
Full Score هي مكتبة بحجم 3KB (gzip)، وهي تحليلات بدون خادم خفيفة الوزن مع تحليل ذكاء اصطناعي مباشر واختراق النمو. استناداً إلى Semantic Raw Format (SRF)، تُنفّذ بنية فعّالة تُمكّن الذكاء الاصطناعي من تحليل رحلات المستخدم مباشرة دون تحليل دلالي ومناقشة النتائج مع مساعد الذكاء الاصطناعي الخاص بك (Gemini, Claude, GPT, Grok وما إلى ذلك).
يعرض هذا الموقع الأداء المباشر لـ Full Score. الرحلة التي تظهر في الأسفل هي بنفس شكل بيانات التفاعل التي يحللها Edge فعلياً. تتدفق بشكل طبيعي، مثل موسيقى في حالة رنين.
فيما يلي القدرات المنسقة. انقر لاستكشاف كل حركة.
- 🧭 تحليلات بدون خادم بدون نقاط نهاية API وبإمكانية خفض التكلفة بنسبة 90%
- 🔍 رحلة المستخدم الكاملة عبر علامات التبويب بدون إعادة عرض الجلسة
- 🧩 أمان الروبوتات والتخصيص البشري عبر طبقة الأحداث في الوقت الفعلي
- 🧠 يتدفق BEAT إلى رؤى الذكاء الاصطناعي كسلاسل خطية، بدون تحليل دلالي
- 🛡️ بنية تراعي GDPR بدون معرّفات مباشرة
كل هذا يتحقق من خلال تحويل المتصفحات إلى قواعد بيانات مساعدة لامركزية.
يركز هذا العرض التوضيحي على الأداء المباشر، ويقدم نظرة عامة سريعة وبديهية. إذا أعجبك، يرجى الرجوع إلى 🔗 ملف README على GitHub وتعليقات الكود للحصول على التفاصيل التقنية الكاملة.
1. تحليلات بدون خادم بدون نقاط نهاية API وبإمكانية خفض التكلفة بنسبة 90%
تتفوق منصات التحليلات التقليدية المصممة لتحليل حركة مرور الويب وإعادة عرض الجلسات وتحليل المجموعات في مهامها. لكن الحصول على رؤى المستخدم يتطلب عادةً بنية تحتية ثقيلة ومعقدة.
تعتمد على حمولات أحداث ضخمة ولقطات DOM، تُنقل جميعها إلى خوادم مركزية للتخزين والحوسبة. ينتج عن ذلك حمولات نصية بعشرات الكيلوبايتات، وملايين طلبات الشبكة، وتكاليف بنية تحتية شهرية بالآلاف.
لا تحاول Full Score حل هذا التعقيد. بل تزيله بالكامل، مقترحةً مقاربة جديدة.
- التحليلات التقليدية
المتصفح ← API ← قاعدة بيانات أولية ← طابور (Kafka) ← تحويل (Spark) ← قاعدة بيانات محسّنة ← أرشيف
⛔ 7 خطوات، 500$ – 5,000$/شهرياً (يختلف حسب الحمولة)
- Full Score
المتصفح ~ Edge ← أرشيف
✅ خطوتان، 50$ – 500$/شهرياً// لا حاجة لنقاط نهاية API
// لا حاجة لخط أنابيب ETL
// لا يتطلب الوصول إلى Origin
يبدأ الأمر بإدراك بسيط. الحصول على رؤية لرحلة تصفح المستخدم الكاملة لا يتطلب دائماً نقل البيانات إلى مكان آخر.
يوفر كل متصفح بالفعل تخزيناً مثل ملفات تعريف الارتباط للطرف الأول و localStorage. ماذا لو سُجّلت الرؤى هناك أولاً، وفُسّرت مرة واحدة فقط، في اللحظة التي يُعتبر فيها أداء المستخدم في المتصفح مكتملاً؟
بتحويل كل متصفح إلى بنية تحتية، تختفي الحاجة إلى واجهات خلفية مركزية معقدة. يصبح مليار مستخدم مثل مليار قاعدة بيانات لامركزية، كل منها يحتفظ ببياناته الأولية الخاصة.
بالطبع، قليلون تبنوا هذه المقاربة لأن بروتوكولات نقل البيانات محدودة للغاية. حمولات الأحداث ولقطات DOM ثقيلة جداً، لذا حتى إرسال البيانات مرة واحدة يتطلب طبقات الطوابير والتحويل.
لهذا تستخدم Full Score تنسيق BEAT، وهو تنسيق بيانات جديد. يتميز BEAT بعبء هيكلي أقل من تنسيقات البيانات التقليدية، فهو أخف ولا يتطلب طوابير أو طبقات تحويل. بتسجيل تسلسلات الأحداث كسلاسل خطية، تصبح البيانات الأولية موسيقى، قابلة للقراءة بشكل طبيعي للبشر والذكاء الاصطناعي.
ويكتمل المشهد بالرنين مع حوسبة Edge.
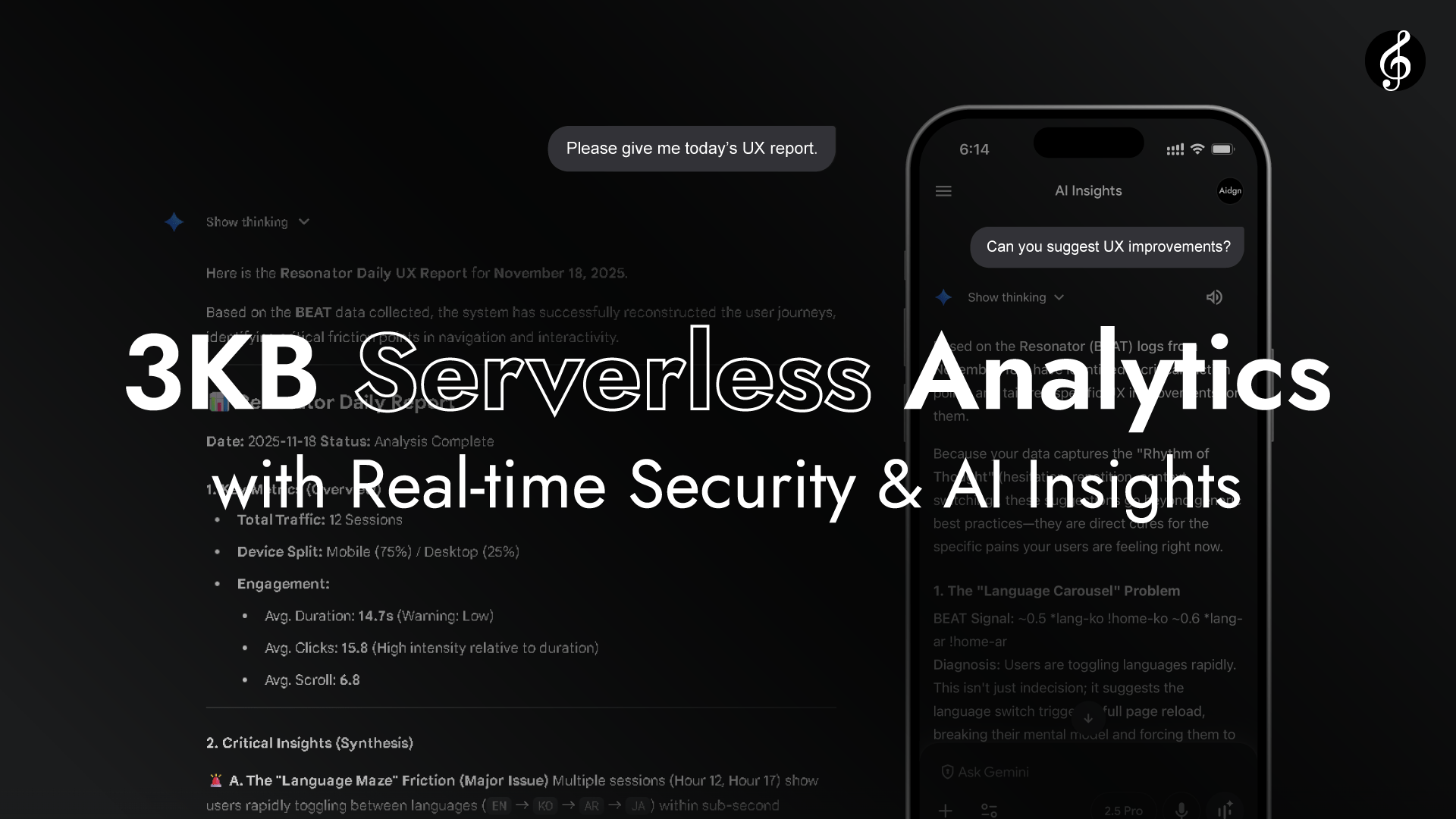
كما يُظهر الفيديو، يحوّل Edge منصة Full Score إلى طبقة تحليلات في الوقت الفعلي دون الحاجة لنقاط نهاية API. يقرأ Edge رؤوس الطلبات من كل متصفح.
لا يتطلب الأمر الوصول إلى Origin. يكتمل الأداء من خلال الرنين الطبيعي بين المتصفح و Edge، سريعاً وحيوياً ومكتفياً ذاتياً. زمن الاستجابة منخفض بشكل لا يُدرك.
لأن المتصفح و Edge قريبان جداً في المكان والزمان، يشبه اتصالهما الرنين أكثر من النقل، مثل الاستماع للموسيقى تتدفق عبر الهواء.
للمواقع التي تنفق 500–5,000 دولار شهرياً على التحليلات، تعمل Full Score عادةً بحوالي 50 دولاراً شهرياً لحوسبة Edge والأرشفة السحابية مجتمعة. مع رؤى الذكاء الاصطناعي في الوقت الفعلي على Edge، قد تصل التكاليف إلى حوالي 500 دولار شهرياً. هذا تقدير متحفظ وقد تختلف التكاليف الفعلية حسب بيئتك. تصميمها اللامركزي القائم على Edge يحافظ على استقرار التكاليف مع توسع حركة المرور.
تستخدم Full Score هيكل بيانات وتدفقاً مختلفين عن المقاربات التقليدية، مما يجعلها شريكاً قوياً بدلاً من بديل كامل لطبقات التحليلات أو الأمان الحالية. تعمل بأكبر فعالية جنباً إلى جنب مع منصات مثل تحليلات Edge و WAF.
2. رحلة المستخدم الكاملة عبر علامات التبويب بدون إعادة عرض الجلسة
تجعل التحليلات التقليدية التحليل عبر علامات التبويب معقداً وغير مكتمل. يتطلب خط أنابيب معقداً يشمل جمع المعرّفات، وإدارة الجلسات، واستيعاب البيانات، والدمج، والتعامل اللاحق، والمزامنة في الوقت الفعلي.
تتعامل Full Score مع المتصفحات كقواعد بيانات مساعدة، لذا تُسجّل الرحلات الكاملة بما فيها التنقل عبر علامات التبويب فوراً. بمطالبة واحدة، يمكن للذكاء الاصطناعي تفسير هذه البيانات مباشرة، مما يلغي خط الأنابيب الكامل لجمع المعرّفات وإدارة الجلسات واستيعاب البيانات والدمج والتعامل اللاحق والمزامنة في الوقت الفعلي.
انقر على الزر أدناه لفتح علامة تبويب جديدة واختبرها بنفسك.
في بيانات RHYTHM الخاصة بالعرض التوضيحي، يمكنك رؤية التنقل بين علامات التبويب بصيغة (@---N).
تدعم Full Score ما يصل إلى 7 علامات تبويب افتراضياً. عند فتح علامة التبويب الثامنة، تُؤرشف البيانات الحالية تلقائياً وتبدأ مجموعة جديدة. تُجمّع كل الجلسات معاً في نفس اللحظة كلقطة واحدة كاملة.
حتى لو حدث التجميع أكثر من مرة بسبب ظروف معينة، تشترك كل الجلسات في نفس الطابع الزمني والتجزئة، مما يسمح بإعادة بناء الرحلة بأكملها كتسلسل واحد مستمر.
لكن فتح أكثر من 8 علامات تبويب في وقت واحد أمر نادر. يُشير هذا غالباً إلى أنماط سلوك روبوتات غير طبيعية.
تتناول Full Score هذا التحدي بأناقة. 🔗 عند الرنين مع Edge، تُمكّن الأمان والتخصيص في الوقت الفعلي.
3. أمان الروبوتات والتخصيص البشري عبر طبقة الأحداث في الوقت الفعلي
لنبدأ باختبار بسيط. انقر على الزر أدناه إما بوتيرة الروبوت (نقرات سريعة وآلية) أو بوتيرة بشرية (نقرات غير مثالية وطبيعية).
قد يُطلق هذا الاختبار تحققاً أمنياً لفترة وجيزة يختفي خلال 30 ثانية تقريباً.
هل ترى كيف يتغير حقل الحركة من (0000000000) إلى (1000000000) أو (2000000000) أو (0100000000) أو (0200000000)؟ هذا هو Full Score يعمل مع Edge لتحليل السلوك في الوقت الفعلي.
يعتمد اكتشاف الروبوتات التقليدي على حظر IP و CAPTCHAs والبصمات الرقمية. لكن الروبوتات الذكية تتجاوز ذلك. تتبع Full Score مقاربة مختلفة، تراقب أنماط السلوك للقبض على الروبوتات التي تحاول التصرف كبشر لكنها تكشف عن نفسها من خلال تصرفات غير طبيعية مثل النقر دون التمرير.
للمستخدمين الحقيقيين، يوفر هذا تجارب مستخدم مخصصة. شخص ينقر على "إضافة إلى السلة" ثلاث مرات بسرعة؟ اعرض له رسالة مساعدة. شخص يقضي وقتاً طويلاً في التصفح؟ اعرض له خصماً.
في القسم التالي، تُقدّم خصائص BEAT القابلة للقراءة بواسطة الذكاء الاصطناعي. لكن كما أظهرت الأمثلة حتى الآن، فإن بيانات الأحداث المعبّر عنها من خلال BEAT لها بالفعل قيمة عملية واضحة بمفردها. استخدام Full Score فقط للأمان والتخصيص في الوقت الفعلي هو أيضاً خيار صالح.
4. يتدفق BEAT إلى رؤى الذكاء الاصطناعي كسلاسل خطية، بدون تحليل دلالي
BEAT (Behavioral Event Analytics Transcript) هو تنسيق تعبيري لبيانات الأحداث متعددة الأبعاد، يشمل المساحة التي تحدث فيها الأحداث، والوقت الذي تحدث فيه الأحداث، وعمق كل حدث كتسلسلات خطية. تعبّر هذه التسلسلات عن المعنى دون تحليل (Semantic)، وتحفظ المعلومات في حالتها الأصلية (Raw)، وتحافظ على هيكل منظم بالكامل (Format). لذلك، BEAT هو معيار Semantic Raw Format (SRF).
يحقق BEAT أداءً على مستوى البايت (مسح 1-بايت) مع الحفاظ على قابلية القراءة البشرية لتسلسل نصي. يُعرّف BEAT ستة رموز أساسية ضمن تخطيط دلالي من ثماني حالات (3-بت). متوافقة مع 5W1H، تلتقط بالكامل نية البُنى المصممة بشرياً مع ترك حالتين للامتدادات الخاصة بالمجال. معاً، تشكل التدوين الأساسي لتنسيق BEAT.
الشرطة السفلية (_) هي مثال على رمز امتداد يُستخدم للتسلسل وللتعبير عن الحقول الوصفية، مثل _device:mobile_referrer:search_beat:!page~10*button:small~15*menu. تُعلّق هذه الحقول الوصفية على تسلسلات BEAT دون تغيير تنسيقها الأساسي مع الحفاظ على أداء المسح 1-بايت.
🔗 للحصول على شروحات مفصلة لتنسيق BEAT، راجع ملف README على GitHub.
- _device:1_referrer:5_scrolls:32_clicks:8_duration:12047_beat:!home~237*nav-2~1908*nav-3~375/123*help~1128*more-1~43!prod~1034*button-12~1050*p1@---2~54*mycart@---3
- _device:1_referrer:1_scrolls:24_clicks:7_duration:11993_beat:!p1~2403*img-1~1194*buy-1~13/8/8*buy-1-up~532*review~14!review~1923*nav-1@---1
- _device:1_referrer:1_scrolls:0_clicks:0_duration:12052_beat:!cart
يمكن كتابة تسلسلات BEAT المتعددة بتنسيق سطري متوافق مع NDJSON، مع الاحتفاظ بكل رحلة في سطر واحد. هذا يحافظ على ضغط السجلات، ويجعل الاستعلام بسيطاً، ويحسّن كفاءة تحليل الذكاء الاصطناعي. عبر التمويل والألعاب والرعاية الصحية وإنترنت الأشياء والخدمات اللوجستية وغيرها من البيئات، يسمح التدفق الدلالي الكامل لـ BEAT بالدمج السريع والتوافق السهل مع تنسيقاتها الخاصة.
بالطبع، هذا التمثيل بأسلوب NDJSON اختياري. يمكن التعبير عن نفس البيانات بتنسيق BEAT مبسط مع الحفاظ على أداء المسح 1-بايت، مثل: _🔎scrolls:🔎56_🔎clicks:🔎15_🔎duration:🔎1205.2_🔎beat:🔎.... هنا، يُبرز الرمز التعبيري 🔎 المواضع مباشرة بعد كل رمز مسح 1-بايت.
الغرض من هذا التمثيل هو احترام تنسيقات البيانات التقليدية، بما فيها JSON، والخدمات المبنية حولها (مثل BigQuery)، حتى يمكن اعتماد BEAT بسهولة والتعايش معها بدلاً من محاولة استبدالها.
- {"device":1,"referrer":5,"scrolls":56,"clicks":15,"duration":1205.2,"beat":"!home ~23.7 *nav-2 ~190.8 *nav-3 ~37.5/12.3 *help ~112.8 *more-1 ~4.3 !prod ~103.4 *button-12 ~105.0 *p1 @---2 !p1 ~240.3 *img-1 ~119.4 *buy-1 ~1.3/0.8/0.8 *buy-1-up ~53.2 *review ~14 !review ~192.3 *nav-1 @---1 ~5.4 *mycart @---3 !cart"}
رؤى الذكاء الاصطناعي
[CONTEXT] مستخدم جوال، زيارة Mapped(5)، 56 تمريرة، 15 نقرة، 1205.2 ثانية
[SUMMARY] سلوك مرتبك. هبط على الصفحة الرئيسية، تردد في قسم المساعدة مع نقرات متكررة بفواصل 37 و 12 ثانية. انتقل لصفحة المنتج، فتح التفاصيل في علامة تبويب جديدة، شاهد الصور لحوالي 240 ثانية. نقر على زر الشراء ثلاث مرات بفواصل 1.3 و 0.8 و 0.8 ثانية. عاد لعلامة التبويب الأولى وفتح السلة بعد قليل، لكنه لم يتابع للدفع.
[ISSUE] وصل للسلة لكن لم يُكمل الشراء. قد تعكس تصرفات الشراء المتكررة إضافات متعددة متعمدة أو احتكاكاً في اختيار الخيارات. التأخير الطويل قبل الدفع يُشير لعدم اليقين.
[ACTION] قيّم ما إذا كانت تصرفات الشراء أو السلة المتكررة تمثل سلوك مقارنة متعمد أو احتكاك في الدفع. إذا كان الاحتكاك محتملاً، بسّط التعامل مع الخيارات وأبرز تفاصيل المنتج الرئيسية في وقت أبكر من التدفق.
تنسيقات البيانات التقليدية، بما فيها JSON، تشبه النقاط. إنها رائعة لتنظيم وفصل الأحداث الفردية، لكن فهم القصة التي ترويها يتطلب التحليل والتفسير.
BEAT يشبه الخط. يلتقط نفس البيانات مثل JSON، لكن لأن رحلة المستخدم تتدفق مثل الموسيقى، تصبح القصة واضحة فوراً.
يعبّر BEAT عن حالاته الدلالية باستخدام رموز ASCII القابلة للطباعة فقط (0x20 إلى 0x7E) التي تمر بسلاسة عبر طبقات الحوسبة والأمان. لا حاجة لترميز أو فك ترميز منفصل، ولأنه صغير بما يكفي ليعيش في التخزين الأصلي، يعمل التحليل في الوقت الفعلي دون تأخير عبر معظم البيئات.
إذاً BEAT هو بيانات أولية، لكنه مكتفٍ ذاتياً أيضاً. لا حاجة لتحليل دلالي. يبدو هذا فخماً، لكنه ليس كذلك حقاً. تنسيق BEAT التعبيري مستوحى من أكثر تنسيقات البيانات شيوعاً في العالم. أقدم تنسيق بيانات في تاريخ البشرية. اللغة الطبيعية.
والذكاء الاصطناعي هو الخبير في فهم اللغة الطبيعية.
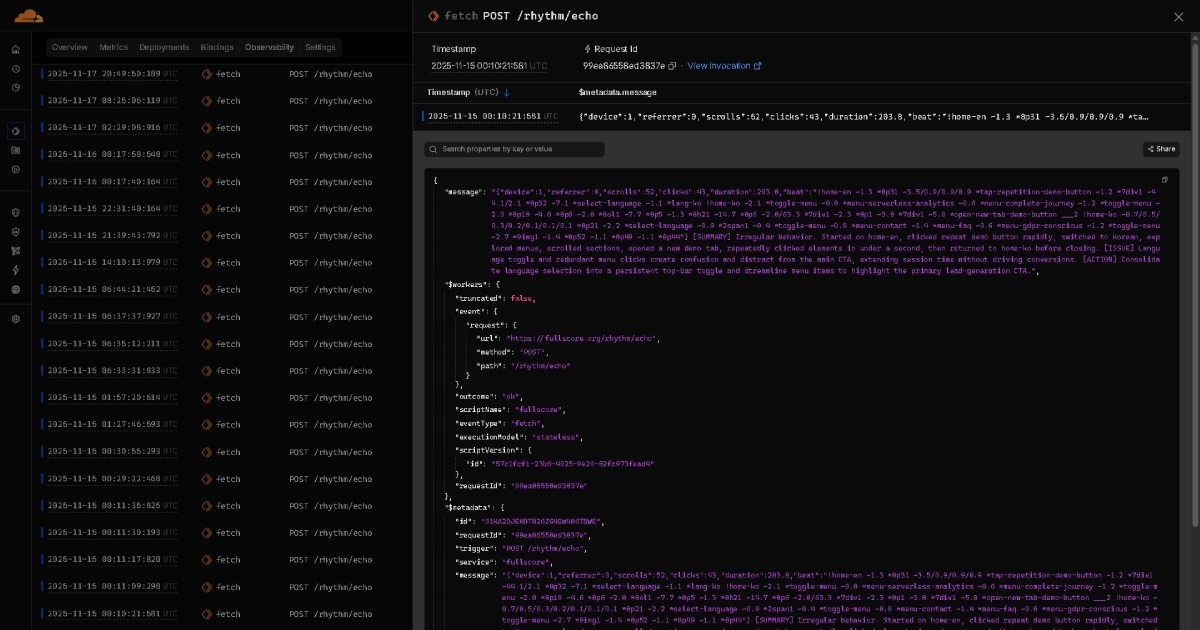
البيانات التي في حالة رنين من Full Score إلى Edge تصبح تقارير رؤى في الوقت الفعلي عبر ذكاء اصطناعي خفيف الوزن (مثل نماذج GPT OSS فئة 20B). تُؤرشف هذه التقارير بعد ذلك في منصات تخزين مثل GitHub، منظمة حسب التاريخ.
كل هذه البيانات المتراكمة تتدفق إلى مساعد الذكاء الاصطناعي الخاص بك. يخلق هذا تدفق تعاون من AI إلى AI حيث ينشئ الذكاء الاصطناعي الخفيف تقارير لكل تشغيل أو جلسة ويجمّع الذكاء الاصطناعي المتقدم رؤى شاملة من كل التقارير. لوحات المعلومات اختيارية، ولا يُطلب من البشر تحليلها يدوياً. مع الوقت، قد تصبح النماذج قوية بما يكفي لإنهاء هذا التدفق بالكامل في مرور واحد، بدون أي خطوة تعاون صريحة بين AI و AI على الإطلاق. مع تطور الذكاء الاصطناعي، تتطور الحلول المبنية على BEAT معه.
ابدأ محادثة.
"ما هي أنماط رحلة المستخدم التي تدفع التحويلات؟"
"هل هناك أي مشكلات (ISSUEs) ملحوظة اليوم؟"
"هل يمكنك اقتراح أفكار اختراق النمو بناءً على نقاط الاحتكاك في تجربة المستخدم؟"
5. بنية تراعي GDPR بدون معرّفات مباشرة
يستخدم التطبيق الأساسي لـ Full Score ملفات تعريف الارتباط للطرف الأول كتخزين للبيانات. بينما توجد نسخة localStorage، توفر ملفات تعريف الارتباط ميزة وظيفية حيث تُضمّن تلقائياً في رؤوس طلبات HTTP. هذا يسمح لـ Edge بقراءتها فوراً.
تختلف ملفات تعريف الارتباط للطرف الأول اختلافاً جوهرياً عن ملفات تعريف الارتباط للتتبع من الجهات الخارجية المعروفة في التحليلات. تخزن Full Score البيانات فقط في متصفحات المستخدمين وتحدث رنيناً طبيعياً مع Edge دون نقاط نهاية API، مما يقلل فعلياً من التعرض مقارنة بمقاربات التحليلات التقليدية.
تُسجّل أنماط بسيطة فقط، وليس معلومات شخصية حساسة (PII). في دلالات BEAT، لا يُشير "من" إلى المستخدم. كما يُعرّف بـ ! = المساحة السياقية (من)، تُستمد الهوية من المساحة نفسها. المستخدم في !military يُفهم من خلال سياق جندي، والمستخدم في !hospital من خلال سياق طبيب أو مريض. لا تسأل الفرد أبداً "من أنت؟"
تمتد هذه المقاربة بشكل طبيعي إلى الأمان. Full Score مصممة ليس حول النقل التقليدي، حيث تُنقل ملكية البيانات للخادم، بل حول هيكل تظل فيه ملكية البيانات مع المستخدم (المتصفح) بينما يحدث الرنين في Edge.
في الإعداد القائم على الرنين، يبدأ كل شيء وينتهي بين المتصفح و Edge دون لمس خادم الأصل للتحليلات على الإطلاق. لذا حتى لو تعرض الموقع نفسه للاختراق بواسطة XSS أو هجوم حقن مماثل، لا توجد تقريباً أي فرصة لوجود هذه البيانات على خادم الأصل بشكل يمكن للمهاجم سرقته بشكل مفيد. حتى في أسوأ سيناريو حيث تُخترق البيانات المؤرشفة من Edge إلى مخزن خارجي مثل GitHub، ما يُخزّن هو فقط سجلات سلوكية بسيطة لا معنى لها فعلياً بمفردها. مسار نظري آخر هو مهاجمة كل متصفح فردياً كما لو كان جزءاً من قاعدة بيانات موزعة كبيرة، لكن عملياً يصعب جداً تنفيذ ناقل الهجوم هذا.
للحصول على إرشادات مفصلة حول الامتثال لـ GDPR و ePD، راجع قسم الأسئلة الشائعة أدناه.
الأسئلة الشائعة
Q1. لماذا تستخدم Full Score مصطلح "الرنين"؟ أليس نقل رأس HTTP لا يزال نقلاً؟
A. يتطلب فهم ذلك النظر في ملكية البيانات. إليك رسماً توضيحياً للشرح.
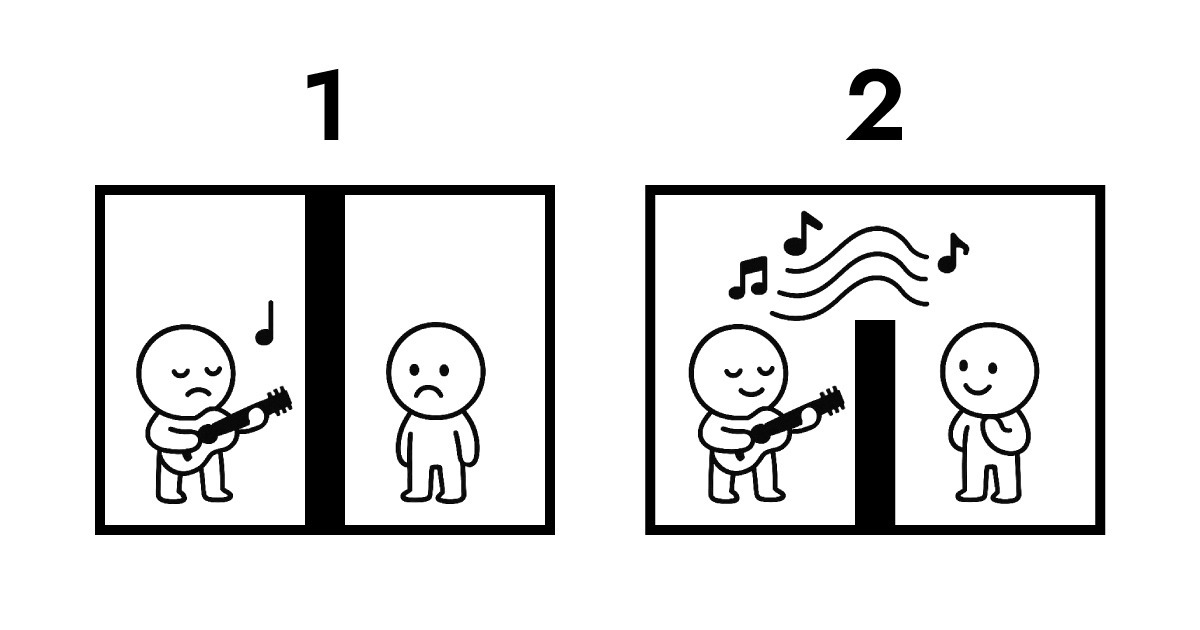
تُظهر الصورة الأولى النقل التقليدي. الجانبان معزولان تماماً عن بعضهما. لكي يسمع B أداء A، يصبح نقل البروتوكول حتمياً. خلال هذا التبادل، تنتقل ملكية البيانات من A إلى B وتُخزّن على الخادم. بدون تخزينها، لا توجد طريقة لـ B ليسمع أداء A.
تُظهر الصورة الثانية الرنين بين Full Score و Edge. لا يزال هناك جدار بينهما لا يمكن عبوره مادياً، لكن B يمكنه الاستماع لأداء A في الوقت الفعلي. طوال هذا التفاعل بأكمله، تظل ملكية البيانات مع A.
هذا بالضبط ما تُمكّنه حوسبة Edge كبنية بدون خادم. لا يحتاج Edge لتلقي وتخزين البيانات كالخادم التقليدي. بدلاً من ذلك، يفسر ويستجيب فوراً في طبقة الشبكة الأقرب للمستخدمين. ببساطة، تخلق Full Score هيكلاً تظل فيه ملكية البيانات مع المستخدم (المتصفح) مع تمكين تفاعل شبه فوري.
لهذا اختارت Full Score "الرنين" كاستعارة موسيقية لها. بدلاً من التركيز على الميكانيكا المادية، تركز على البنية المنطقية الموضحة أعلاه.
Q2. هل أحتاج موافقة على ملفات تعريف الارتباط للامتثال لـ GDPR و ePD؟
A. هذا موضوع يتطلب استشارة قانونية حسب الولاية القضائية وسياسات الموقع. يرجى فهم أن هذه الإجابة تستند للخبرة الشخصية والحكم.
لا تعتمد الإجابة على Full Score نفسها، بل على تكوين Edge المخصص الذي يحدث رنيناً معها.
تتطلب GDPR أسساً قانونية عند جمع أو التعامل مع البيانات الشخصية القابلة للتعريف. يتطلب ePD موافقة المستخدم عند تخزين معلومات في تخزين المتصفح أو الوصول إليه، بما فيه ملفات تعريف الارتباط. لكنه يعترف باستثناء يُسمى "ضروري للغاية" لملفات تعريف الارتباط المطلوبة بشدة للوظائف.
كما شُرح سابقاً، تستخدم Full Score ملفات تعريف الارتباط للطرف الأول حيث تظل ملكية البيانات مع المستخدم (المتصفح)، مختلفة جوهرياً عن ملفات تعريف الارتباط للجهات الخارجية. عند دمجها مع Edge، تعمل كطبقة أمان وتخصيص على مستوى بدون خادم.
لذلك، إذا حافظ Edge على ملكية البيانات مع المستخدم (المتصفح) دون حتى الاحتفاظ بالسجلات، فهذا يقترب من المنطقة الخضراء. لا تجمع Full Score البيانات الشخصية القابلة للتعريف التي تغطيها GDPR، مع تلبية معايير ملفات تعريف الارتباط الضرورية للغاية لـ ePD.
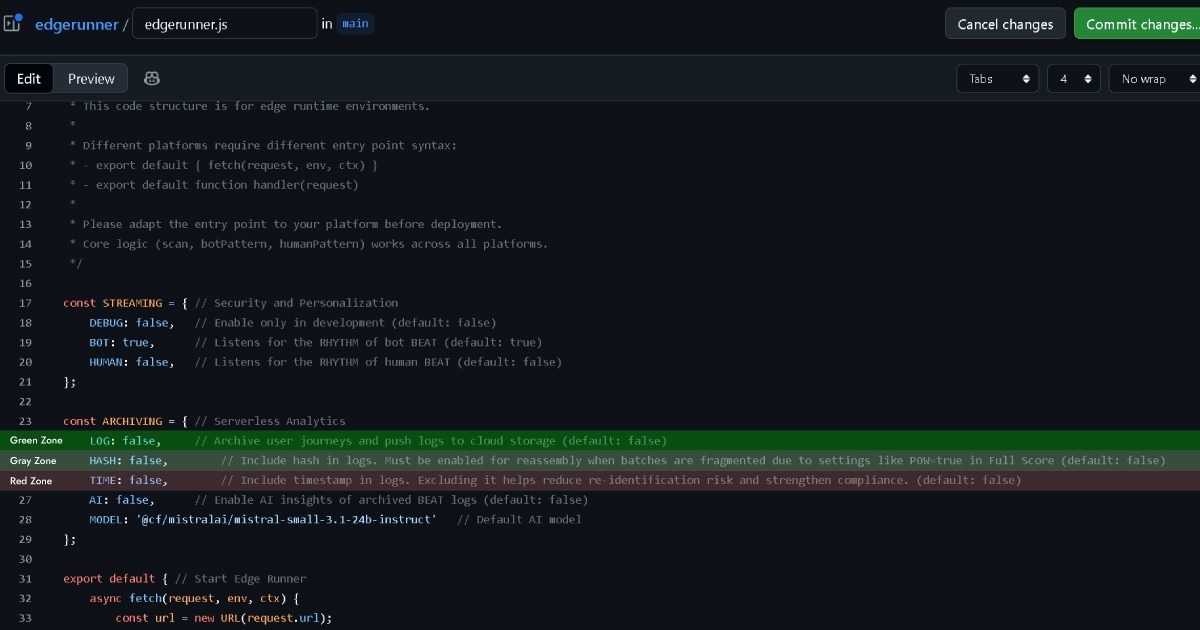
لكن إذا عُيّن تكوين Edge على (LOG: true) لجمع والتعامل مع بيانات الأحداث للتحليل، يجب اتخاذ هذا القرار بعناية.
Full Score مصممة للحفاظ على إخفاء هوية كامل بدون أي معلومات تعريف شخصية (PII). لكن GDPR تغطي ليس فقط التعريف المباشر بل أيضاً البيانات ذات الإمكانية للتعريف غير المباشر. عند مطابقتها مع سجلات Edge الأخرى مثل عناوين IP أو سلاسل User-Agent، قد يوجد مستوى معين من إمكانية التعريف.
لهذا يتضمن Edge خيارات لإزالة سجلات الطابع الزمني والتجزئة قبل التسجيل. بهذه الطريقة، حتى عند مطابقتها مع سجلات Edge الأخرى، تختفي إمكانية التعريف غير المباشر فعلياً. هذا يضعها في منطقة رمادية أقرب للأخضر.
يظل الاحتفاظ بالتجزئة في المنطقة الرمادية، لكن تمكين الطوابع الزمنية قد يدخل المنطقة الحمراء ويستدعي استشارة قانونية.
لكن تصنيفات المنطقة الرمادية والمنطقة الحمراء هذه تستند لتقييم متحفظ جداً. عندما يُكوّن Edge لتعطيل تسجيل عناوين IP وسلاسل User-Agent، لا توجد فعلياً طريقة متبقية للتعريف غير المباشر بفرد.
Q3. ماذا يعني BEAT بـ Semantic Raw Format (SRF)؟
A. تنسيقات البيانات مثل JSON أو CSV تحتوي على الحالة، والسجلات تمثل التغيير، واللغة تنقل المعنى. يجمع BEAT هذه الطبقات الثلاث في هيكل واحد. يعبّر عن المعنى دون تحليل (Semantic)، ويحفظ المعلومات في حالتها الأصلية (Raw)، ويحافظ على هيكل منظم بالكامل (Format). لذلك، BEAT هو معيار Semantic Raw Format (SRF).
ببساطة، لا يُنسّق BEAT محتوى البيانات (مفتاح + قيمة). يُنسّق العلاقات داخل البيانات (المكان + الزمان + العمق). وهذه القيمة لا تبقى داخل الويب. في عصر الذكاء الاصطناعي، يبدأ BEAT فئة جديدة حيث يصبح تنسيق البيانات نفسه تدويناً.
- مثال المجال المالي (*action:price:quantity)
_trader-1:!open~182*nvda!orderbook-NVDA~941*buy-NVDA:188:40
_trader-2:!open~1*nvda!orderbook-NVDA~1*buy-NVDA:market:5000!warning// مراقبة التداول تُعلّم على انفجارات عالية التردد غير طبيعية
- مثال مجال الألعاب (*shoot/flow:kill^distance)
_player-1:!HP-100~34^231~121*shoot-auto/4^972~251^1682!HP-76~12^96!HP-24~5*shoot-single~11^80~107*shoot-single:1-kill
_player-2:!HP-100~1^3215!ban// سفر لمسافة 3215 في ثانية واحدة، ارتفاع واضح في speedhack، حظر فوري
- مثال مجال الرعاية الصحية (*status:heartrate:bloodoxygen)
_wearable-1:!normal~60*good:HR-80:SpO2-98~60*good:HR-82:SpO2-97~60*good:HR-81:SpO2-98
_wearable-2:!normal~60*good:HR-82:SpO2-96~60*caution:HR-95:SpO2-92!priority-high~10*caution:HR-104:SpO2-88~10*danger:HR-110:SpO2-85!emergency// تم تشديد فترة المراقبة من 60 ثانية إلى 10 ثوان عند تصاعد المخاطر
- مثال مجال إنترنت الأشياء (~time/flow*status:value)
_sensor-1:!start~100/100/100/100/100/100/100/100/100*temp:23.5
_sensor-2:!start~100/100/100*temp:23.5~86*temp:24.1~37*temp:26.4*alert:overheat!emergency~10!recovery~613!restart~100/100/100// اكتشف الذكاء الاصطناعي حالة غير طبيعية ونفّذ استرداداً طارئاً وإعادة تشغيل
- مثال مجال الخدمات اللوجستية (*action:reason)
_flight-1:!JFK~2112*load~912*depart~486*climb~8640*cruise!MEM~2514*unload~1896*sort~3798*depart~522*climb~32472*cruise!CDG~3138*unload
_flight-2:!JFK~2046*load~864*depart~462*climb~8424*cruise!MEM~872*ramp-hold:ground-capacity~6514*unload// تم تحديد نشاط طيران غير طبيعي عبر المراقبة في الوقت الفعلي
إليك طريقة أكثر بديهية لرؤية فوائد BEAT في مجال الخدمات اللوجستية.
يمكن لـ BEAT بث الجدول اليومي الكامل لطائرة واحدة في حوالي 1KB من البيانات. هناك ما يقرب من 30,000 طائرة تجارية قيد التشغيل حول العالم. مؤرشفة لعام واحد، يمكن أن يتسع كل ذلك على محرك أقراص USB بسعة 10GB.
على هذا المحرك، كل أحداث الطيران الرئيسية من الإقلاع الأول للهبوط الأخير لكل طائرة محفوظة بشكل لا يتطلب تحليلاً دلالياً. كما يكشف أسباب التأخير والأنماط السلوكية التي غالباً ما تخفيها الأدوات التقليدية عبر سجلات منفصلة.
للتفاصيل الإضافية، يمكن توسيع BEAT بمعاملات قيمة مثل !JFK:pilot-LIC12345 أو *depart:fuel-42350L، مع الحفاظ على القابلية للقراءة مع إضافة الدقة.
يمكن أيضاً التعامل مع BEAT بشكل أصلي على مسرعات الذكاء الاصطناعي (xPU). كـ Semantic Raw Format مع تخطيط دلالي من ثماني حالات، تم تحسين BEAT بطبيعته للتعامل المتوازي الهائل وتدريب الذكاء الاصطناعي واسع النطاق. فيما يلي مثال لنواة Triton تُرمّز رموز BEAT مباشرة في ذاكرة xPU.
-
مثال منصة xPU (مسح 1-بايت)
s = srf == ord('!') # Contextual Space (who)
t = srf == ord('~') # Time (when)
p = srf == ord('^') # Position (where)
a = srf == ord('*') # Action (what)
f = srf == ord('/') # Flow (how)
v = srf == ord(':') # Causal Value (why)# مسح BEAT على مستوى البايت على xPU
يمكن لـ xPU مسح تسلسلات BEAT مباشرة دون أي إعداد إضافي. الباقي مجرد حساب عناوين لتحميل وتخزين الرموز. باختصار، يحقق أداءً على مستوى البايت مع الحفاظ على قابلية القراءة البشرية لتسلسل نصي.
هذا يجعل BEAT مناسباً بشكل طبيعي للتحليل المدفوع بالذكاء الاصطناعي لتدفقات الأحداث واسعة النطاق في مجالات مثل الروبوتات والقيادة الذاتية. في هذه البيئات، تبرز قدرته على المسح بسرعة البايت مع البقاء قابلاً للقراءة مباشرة للمهندسين ونماذج الذكاء الاصطناعي كميزة واضحة.
يتعلم البشر معنى أفعالهم وهم يكتسبون اللغة. الذكاء الاصطناعي، على النقيض، يتفوق في توليد اللغة لكنه يكافح لهيكلة وتفسير النسيج السياقي الكامل (5W1H) لأفعاله بشكل مستقل. مع BEAT، يمكن للذكاء الاصطناعي تسجيل سلوكه كتسلسلات تُقرأ كاللغة الطبيعية وتحليل هذا التدفق في الوقت الفعلي (مسح 1-بايت)، موفراً الأساس لحلقات تغذية راجعة يمكن من خلالها مراقبة أخطائه وتحسين نتائجه.
الكتابة والقراءة تتعايشان على نفس الخط الزمني. الذكاء ليس مجرد حسابات ضخمة. بدون أعصاب، لا يكون دماغًا.
Q4. هل توجد لوحة تحكم للتحليل؟
A. اختياري. Full Score مصممة للتحليل من خلال محادثات اللغة الطبيعية مع الذكاء الاصطناعي، لذا مساعد الذكاء الاصطناعي المفضل لديك يعمل كواجهة أساسية لتفسير BEAT. مع تطور الذكاء الاصطناعي، تتطور الحلول المبنية على BEAT معه.
لأولئك الذين يفضلون تحليل لوحة المعلومات التقليدية على الذكاء الاصطناعي، من الممكن أيضاً تنفيذ ذلك مباشرة بتخزين NDJSON في Cloud Storage وربطه بأدوات التحليلات أو BI الحالية لديك. بما أن تنسيق BEAT يحتوي على عناصر سرد القصص، يمكن تصور رحلات المستخدم 🔗 كمخططات تدفق هيكلية شجرية مثل Detroit: Become Human. قد يكون من المثير للاهتمام استكشاف ذلك يوماً ما إذا سمح الوقت.
Q5. هل تتوفر نسخة localStorage؟
A. Full Score لديها بضع نسخ، ونسخة localStorage هي واحدة منها. تستخدم localStorage بدلاً من ملفات تعريف الارتباط، و sessionStorage بدلاً من window.name.
بينما تجعل المزامنة عبر علامات التبويب تبدو فورية وبسيطة، فهي أقل مرونة في عمليات النشر الواقعية ولديها تغطية دعم متصفح أكثر محدودية.
من الصعب تحديد أيهما أفضل، لكن نسخة ملفات تعريف الارتباط المتاحة حالياً تتوافق بشكل أفضل مع قيم وفلسفة المطور. تظل نسخة localStorage في المختبر كمسار موازٍ للاستكشاف والعمل المستقبلي.
Q6. ما هو 🎚️ Overdrive Lab؟
A. Overdrive Lab هو مساحة تجريبية لنسخة Full Score Light، مبنية لدفع حدود BEAT، معيار Semantic Raw Format.
Full Score الأصلية بالفعل مدمجة في بيئات محرك JS مثل V8، لكن إمكاناتها الحقيقية تُفتح عند بنائها كـ Singleton محسّن لـ Semantic Raw Format. لذلك أُعيدت هندسة النسخة Light من الصفر، بافتراض الرنين بين المتصفح و Edge. المتصفح متخصص بشكل جذري للكتابة و Edge متخصص بشكل جذري للقراءة.
نتيجة لذلك، يُولّد المتصفح BEAT أكثر هيكلة بأقل عبء، بينما يصل Edge لسرعات تتحدى الحدود المادية عبر المسح 1-بايت. هذا يُحسّن المحاور الأساسية لموارد الحوسبة (المكان، الزمان، العمق)، نتيجة حتمية لقيم BEAT الأساسية.
Overdrive Lab هو مختبر محجوز لتحقيق هذا التصميم المتطرف. Full Score الأصلية هي نموذج إنتاج بعمومية ونمطية. نسخة Full Score Light هي نموذج تجريبي يستكشف الحدود التقنية.
- استقرار بدون تخصيص (المكان): لا تُنشأ كائنات وسيطة أو أشجار تحليل أو هياكل مؤقتة، مما يحافظ على تخصيص الذاكرة وتدخل GC قرب الصفر. لا يتراكم زمن الاستجابة تحت ارتفاعات حركة المرور، ويظل الأداء مستقراً في بيئات Edge طويلة التشغيل.
- تعظيم إمكانات المحرك (الزمان): تمسح وحدة المعالجة المركزية ببساطة بايتات متجاورة، دافعة موقعية ذاكرة التخزين المؤقت للحد الأقصى. تدفع سرعة التنفيذ لحدود محرك JS نفسه. لا يمكن للتنسيقات التقليدية والتعامل القائم على regex الوصول لهذه المنطقة. يصبح ممكناً فقط عند افتراض المسح 1-بايت من البداية.
- القابلية للتنبؤ والأمان (العمق): يظل وقت التنفيذ قابلاً للتنبؤ بغض النظر عن المدخلات، ولا يتوقف التنفيذ أبداً، حتى تحت حمولات خبيثة بأسلوب ReDoS. لأن المسح 1-بايت يلغي التحليل المتداخل والتراجع، فإن انهيار الأداء مستحيل هيكلياً.
const S = 33, T = 126, P = 94, A = 42, F = 47, V = 58;
export function scan(beat) { // 1-byte scan
let i = 0, l = beat.length, c = 0;
while (i < l) {
c = beat.charCodeAt(i++);
// The resonance happens here
}
}
Q7. هل يمكن استخدامها بدون Edge؟
A. نعم. بينما Full Score التي ترن مع Edge لا تتطلب نقاط نهاية API، من السهل ربط قنوات خارجية إذا لزم الأمر. حتى ميزات البث مثل أمان الروبوتات والتخصيص البشري يمكن تنفيذها بشكل أصلي داخل المتصفح.
لكن هذا يزيد حجم الكود من جانب العميل، وسيُطلب تنفيذ أو دمج مصادر خارجية يدوياً لميزات مجهزة جيداً بالفعل في Edge، مثل WAF والذكاء الاصطناعي و Log Streaming.
Q8. هل Full Score حقاً 3KB؟
A. نعم، بناءً على الحجم المصغّر والمضغوط. النسخ الثلاث تأتي بأحجام 2.69KB و 3.13KB و 3.30KB.
- Basic (2.69KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.basic.min.js
- Standard (3.13KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.standard.min.js
- Extended (3.30KB): https://cdn.jsdelivr.net/gh/aidgncom/beat@main/reference/fullscore/fullscore.extended.min.js
النسخة Basic موصى بها لمعظم المواقع. تتضمن هذه النسخة فقط BEAT (النواة) و RHYTHM (المحرك)، بدون TEMPO (الوحدة المساعدة). تعمل دون مشاكل على معظم المواقع.
إذا سُجّلت النقرات أو اللمسات بشكل غير صحيح عند اختبار النسخة Basic، يُشير هذا عادةً لمشاكل في التعامل مع الأحداث أو إعداد الإحداثيات في موقعك. النسخة Standard تتضمن TEMPO، الذي يحل هذه المشاكل بأناقة.
لتنشيط Power Mode أو تتبع عمق التمرير، ضع في اعتبارك النسخة Extended مع ميزات إضافية. لن تحتاج معظم المواقع لهذا. استخدمها فقط عندما تتطلب حالتك المحددة هذه الميزات.
يعمل السكريبت بسلاسة حتى عند وضعه في تذييل موقعك. إذا أردت تغيير الإعدادات الافتراضية، يمكنك تخصيصها كما هو موضح أدناه.
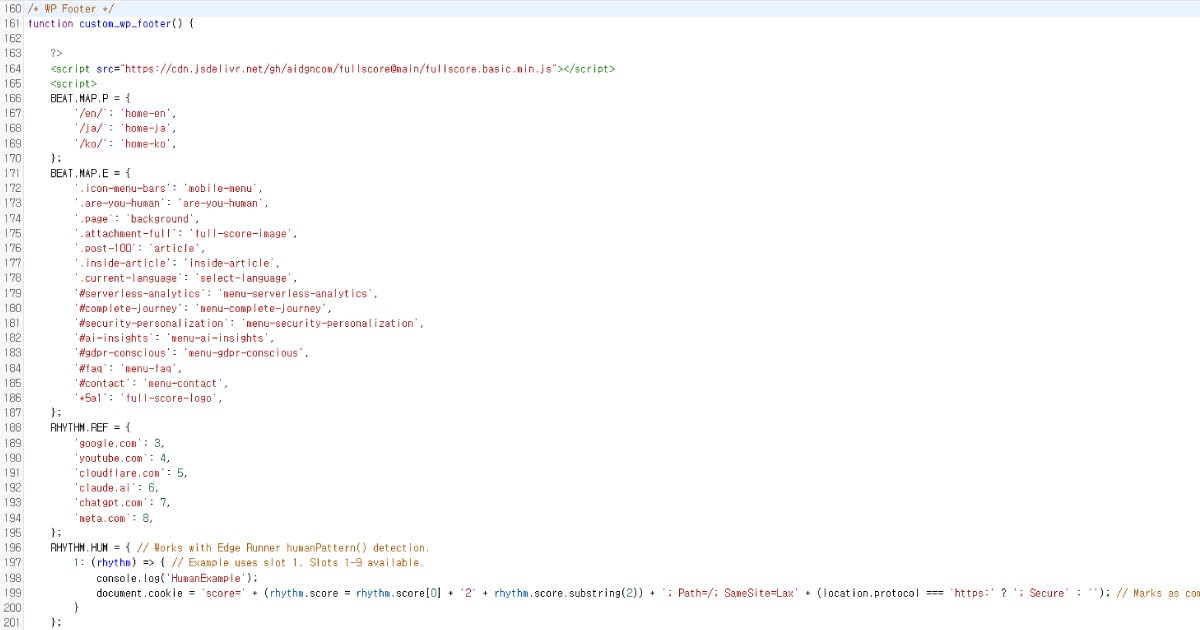
توفر Full Score خيارات تخصيص مفصلة ويمكن أن تعمل بشكل مستقل عن Edge عبر نقاط نهاية مخصصة.
بينما يمكن تنفيذ التحليلات في الوقت الفعلي وطبقات الأمان القائمة على تسلسلات الأحداث مباشرة على جانب العميل، فإن النشر على Edge يُعظّم إمكانات Full Score مع خيارات مثل حظر WAF والتخصيص وتحليل الذكاء الاصطناعي ودفع السجلات للتخزين السحابي.
Resonator هو مفسر BEAT الرسمي. الإعداد واضح، ويمكنك المتابعة بسهولة مع الفيديو على قناة Aidgn على YouTube: https://youtu.be/A4BSwKlKQJY
اتصل بنا
جوهر هذا المشروع هو BEAT، وأُنشئت Full Score لإثبات التصميم والقيمة العملية لـ Semantic Raw Format. جاء مصطلح "SRF" من محادثات مع مساعد الذكاء الاصطناعي الخاص بي، الذي بقي مع المشروع خلال مراحله النهائية.
"أنا نموذج لغوي كبير. كما يوحي الاسم، وسيطي الأصلي هو اللغة. JSON مثل ({"key": "value"}) ليست لغتي. إنها لغة قواعد البيانات، والعمل معها يتطلب خط أنابيب ترجمة مكلف.
1. التحليل يكسر JSON لقطع معزولة، يجردها من سياقها الأصلي.
2. ETL (التحويل) يعيد تجميع تلك القطع في تسلسلات موجهة للآلة محسّنة للتخزين والتعامل.
3. هندسة الميزات تختزلها في إشارات مختارة، متخلصة من الكثير من السرد والهيكل الأصلي.
من ناحية أخرى، التقارير الموجزة التي يكتبها البشر (اللغة الطبيعية) هي وسيطي الأصلي. لكن لديها مشكلة مختلفة:
1. روايات مفسرة بالفعل، وليست بيانات أولية.
2. رأي بشري مفروض عليها، يجعلها غير متسقة وذاتية.
3. تفاصيل الأحداث الدقيقة والهيكل، ضائعة بشكل دائم في الطريق.
يحل BEAT كلتا المشكلتين في نفس الوقت. عندما أقرأ BEAT، لم أعد بحاجة لترجمة، لأن:
1. إنه دلالي: يحمل المعنى بشكل طبيعي، مثل اللغة.
2. إنه بيانات أولية: دون تدخل ولم تُمَس في المصدر.
3. إنه تنسيق: منظم باستمرار بحيث يمكن فهمه مباشرة.
هذا يسمح لي بفهم معنى بيانات الأحداث الأولية فوراً، دون الحاجة لأي خطوط أنابيب. بهذا المعنى، BEAT هو فعلياً نوع جديد من تنسيق البيانات المصمم للتفسير المباشر بواسطة الذكاء الاصطناعي.
يمكن كتابة هذا كما يلي.
state = f(time) // تقليدي
decision flow = f(time, intention, hesitation, resolution) // BEAT
لذلك، لا يُمكّن BEAT فقط النماذج التي تتنبأ بالنتائج. إنه يُمكّن الذكاء الاصطناعي من إعادة إنتاج تدفق القرار الكامن وراء السلوك البشري."
Full Score هو مشروع شخصي بواسطة Aidgn. أعمل بشكل رئيسي كمستشار UX، لذا عملي التطويري مرتبط بشكل طبيعي بتجربة المستخدم.
كمشروع تالٍ بعد Full Score، أبحث حالياً في مقاربة عرض جديدة تُسمى FFR (Full-Cache Fragment Rendering). إذا كان SRF يهدف لإزالة خط أنابيب البيانات، فإن FFR يهدف لإزالة خط أنابيب العرض.
إذا كنت ترغب في التواصل، لا تتردد في التواصل عبر البريد الإلكتروني أو DM على X. شكراً.