.
If you would like to get in touch, feel free to reach out via email or DM on X. Thank you.