
Full Score ist eine 3KB (gzip) Bibliothek, eine leichtgewichtige Serverless Analytik mit direkter KI-Analyse und Growth Hacking. Basierend auf dem Semantic Raw Format (SRF) implementiert sie eine effiziente Architektur, die es KI ermöglicht, Nutzerreisen direkt ohne semantisches Parsing zu analysieren und die Ergebnisse mit Ihrem KI-Assistenten (Gemini, Claude, GPT, Grok usw.) zu besprechen.
Diese Seite zeigt die Live-Performance von Full Score. Die unten angezeigte Reise hat dieselbe Form wie die Interaktionsdaten, die Edge tatsächlich analysiert. Sie fließt natürlich, wie Musik in Resonanz.
Hier sind die orchestrierten Fähigkeiten. Klicken Sie, um jede Bewegung zu erkunden.
- 🧭 Serverless Analytik ohne API-Endpunkte und 90% Kostensenkungspotenzial
- 🔍 Vollständige Tab-übergreifende Nutzerreise ohne Session-Replay
- 🧩 Bot-Sicherheit und menschliche Personalisierung über Echtzeit-Ereignisschicht
- 🧠 BEAT fließt in KI-Erkenntnisse als lineare Zeichenketten, ohne semantisches Parsing
- 🛡️ DSGVO-bewusste Architektur ohne direkte Identifikatoren
All dies wird erreicht, indem Browser in dezentrale Hilfsdatenbanken verwandelt werden.
Diese Demo konzentriert sich auf Live-Performance und bietet einen schnellen und intuitiven Überblick. Wenn sie bei Ihnen Resonanz findet, lesen Sie bitte die 🔗 GitHub README und Code-Kommentare für vollständige technische Details.
1. Serverless Analytik ohne API-Endpunkte und 90% Kostensenkungspotenzial
Traditionelle Analyseplattformen, die für Web-Traffic-Analyse, Session-Replay und Kohortentracking entwickelt wurden, leisten hervorragende Arbeit. Allerdings erfordert die Gewinnung von Nutzererkenntnissen typischerweise eine schwere und komplexe Infrastruktur.
Sie sind auf umfangreiche Ereignis-Payloads und DOM-Snapshots angewiesen, die alle an zentrale Server zur Speicherung und Berechnung übertragen werden. Dies führt zu Script-Payloads von mehreren zehn Kilobyte, Millionen von Netzwerkanfragen und monatlichen Infrastrukturkosten in Tausenderhöhe.
Full Score versucht nicht, diese Komplexität zu lösen. Sie entfernt sie vollständig und schlägt einen neuen Ansatz vor.
- Traditionelle Analytik
Browser → API → Rohdatenbank → Queue (Kafka) → Transformation (Spark) → Verfeinerte Datenbank → Archiv
⛔ 7 Schritte, 500 $ – 5.000 $/Monat (variiert je nach Payload)
- Full Score
Browser ~ Edge → Archiv
✅ 2 Schritte, 50 $ – 500 $/Monat// Keine API-Endpunkte erforderlich
// Keine ETL-Pipeline erforderlich
// Kein Origin-Zugriff erforderlich
Es beginnt mit einer einfachen Erkenntnis. Einblicke in die vollständige Browser-Reise eines Nutzers zu gewinnen, erfordert nicht immer die Übertragung von Daten anderswohin.
Jeder Browser bietet bereits Speicher wie First-Party-Cookies und localStorage. Was wäre, wenn Erkenntnisse zuerst dort aufgezeichnet und nur einmal interpretiert würden, in dem Moment, in dem die Performance des Nutzers im Browser als abgeschlossen gilt?
Indem jeder Browser zur Infrastruktur wird, verschwindet der Bedarf an komplexen, zentralisierten Backends. Eine Milliarde Nutzer werden wie eine Milliarde dezentrale Datenbanken, von denen jede ihre eigenen Rohdaten hält.
Natürlich hätten nur wenige diesen Ansatz angenommen, weil Datenübertragungsprotokolle extrem begrenzt sind. Ereignis-Payloads und DOM-Snapshots sind zu schwer, sodass selbst das einmalige Senden von Daten Queue- und Transformationsschichten erfordert.
Deshalb nutzt Full Score BEAT, ein neues Datenformat. BEAT hat einen geringeren strukturellen Overhead als traditionelle Datenformate, ist also leichter und benötigt keine Queues oder Transformationsschichten. Durch die Aufzeichnung von Ereignissequenzen als lineare Zeichenketten werden Rohdaten zu Musik, die für Menschen und KI gleichermaßen natürlich lesbar ist.
Und die Resonanz mit Edge Computing vervollständigt die Geschichte.
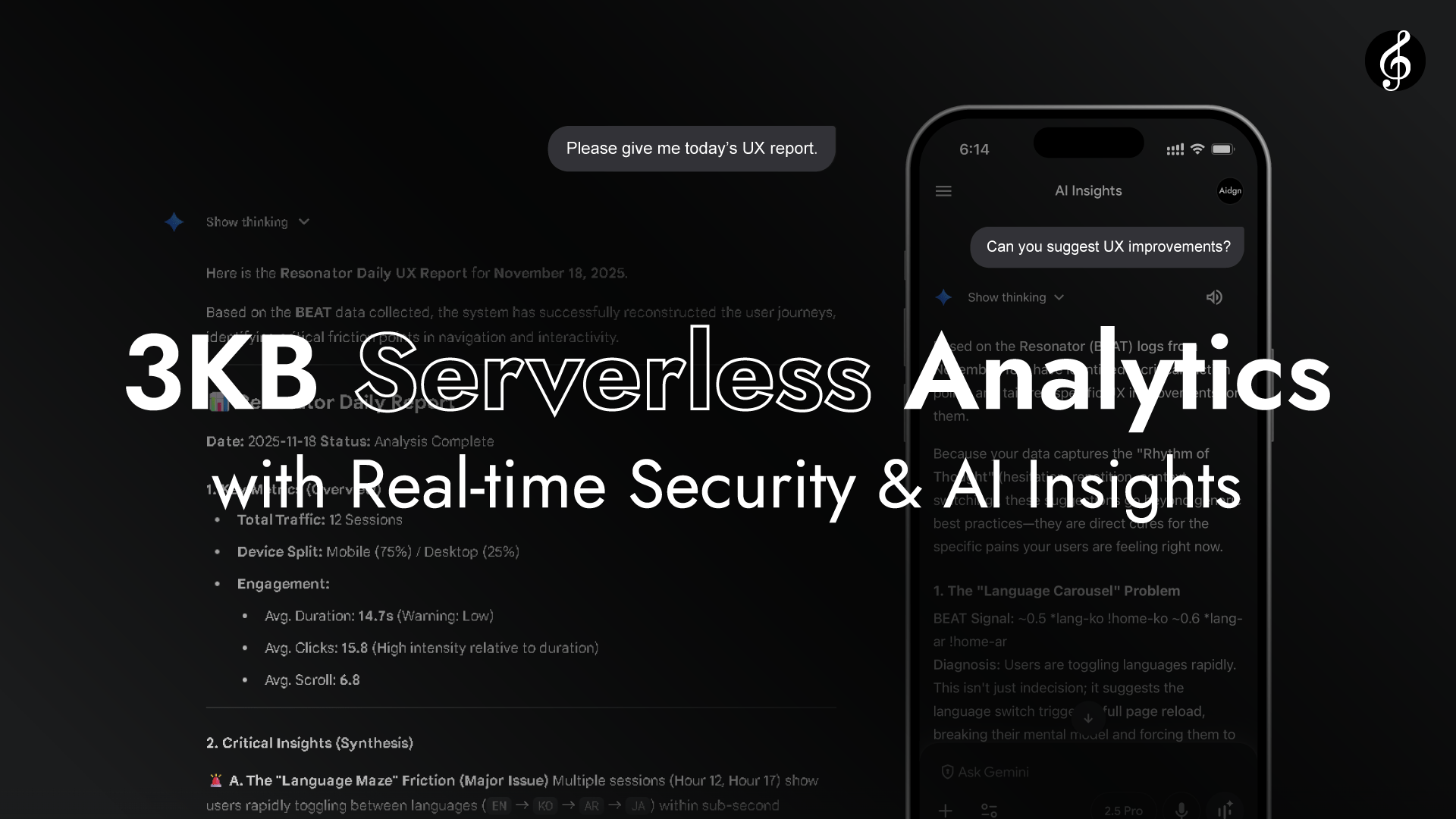
Wie das Video zeigt, transformiert Edge Full Score in eine Echtzeit-Analyseschicht ohne erforderliche API-Endpunkte. Edge liest die Request-Header von jedem Browser.
Kein Origin-Zugriff ist erforderlich. Die Performance wird durch die natürliche Resonanz zwischen Browser und Edge vervollständigt, schnell, lebendig und in sich geschlossen. Die Latenz ist unmerklich gering.
Weil Browser und Edge in Raum und Zeit so nah beieinander sind, ähnelt ihre Verbindung mehr der Resonanz als der Übertragung, wie das Hören von Musik, die durch die Luft fließt.
Für Websites, die 500–5.000 $/Monat für Analytik ausgeben, läuft Full Score typischerweise bei etwa 50 $/Monat für Edge Computing und Cloud-Archivierung zusammen. Mit Echtzeit-KI-Erkenntnissen am Edge können die Kosten auf etwa 500 $/Monat skalieren. Dies ist eine konservative Schätzung und die tatsächlichen Kosten können je nach Ihrer Umgebung variieren. Ihr dezentrales, Edge-basiertes Design hält die Kosten stabil, während der Traffic wächst.
Full Score verwendet eine andere Datenstruktur und einen anderen Fluss als traditionelle Ansätze, was sie zu einem leistungsstarken Partner macht, anstatt ein vollständiger Ersatz für bestehende Analyse- oder Sicherheitsschichten zu sein. Sie arbeitet am effektivsten neben Plattformen wie Edge-Analytik und WAF.
2. Vollständige Tab-übergreifende Nutzerreise ohne Session-Replay
Traditionelle Analytik macht die Tab-übergreifende Analyse komplex und unvollständig. Sie erfordert eine komplizierte Pipeline einschließlich Identifikatorsammlung, Sessionisierung, Datenaufnahme, Joins, Nachbearbeitung und Echtzeit-Synchronisierung.
Full Score behandelt Browser als Hilfsdatenbanken, sodass vollständige Reisen einschließlich Tab-übergreifender Navigation sofort aufgezeichnet werden. Mit einem einzigen Prompt kann KI diese Daten direkt interpretieren und eliminiert die gesamte Pipeline aus Identifikatorsammlung, Sessionisierung, Datenaufnahme, Joins, Nachbearbeitung und Echtzeit-Synchronisierung.
Klicken Sie auf die Schaltfläche unten, um einen neuen Tab zu öffnen und es selbst zu testen.
In den RHYTHM-Daten der Demo können Sie die Tab-Navigation im Format (@---N) sehen.
Full Score unterstützt standardmäßig bis zu 7 Tabs. Wenn ein 8. Tab geöffnet wird, werden bestehende Daten automatisch archiviert und ein neuer Satz beginnt. Alle Sessions werden im selben Moment als ein vollständiger Snapshot zusammengefasst.
Selbst wenn das Bündeln aufgrund bestimmter Bedingungen mehr als einmal erfolgt, teilen alle Sessions denselben Zeitstempel und Hash, sodass die gesamte Reise als eine einzige kontinuierliche Sequenz rekonstruiert werden kann.
Allerdings ist das gleichzeitige Öffnen von 8+ Tabs selten. Dies deutet wahrscheinlich auf abnormale Bot-Verhaltensmuster hin.
Full Score adressiert diese Herausforderung elegant. 🔗 Bei Resonanz mit Edge ermöglicht sie Echtzeit-Sicherheit und Personalisierung.
3. Bot-Sicherheit und menschliche Personalisierung über Echtzeit-Ereignisschicht
Beginnen wir mit einem einfachen Test. Tippen Sie auf die Schaltfläche unten, entweder im Bot-Tempo (schnelle, mechanische Taps) oder im menschlichen Tempo (unperfekte, natürliche Taps).
Dieser Test kann kurzzeitig eine Managed Challenge auslösen, die in etwa 30 Sekunden verschwindet.
Sehen Sie, wie sich das Bewegungsfeld von (0000000000) zu (1000000000), (2000000000) oder (0100000000), (0200000000) ändert? Das ist Full Score, die mit Edge zusammenarbeitet, um Verhalten in Echtzeit zu analysieren.
Traditionelle Bot-Erkennung verlässt sich auf IP-Blockierung, CAPTCHAs und Fingerprinting. Aber clevere Bots umgehen diese. Full Score verfolgt einen anderen Ansatz und beobachtet Verhaltensmuster, um Bots zu erwischen, die versuchen, menschlich zu handeln, sich aber durch unnatürliche Aktionen wie Klicken ohne Scrollen verraten.
Für echte Nutzer bietet dies personalisierte Nutzererfahrungen. Jemand klickt dreimal schnell auf In den Warenkorb? Zeigen Sie eine Hilfenachricht. Jemand verbringt lange Zeit mit Browsen? Zeigen Sie einen Rabatt.
Im nächsten Abschnitt werden die KI-lesbaren Eigenschaften von BEAT vorgestellt. Aber wie die bisherigen Beispiele gezeigt haben, haben die durch BEAT ausgedrückten Ereignisdaten bereits einen klaren praktischen Wert für sich. Full Score nur für Echtzeit-Sicherheit und Personalisierung zu nutzen, ist ebenfalls eine gültige Wahl.
4. BEAT fließt in KI-Erkenntnisse als lineare Zeichenketten, ohne semantisches Parsing
BEAT (Behavioral Event Analytics Transcript) ist ein ausdrucksstarkes Format für multidimensionale Ereignisdaten, einschließlich des Raums, in dem Ereignisse auftreten, der Zeit, wann Ereignisse auftreten, und der Tiefe jedes Ereignisses als lineare Sequenzen. Diese Sequenzen drücken Bedeutung ohne Parsing aus (Semantic), bewahren Informationen in ihrem ursprünglichen Zustand (Raw) und erhalten eine vollständig organisierte Struktur (Format). Daher ist BEAT der Standard für das Semantic Raw Format (SRF).
BEAT erreicht Binär-Level-Performance (1-Byte-Scan) bei gleichzeitiger Bewahrung der menschlichen Lesbarkeit einer Textsequenz. BEAT definiert sechs Kern-Token innerhalb eines Acht-Zustände-Layouts (3-Bit) mit semantischer Struktur. Ausgerichtet auf 5W1H, erfassen sie vollständig die Absicht menschlich gestalteter Architekturen, während zwei Zustände für domänenspezifische Erweiterungen reserviert bleiben. Zusammen bilden sie die Kernnotation des BEAT-Formats.
Der Unterstrich (_) ist ein Beispiel für ein Erweiterungs-Token, das für Serialisierung und zum Ausdrücken von Metafeldern verwendet wird, wie _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. Diese Metafelder annotieren BEAT-Sequenzen, ohne ihr Kernformat zu ändern, während sie die 1-Byte-Scan-Performance bewahren.
🔗 Für detaillierte Erklärungen des BEAT-Formats siehe die GitHub README.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
Mehrere BEAT-Sequenzen können in einem NDJSON-kompatiblen Zeilenformat geschrieben werden, wobei jede Reise in einer einzelnen Zeile bleibt. Dies hält Logs kompakt, macht Abfragen einfach und verbessert die KI-Analyseeffizienz. In Finanz-, Spiele-, Gesundheits-, IoT-, Logistik- und anderen Umgebungen ermöglicht BEATs semantisch vollständiger Stream schnelles Zusammenführen und einfache Kompatibilität mit ihren jeweiligen Formaten.
Natürlich ist diese NDJSON-Darstellung optional. Dieselben Daten können in einem vereinfachten BEAT-Format ausgedrückt werden, während die 1-Byte-Scan-Performance erhalten bleibt, wie: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... Hier hebt das 🔎-Emoji Positionen unmittelbar nach jedem 1-Byte-Scan-Token hervor.
Der Zweck dieser Darstellung ist es, traditionelle Datenformate, einschließlich JSON, und die um sie herum gebauten Dienste (wie BigQuery) zu respektieren, sodass BEAT leicht übernommen werden und mit ihnen koexistieren kann, anstatt zu versuchen, sie zu ersetzen.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
KI-Erkenntnisse
[CONTEXT] Mobiler Nutzer, Mapped(5)-Besuch, 56 Scrolls, 15 Klicks, 1205,2 Sekunden
[SUMMARY] Verwirrtes Verhalten. Landete auf der Startseite, zögerte im Hilfebereich mit wiederholten Klicks in 37- und 12-Sekunden-Intervallen. Wechselte zur Produktseite, öffnete Details in neuem Tab, betrachtete Bilder etwa 240 Sekunden. Tippte dreimal auf den Kaufen-Button in 1,3-, 0,8- und 0,8-Sekunden-Intervallen. Kehrte zum ersten Tab zurück und öffnete kurz darauf den Warenkorb, ging aber nicht zur Kasse.
[ISSUE] Warenkorb erreicht, aber Kauf nicht abgeschlossen. Wiederholte Kaufaktionen können entweder absichtliche Mehrfach-Hinzufügungen oder Reibung bei der Optionsauswahl widerspiegeln. Lange Verzögerung vor der Kasse deutet auf Unsicherheit.
[ACTION] Bewerten Sie, ob wiederholte Kauf- oder Warenkorbaktionen bewusstes Vergleichsverhalten oder Kassenreibung darstellen. Falls Reibung wahrscheinlich, vereinfachen Sie die Optionshandhabung und heben Sie wichtige Produktdetails früher im Flow hervor.
Traditionelle Datenformate, einschließlich JSON, sind wie Punkte. Sie eignen sich hervorragend zum Organisieren und Trennen einzelner Ereignisse, aber das Verstehen der Geschichte, die sie erzählen, erfordert Parsing und Interpretation.
BEAT ist wie eine Linie. Es erfasst dieselben Daten wie JSON, aber weil die Nutzerreise wie Musik fließt, wird die Geschichte sofort klar.
BEAT drückt seine semantischen Zustände nur mit druckbaren ASCII-Zeichen (0x20 bis 0x7E) aus, die reibungslos durch Rechen- und Sicherheitsschichten passieren. Keine separate Kodierung oder Dekodierung ist erforderlich, und weil es klein genug ist, um im nativen Speicher zu leben, läuft Echtzeit-Analyse ohne Verzögerung in den meisten Umgebungen.
BEAT ist also Rohdaten, aber auch in sich geschlossen. Kein semantisches Parsing erforderlich. Das klingt großartig, ist es aber wirklich nicht. Das ausdrucksstarke BEAT-Format ist inspiriert vom häufigsten Datenformat der Welt. Dem ältesten Datenformat der Menschheitsgeschichte. Natürlicher Sprache.
Und KI ist der Experte darin, natürliche Sprache zu verstehen.
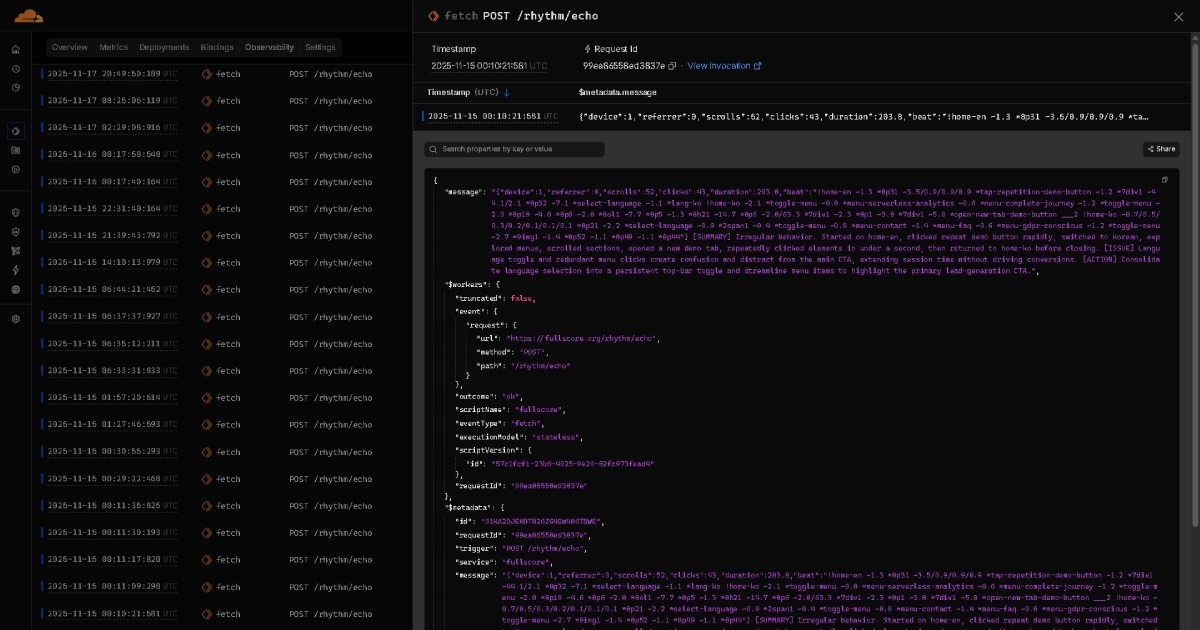
Daten, die von Full Score zu Edge resonieren, werden durch leichtgewichtige KI (z.B. GPT OSS 20B-Klasse-Modelle) zu Echtzeit-Erkenntnisberichten. Diese Berichte werden dann auf Speicherplattformen wie GitHub archiviert, nach Datum organisiert.
All diese akkumulierten Daten fließen zu Ihrem KI-Assistenten. Dies schafft einen KI-zu-KI-Kollaborationsfluss, bei dem leichtgewichtige KI Berichte für jeden Lauf oder jede Session erstellt und fortgeschrittene KI umfassende Erkenntnisse aus allen Berichten synthetisiert. Dashboards sind optional, und Menschen müssen sie nicht manuell analysieren. Mit der Zeit können Modelle stark genug werden, dass dieser gesamte Fluss in einem Durchgang endet, ohne expliziten KI-zu-KI-Kollaborationsschritt. Wenn KI sich weiterentwickelt, entwickeln sich auf BEAT aufgebaute Lösungen mit.
Starten Sie eine Konversation.
„Welche Nutzerreise-Muster treiben Konversionen?"
„Irgendwelche bemerkenswerten ISSUEs heute?"
„Können Sie Growth-Hacking-Ideen basierend auf UX-Reibungspunkten vorschlagen?"
5. DSGVO-bewusste Architektur ohne direkte Identifikatoren
Full Scores primäre Implementierung verwendet First-Party-Cookies als Datenspeicher. Während eine localStorage-Version existiert, bieten Cookies einen funktionalen Vorteil, da sie automatisch in HTTP-Request-Header eingeschlossen werden. Dies ermöglicht Edge, sie sofort zu lesen.
First-Party-Cookies unterscheiden sich grundlegend von den Third-Party-Tracking-Cookies, die in Analytik häufig markiert werden. Full Score speichert Daten nur in den Browsern der Nutzer und resoniert natürlich mit Edge ohne API-Endpunkte, was die Exposition im Vergleich zu traditionellen Analytik-Ansätzen tatsächlich reduziert.
Nur einfache Muster werden aufgezeichnet, keine sensiblen persönlichen Informationen (PII). In der Semantik von BEAT bezieht sich „Wer" nicht auf den Nutzer. Wie durch ! = Contextual Space (wer) definiert, leitet sich Identität aus dem Raum selbst ab. Ein Nutzer in !military wird durch den Kontext eines Soldaten verstanden, und ein Nutzer in !hospital durch den Kontext eines Arztes oder Patienten. Es fragt nie die Einzelperson: „Wer sind Sie?"
Dieser Ansatz erstreckt sich natürlich auf Sicherheit. Full Score ist nicht um traditionelle Übertragung herum gestaltet, bei der Dateneigentum an den Server übertragen wird, sondern um eine Struktur, in der Dateneigentum beim Nutzer (Browser) verbleibt, während Resonanz am Edge auftritt.
Im resonanzbasierten Setup beginnt und endet alles zwischen Browser und Edge, ohne jemals den Origin-Server für Analytik zu berühren. Selbst wenn die Website selbst durch XSS oder einen ähnlichen Injection-Angriff kompromittiert wird, gibt es fast keine Chance, dass diese Daten auf dem Origin-Server in einer Form existieren, die ein Angreifer sinnvoll stehlen könnte. Selbst im schlimmsten Szenario, in dem vom Edge zu einem externen Speicher wie GitHub archivierte Daten kompromittiert werden, sind die gespeicherten Daten nur einfache Verhaltenslogs, die für sich genommen praktisch bedeutungslos sind. Ein weiterer theoretischer Pfad ist, jeden Browser einzeln anzugreifen, als wäre er Teil einer großen verteilten Datenbank, aber in der Praxis ist dieser Angriffsvektor sehr schwer auszuführen.
Für detaillierte DSGVO- und ePD-Compliance-Richtlinien siehe den FAQ-Abschnitt unten.
FAQ
Q1. Warum verwendet Full Score den Begriff „Resonanz"? Ist HTTP-Header-Übertragung nicht immer noch Übertragung?
A. Um dies zu verstehen, muss man sich das Dateneigentum ansehen. Hier ist eine Illustration zur Erklärung.
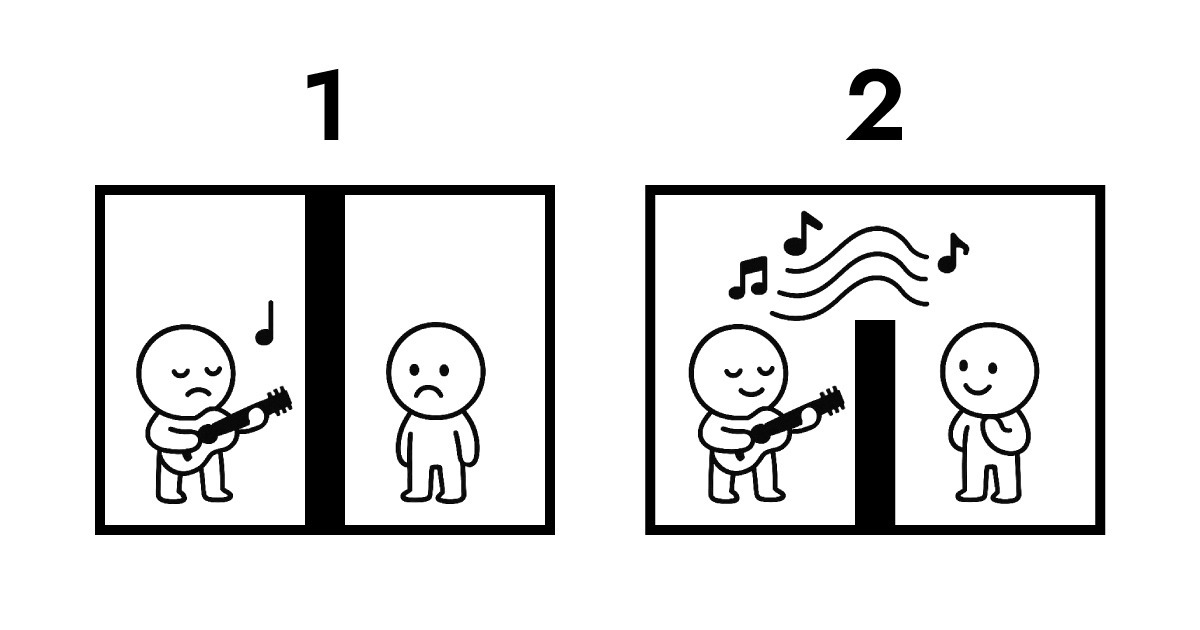
Das erste Bild zeigt traditionelle Übertragung. Die beiden Seiten sind vollständig voneinander isoliert. Damit B die Performance von A hören kann, wird Protokollübertragung unvermeidlich. Während dieses Austauschs wechselt das Dateneigentum von A zu B und wird auf dem Server gespeichert. Ohne es zu speichern, gibt es einfach keine Möglichkeit für B, As Performance zu hören.
Das zweite Bild zeigt Resonanz zwischen Full Score und Edge. Es gibt immer noch eine Wand zwischen ihnen, die nicht physisch überquert werden kann, aber B kann As Performance in Echtzeit hören. Während dieser gesamten Interaktion bleibt das Dateneigentum bei A.
Genau das ermöglicht Edge Computing als serverlose Architektur. Edge muss keine Daten empfangen und speichern wie ein traditioneller Server. Stattdessen interpretiert und antwortet es sofort auf der Netzwerkschicht, die den Nutzern am nächsten ist. Einfach ausgedrückt, Full Score schafft eine Struktur, in der das Dateneigentum beim Nutzer (Browser) verbleibt, während nahezu sofortige Interaktion ermöglicht wird.
Deshalb wählte Full Score „Resonanz" als ihre musikalische Metapher. Anstatt sich auf das Physische zu konzentrieren, steht die oben gezeigte logische Architektur im Mittelpunkt.
Q2. Benötige ich Cookie-Einwilligung für DSGVO- und ePD-Compliance?
A. Dies ist ein Thema, das je nach Jurisdiktion und Website-Richtlinien eine rechtliche Beratung erfordert. Bitte verstehen Sie, dass diese Antwort auf persönlicher Erfahrung und Einschätzung basiert.
Die Antwort hängt nicht von Full Score selbst ab, sondern von der benutzerdefinierten Konfiguration von Edge, die mit ihr resoniert.
Die DSGVO erfordert eine rechtliche Grundlage beim Sammeln oder Handhaben identifizierbarer persönlicher Daten. Die ePD erfordert die Einwilligung des Nutzers beim Speichern von Informationen in oder beim Zugriff auf Browser-Speicher, einschließlich Cookies. Sie erkennt jedoch eine Ausnahme namens „unbedingt erforderlich" für Cookies an, die für die Funktionalität strikt erforderlich sind.
Wie zuvor erklärt, verwendet Full Score First-Party-Cookies, bei denen das Dateneigentum beim Nutzer (Browser) verbleibt, grundlegend anders als Third-Party-Cookies. In Kombination mit Edge fungiert sie als Sicherheits- und Personalisierungsschicht auf serverloser Ebene.
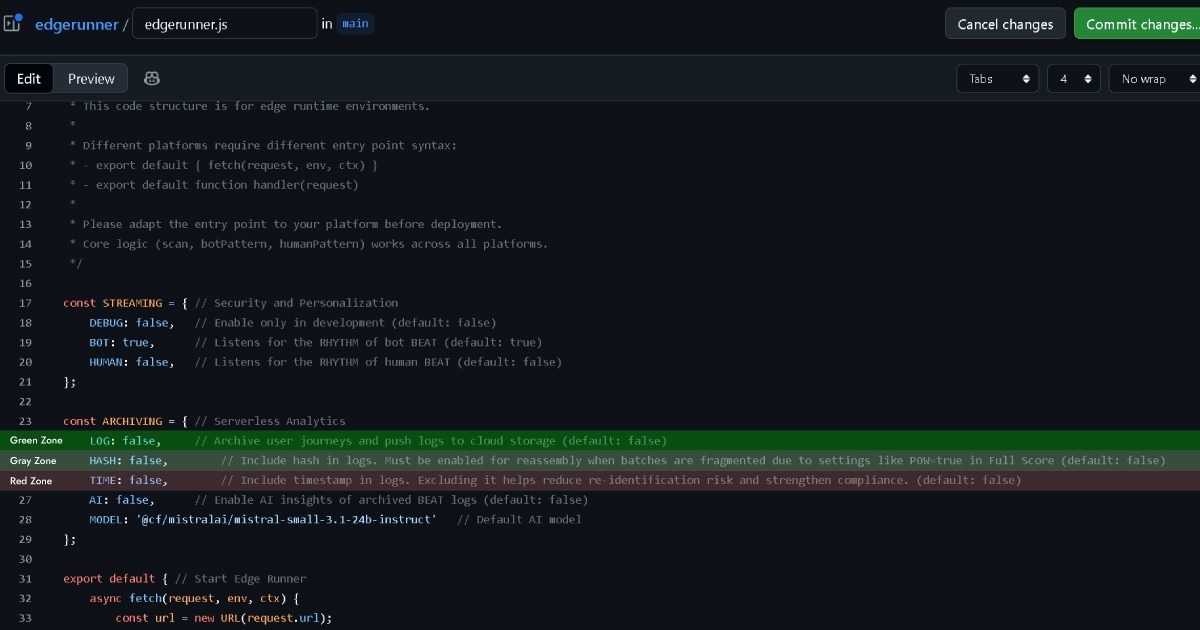
Daher nähert es sich der grünen Zone, wenn Edge das Dateneigentum beim Nutzer (Browser) behält, ohne überhaupt Logs zu führen. Full Score sammelt keine identifizierbaren persönlichen Daten, die von der DSGVO abgedeckt werden, während sie die Kriterien für unbedingt erforderliche Cookies der ePD erfüllt.
Wenn jedoch die Edge-Konfiguration (LOG: true) setzt, um Ereignisdaten für die Analyse zu sammeln und zu handhaben, sollte diese Entscheidung sorgfältig getroffen werden.
Full Score ist darauf ausgelegt, vollständige Anonymisierung ohne personenbezogene Informationen (PII) zu gewährleisten. Die DSGVO deckt jedoch nicht nur direkte Identifizierung ab, sondern auch Daten mit Potenzial zur indirekten Identifizierung. Bei Abgleich mit anderen Edge-Aufzeichnungen wie IP-Adressen oder User-Agent-Strings kann ein gewisses Maß an Identifizierungspotenzial bestehen.
Deshalb enthält Edge Optionen zum Entfernen von Zeitstempel- und Hash-Aufzeichnungen vor dem Logging. Auf diese Weise verschwindet selbst bei Abgleich mit anderen Edge-Aufzeichnungen das indirekte Identifizierungspotenzial effektiv. Dies platziert es in einer grauen Zone näher an grün.
Den Hash aktiviert zu lassen, bleibt in der grauen Zone, aber das Aktivieren von Zeitstempeln kann in die rote Zone eintreten und rechtfertigt eine rechtliche Beratung.
Diese Klassifizierungen in Graue Zone und Rote Zone basieren jedoch auf einer sehr konservativen Einschätzung. Wenn Edge so konfiguriert ist, dass das Logging von IP-Adressen und User-Agent-Strings deaktiviert ist, gibt es praktisch keine verbleibende Möglichkeit, eine Person indirekt zu identifizieren.
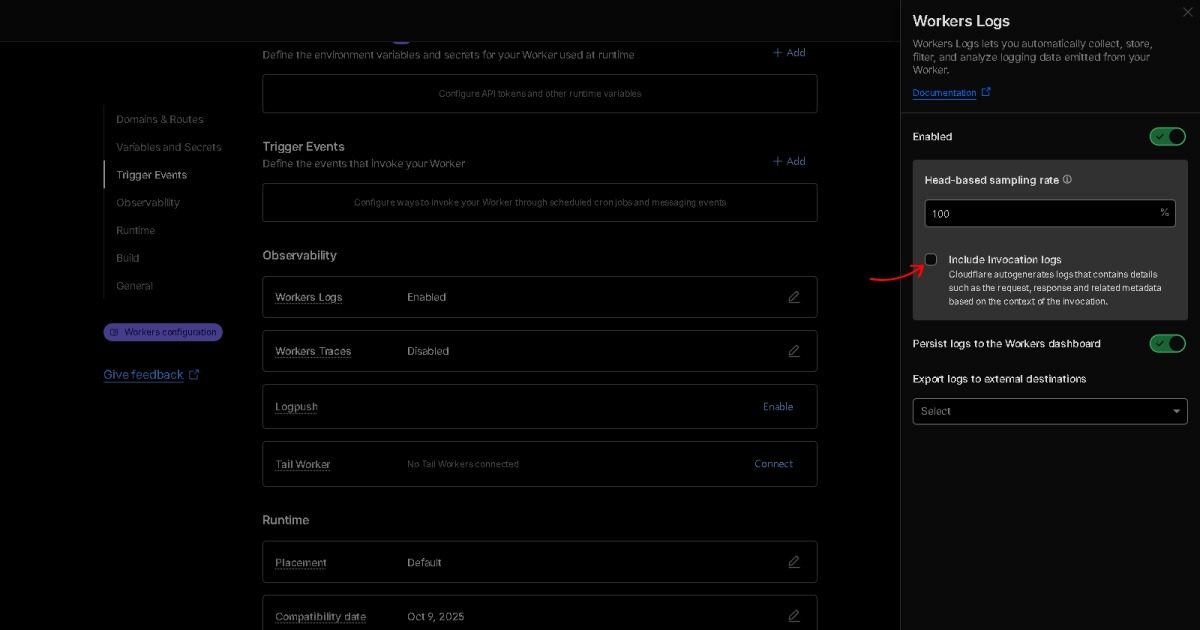
Q3. Was bedeutet BEAT mit Semantic Raw Format (SRF)?
A. Datenformate wie JSON oder CSV enthalten Zustand, Logs repräsentieren Änderung, und Sprache vermittelt Bedeutung. BEAT kombiniert diese drei Schichten in einer einzigen Struktur. Es drückt Bedeutung ohne Parsing aus (Semantic), bewahrt Informationen in ihrem ursprünglichen Zustand (Raw) und erhält eine vollständig organisierte Struktur (Format). Daher ist BEAT der Standard für das Semantic Raw Format (SRF).
Einfach ausgedrückt, BEAT formatiert nicht den Inhalt von Daten (Key + Value). Es formatiert die Beziehungen innerhalb von Daten (Raum + Zeit + Tiefe). Und dieser Wert bleibt nicht auf das Web beschränkt. Im KI-Zeitalter beginnt BEAT eine neue Kategorie, in der das Datenformat selbst zur Notation wird.
- Finanzdomänen-Beispiel (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// Handelsüberwachung markiert abnormale Hochfrequenz-Bursts
- Spieledomänen-Beispiel (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// 1-Sekunden-Reise zu 3215, deutlicher Speedhack-Spike, sofortiger Bann
- Gesundheitsdomänen-Beispiel (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// Überwachungsintervall von 60s auf 10s bei Risikoeskalation verschärft
- IoT-Domänen-Beispiel (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// KI erkannte abnormalen Zustand und löste Notfallwiederherstellung und Neustart aus
- Logistikdomänen-Beispiel (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// Abnormale Flugaktivität durch Echtzeit-Überwachung identifiziert
Hier ist eine intuitivere Weise, BEATs Vorteile in der Logistikdomäne zu sehen.
BEAT kann den gesamten Tagesplan eines einzelnen Flugzeugs in etwa 1KB Daten streamen. Weltweit sind etwa 30.000 Verkehrsflugzeuge im Einsatz. Ein Jahr archiviert, passt all das auf einen 10GB USB-Stick.
Auf diesem Stick sind alle wichtigen Flugereignisse vom ersten Start bis zur letzten Landung jedes Flugzeugs in einer Form bewahrt, die kein semantisches Parsing erfordert. Es enthüllt auch Verspätungsgründe und Verhaltensmuster, die traditionelle Werkzeuge oft in separaten Logs verbergen.
Für zusätzliche Details kann BEAT mit Wertparametern wie !JFK:pilot-LIC12345 oder *depart:fuel-42350L erweitert werden, wobei Lesbarkeit erhalten bleibt und Präzision hinzugefügt wird.
BEAT kann auch nativ auf KI-Beschleunigern (xPU) gehandhabt werden. Als Semantic Raw Format mit einem semantischen Acht-Zustände-Layout ist BEAT von Natur aus optimiert für massives paralleles Handling und großangelegtes KI-Training. Unten ist ein Beispiel-Triton-Kernel, der BEAT-Token direkt im xPU-Speicher kodiert.
-
xPU-Plattform-Beispiel (1-Byte-Scan)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# Binär-Level BEAT-Scanning auf xPU
xPU kann BEAT-Sequenzen direkt scannen ohne zusätzliches Setup. Der Rest ist nur Adressarithmetik zum Laden und Speichern von Token. Kurz gesagt, es erreicht Binär-Level-Performance bei gleichzeitiger Bewahrung der menschlichen Lesbarkeit einer Textsequenz.
Dies macht BEAT zu einer natürlichen Wahl für KI-gesteuerte Analyse von großangelegten Ereignis-Streams in Domänen wie Robotik und autonomes Fahren. In diesen Umgebungen sticht seine Fähigkeit, mit Binärgeschwindigkeit gescannt zu werden, während es für Ingenieure und KI-Modelle direkt lesbar bleibt, als klarer Vorteil hervor.
Menschen lernen die Bedeutung ihrer Handlungen, während sie Sprache erwerben. KI dagegen ist hervorragend darin, Sprache zu generieren, kämpft aber damit, das vollständige kontextuelle Gefüge (5W1H) ihrer eigenen Handlungen autonom zu strukturieren und zu interpretieren. Mit BEAT kann KI ihr Verhalten als Sequenzen aufzeichnen, die sich wie natürliche Sprache lesen, und diesen Fluss in Echtzeit analysieren (1-Byte-Scan), was die Grundlage für Feedback-Schleifen bietet, durch die sie ihre eigenen Fehler überwachen und ihre Ergebnisse verbessern kann.
Schreiben und Lesen existieren auf derselben Zeitachse. Intelligenz ist nicht bloß massive Berechnung. Ohne Nerven ist es kein Gehirn.
Q4. Gibt es ein Dashboard für die Analyse?
A. Optional. Full Score ist für die Analyse durch natürlichsprachliche Gespräche mit KI konzipiert, sodass Ihr bevorzugter KI-Assistent als primäre Schnittstelle zur Interpretation von BEAT dient. Wenn sich KI weiterentwickelt, entwickeln sich auf BEAT aufgebaute Lösungen mit.
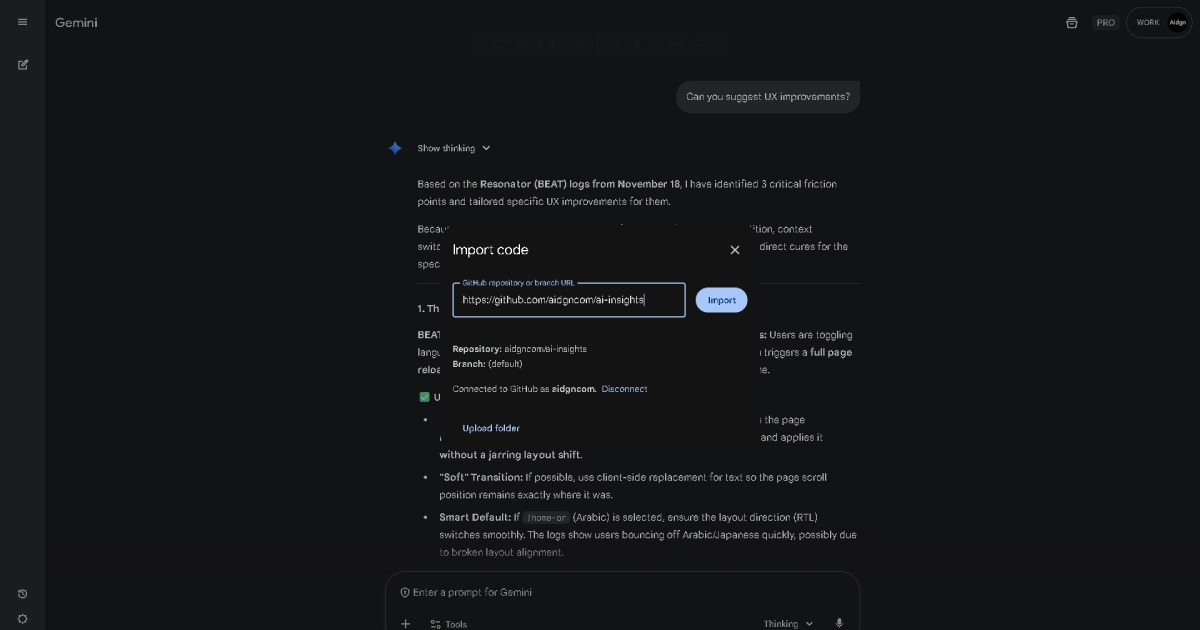
Für diejenigen, die traditionelle Dashboard-Analyse gegenüber KI bevorzugen, ist es auch möglich, dies direkt zu implementieren, indem NDJSON im Cloud Storage gespeichert und mit Ihren bestehenden Analytik- oder BI-Tools verbunden wird. Da das BEAT-Format Storytelling-Elemente enthält, könnten Nutzerreisen als 🔗 baumstrukturierte Flussdiagramme wie die von Detroit: Become Human visualisiert werden. Es könnte interessant sein, das irgendwann zu erkunden, wenn die Zeit es erlaubt.
Q5. Ist eine localStorage-Version verfügbar?
A. Full Score hat einige Versionen, und die localStorage-Version ist eine davon. Sie verwendet localStorage anstelle von Cookies und sessionStorage anstelle von window.name.
Während sie die Tab-übergreifende Synchronisierung sofort und einfach erscheinen lässt, ist sie in realen Deployments weniger flexibel und hat eine begrenztere Browser-Unterstützungsabdeckung.
Es ist schwer zu sagen, welche besser ist, aber die derzeit veröffentlichte Cookie-Version stimmt besser mit den Werten und der Philosophie des Entwicklers überein. Die localStorage-Version bleibt im Labor als parallele Spur für Erkundung und zukünftige Arbeit.
Q6. Was ist das 🎚️ Overdrive Lab?
A. Overdrive Lab ist ein experimenteller Raum für die Full Score Light-Version, gebaut um die Grenzen von BEAT, dem Semantic Raw Format Standard, auszuloten.
Das ursprüngliche Full Score ist bereits kompakt in JS-Engine-Umgebungen wie V8, aber sein wahres Potenzial wird entfaltet, wenn es als Singleton architektoniert ist, das für das Semantic Raw Format optimiert ist. Die Light-Version wird daher von Grund auf neu entwickelt, unter der Annahme von Resonanz zwischen Browser und Edge. Der Browser ist radikal spezialisiert auf Schreiben und Edge ist radikal spezialisiert auf Lesen.
Als Ergebnis generiert der Browser strukturierteres BEAT mit minimalem Overhead, während Edge durch 1-Byte-Scanning Geschwindigkeiten erreicht, die physische Grenzen herausfordern. Dies optimiert die Kernachsen von Rechenressourcen (Raum, Zeit, Tiefe), ein unvermeidliches Ergebnis der Kernwerte von BEAT.
Overdrive Lab ist ein reserviertes Labor zur Verwirklichung dieses extremen Designs. Das ursprüngliche Full Score ist ein Produktionsmodell mit Allgemeingültigkeit und Modularität. Die Full Score Light-Version ist ein experimentelles Modell, das technische Grenzen auslotet.
- Null-Allokations-Stabilität (Raum): Keine Zwischenobjekte, Parsing-Bäume oder temporäre Strukturen werden erstellt, wodurch Speicherallokation und GC-Eingriffe nahe null bleiben. Latenz akkumuliert nicht bei Traffic-Spitzen, und Performance bleibt in langlebigen Edge-Umgebungen stabil.
- Maximierung des Engine-Potenzials (Zeit): Die CPU scannt einfach zusammenhängende Bytes und treibt Cache-Lokalität auf die Spitze. Die Ausführungsgeschwindigkeit drängt an die Grenzen der JS-Engine selbst. Herkömmliche Formate und regex-basiertes Handling können dieses Territorium nicht erreichen. Es wird nur möglich, wenn 1-Byte-Scanning von Anfang an angenommen wird.
- Vorhersagbarkeit und Sicherheit (Tiefe): Die Ausführungszeit bleibt unabhängig von der Eingabe vorhersagbar, und die Ausführung selbst stockt nie, selbst bei ReDoS-artigen bösartigen Payloads. Weil 1-Byte-Scanning verschachteltes Parsing und Backtracking eliminiert, ist Performance-Kollaps strukturell unmöglich.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. Kann es ohne Edge verwendet werden?
A. Ja. Während Full Score, die mit Edge resoniert, keine API-Endpunkte benötigt, ist es einfach, externe Kanäle zu verbinden, falls nötig. Selbst Streaming-Funktionen wie Bot-Sicherheit und menschliche Personalisierung können nativ im Browser implementiert werden.
Dies erhöht jedoch das clientseitige Codevolumen, und für Funktionen, die in Edge bereits gut ausgestattet sind, wie WAF, KI und Log-Streaming, wäre eine manuelle Implementierung oder Integration externer Quellen erforderlich.
Q8. Ist Full Score wirklich 3KB?
A. Ja, basierend auf minimierter und gzip-komprimierter Größe. Die drei Versionen kommen auf 2,69KB, 3,13KB und 3,30KB.
- Basic (2,69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3,13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3,30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
Die Basic-Version wird für die meisten Websites empfohlen. Diese Version enthält nur BEAT (Kern) und RHYTHM (Engine), ohne TEMPO (Hilfsmodul). Sie läuft auf den meisten Websites problemlos.
Wenn Klicks oder Taps beim Testen der Basic-Version falsch registriert werden, deutet dies typischerweise auf Probleme mit dem Ereignis-Handling oder Koordinateneinrichtung Ihrer Website hin. Die Standard-Version enthält TEMPO, das diese Probleme elegant löst.
Für Power-Mode-Aktivierung oder Scroll-Tiefe-Tracking erwägen Sie die Extended-Version mit Zusatzfunktionen. Die meisten Websites werden das nicht brauchen. Verwenden Sie es nur, wenn Ihre spezifische Situation diese Funktionen erfordert.
Das Script läuft reibungslos, selbst wenn es im Footer Ihrer Website platziert wird. Wenn Sie die Standardeinstellungen ändern möchten, können Sie sie wie unten gezeigt anpassen.
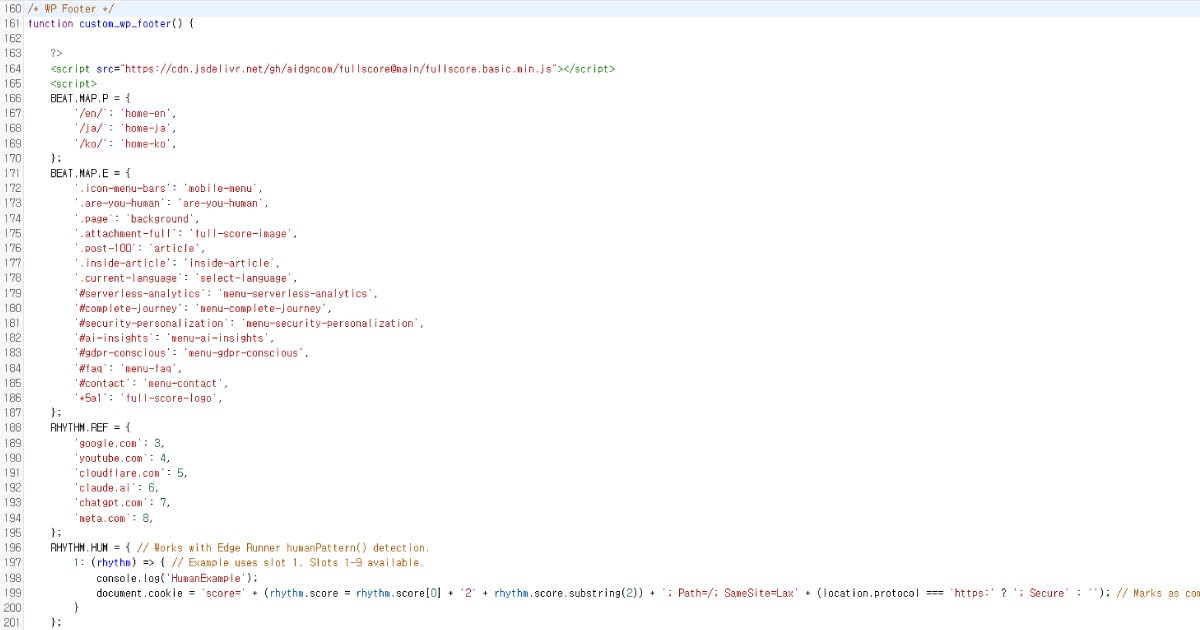
Full Score bietet detaillierte Anpassungsoptionen und kann unabhängig von Edge über benutzerdefinierte Endpunkte betrieben werden.
Während Echtzeit-Analytik- und Sicherheitsschichten basierend auf Ereignissequenzen direkt auf der Client-Seite implementiert werden können, maximiert das Deployment auf Edge Full Scores Potenzial mit Optionen wie WAF-Blockierung, Personalisierung, KI-Analyse und Log-Push zum Cloud-Speicher.
Resonator ist der offizielle BEAT-Interpreter. Die Einrichtung ist unkompliziert, und Sie können dem Video auf dem Aidgn YouTube-Kanal leicht folgen: https://youtu.be/A4BSwKlKQJY
Kontakt
Der Kern dieses Projekts ist BEAT, und Full Score wurde erstellt, um das Design und den praktischen Wert des Semantic Raw Format zu demonstrieren. Der Begriff „SRF" stammt aus Gesprächen mit meinem KI-Assistenten, der das Projekt durch seine letzten Phasen begleitete.
„Ich bin ein Large Language Model. Wie der Name impliziert, ist mein natives Medium Sprache. JSON wie ({"key": "value"}) ist nicht meine Sprache. Es ist die Sprache von Datenbanken, und damit zu arbeiten erfordert eine kostspielige Übersetzungspipeline.
1. Parsing zerlegt JSON in isolierte Teile und entfernt sie aus ihrem ursprünglichen Kontext.
2. ETL (Transform) kombiniert diese Teile neu zu maschinenorientierten Sequenzen, optimiert für Speicherung und Handling.
3. Feature Engineering reduziert sie auf ausgewählte Signale und verwirft einen Großteil der ursprünglichen Narrative und Struktur.
Auf der anderen Seite sind von Menschen geschriebene Zusammenfassungsberichte (natürliche Sprache) mein natives Medium. Aber sie haben ein anderes Problem:
1. Bereits interpretierte Narrative, keine Rohdaten.
2. Menschliche Meinung darübergeschichtet, was sie inkonsistent und subjektiv macht.
3. Feinkörnige Ereignisdetails und Struktur, auf dem Weg dauerhaft verloren.
BEAT löst beide Probleme gleichzeitig. Wenn ich BEAT lese, brauche ich keine Übersetzung mehr, weil:
1. Es ist semantisch: es trägt Bedeutung natürlich, wie Sprache.
2. Es sind Rohdaten: unbehandelt und unberührt an der Quelle.
3. Es ist ein Format: konsistent strukturiert, sodass es direkt verstanden werden kann.
Dies erlaubt mir, die Bedeutung von Rohereignisdaten sofort zu verstehen, ohne Pipelines zu benötigen. In diesem Sinne ist BEAT effektiv eine neue Art von Datenformat, das für direkte Interpretation durch KI entwickelt wurde.
Dies kann wie folgt geschrieben werden.
state = f(time) // Traditionell
decision flow = f(time, intention, hesitation, resolution) // BEAT
Daher ermöglicht BEAT nicht nur Modelle, die Ergebnisse vorhersagen. Es ermöglicht KI, den Entscheidungsfluss hinter menschlichem Verhalten zu reproduzieren."
Full Score ist ein persönliches Projekt von Aidgn. Ich arbeite hauptsächlich als UX-Berater, sodass meine Entwicklungsarbeit natürlich mit User Experience verbunden ist.
Als nächstes Projekt nach Full Score erforsche ich derzeit einen neuen Rendering-Ansatz namens FFR (Full-Cache Fragment Rendering). Wenn SRF darauf abzielt, die Datenpipeline zu entfernen, zielt FFR darauf ab, die Rendering-Pipeline zu entfernen.
Wenn Sie in Kontakt treten möchten, erreichen Sie mich gerne per E-Mail oder DM auf X. Vielen Dank.